今天用產銷履歷與有機蔬果行情資料來做練習。
https://data.gov.tw/dataset/126472
filter的功用是用分組後的dataframe做條件篩選。
符合條件的原始列會被保留,最後回傳被保留的原始列的子集合 (dataframe)
df.groupby(column_name).filter( function | lambda)
以下程式碼就是將df以市場及作物代號分組後,只保留交易量總額大於1000的data
#可以用lambda
filtered = df.groupby("作物代號").filter(
lambda g: g["交易量_公斤"].sum() > 1000)
#或是寫一個function
def filter_func(g):
return g["交易量_公斤"].sum() > 1000
filtered = df.groupby("作物代號").filter(filter_func)
filter回傳的是一個dataframe,不再是groupby object。
所以不能在後面接agg或transform之類的函數。
df.groupby(column_name).transform(aggregate function | function | lambda)
一般的應用是新增一個欄位,把分組運算後的結果廣播到這個分組index的每個列上。
和agg()不同,agg做完列數會因為分組被壓縮,但transform原始列有幾列結果也會有幾列。
什麼時候會用到它呢?
df["交易量平均"]= df.groupby("作物代號")["交易量_公斤"].transform("mean")
df["交易量百分比"]= df.groupby("作物代號")["交易量_公斤"].transform(lambda x: x/x.sum())
然後就會得到一個如下圖新增兩個欄位的df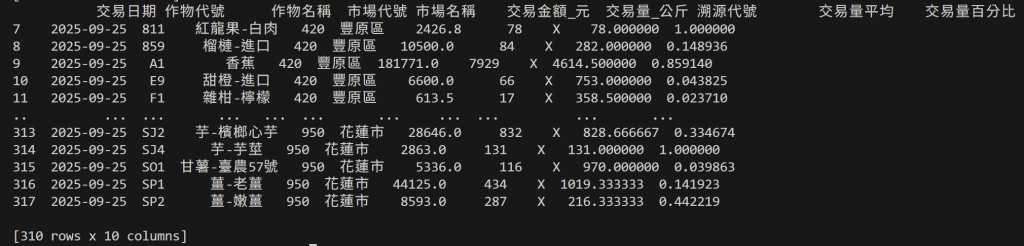
為了降低視覺干擾,我把作物代號rest過濾掉了。

