先來聊聊MultiIndex。
MultiIndex並非Groupby的特有功能,但是多欄的groupby結果容易比較直觀的理解它。
目前為止的實作,column和row index都是一維陣列。可是大家都有看過會計大神或業助大神們巧奪天工的excel吧,都是先by年再by季再by部門或客戶再by產品料號一堆條件,一維陣列很難滿足大家的需求。這時候就可以快樂的用multiindex了。
以昨天的例子來說,它在索引標籤和欄位名稱都有multi index。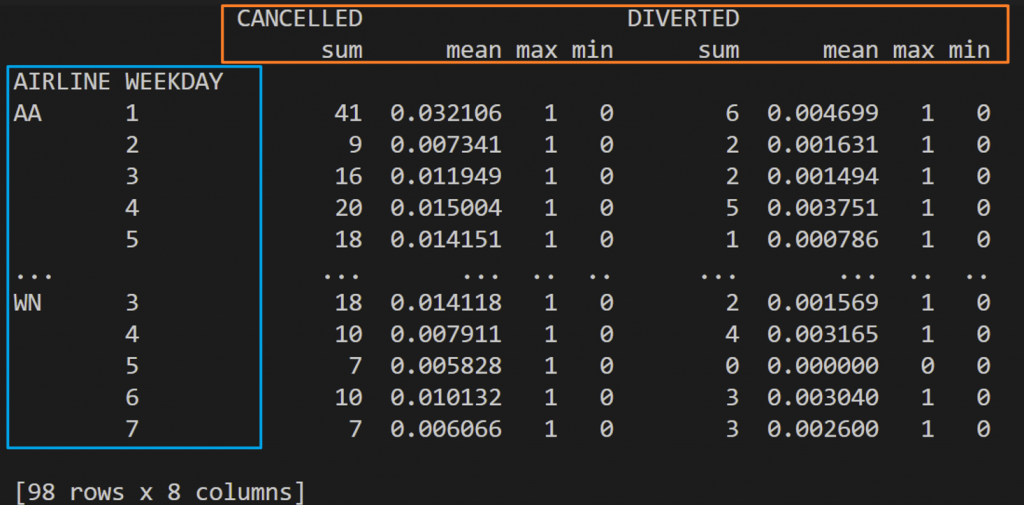
索引標籤:
欄位名稱:
可以用dataframe去檢視column和index
df = (flys.groupby(["LINE","WEEKDAY"])
.agg({"CANCELLED":["sum", "mean", "max", "min"],
"DIVERTED":["sum", "mean", "max", "min"]}))
#index
MultiIndex([('AA', 1),
('AA', 2),(中間省略)
('WN', 6),
('WN', 7)],
names=['LINE', 'WEEKDAY'])
#column
MultiIndex([('CANCELLED', 'sum'),
('CANCELLED', 'mean'),(中間省略)
( 'DIVERTED', 'max'),
( 'DIVERTED', 'min')],
)
它會回傳這樣兩個MultiIndex的物件。
雙層欄位跟雙層吉士堡一樣受歡迎,但user有些時候就是想要簡單一層的欄位,那就是扁平化的功用了。我們有兩個方法可以讓groupby後的資料呈現扁平化的結果。
flat_columns = df.columns.to_flat_index()df.columns = ['_'.join(x) for x in flat_columns]
sum_cancleed = pd.NamedAgg(column="CANCELLED", aggfunc="sum")sum_cancleed = ("CANCELLED", "sum")
直接上程式
#Case 1
fly_grouped = (flys.groupby(["LINE","WEEKDAY"])
.agg( {"CANCELLED":["sum", "mean", "max", "min"],
"DIVERTED":["sum", "mean", "max", "min"]}))
flat_columns = fly_grouped.columns.to_flat_index()
fly_grouped.columns = ['_'.join(x) for x in flat_columns]
#Case 2
flat_grouped = (flys.groupby(["LINE","WEEKDAY"])
.agg( sum_cancleed = ("CANCELLED", "sum"),
mean_cancleed = ("CANCELLED", "mean"),
max_cancleed = ("CANCELLED", "max"),
sum_diverted = ("DIVERTED", "sum"),
mean_diverted = ("DIVERTED", "mean"),
max_diverted = ("DIVERTED", "max")))
難道case1沒有更elegant的寫法嗎?一定要好幾個步驟嗎?有的,pipe用起來。
pipe就像馬利歐的水管一樣,蹲下去就進入別有洞天的關卡,刷一波新任務,但歸來仍是馬利歐那個少年。最棒的是它可以一關接一關、一管接一管。
有了pipe我們就可以繼續用method chaining, 維持程式碼的流暢與一致性。怎麼做呢?
用一個不帶參數的function說明當範例
def flatten_columns(df):
df.columns = ['_'.join(x) for x in df.columns.to_flat_index()]
return df
fly_grouped = (flys.groupby(["LINE","WEEKDAY"])
.agg({"CANCELLED":["sum", "mean", "max", "min"],
"DIVERTED":["sum", "mean", "max", "min"]})
.pipe(flatten_columns))
print(fly_grouped)
那有參數怎麼做呢?so ez。
改寫一下上面的程式。連接符不寫死在裡面,用參數傳進去。就會是這樣。
.pipe(flatten_columns)) 改成 .pipe(flatten_columns, "-"))
def flatten_columns(df, sep):
df.columns = [sep.join(x) for x in df.columns.to_flat_index()]
return df
fly_grouped = (flys.groupby(["LINE","WEEKDAY"])
.agg({ "CANCELLED":["sum", "mean", "max", "min"],
"DIVERTED":["sum", "mean", "max", "min"]})
.pipe(flatten_columns, "-"))
如果是 def set_target(df, usl, lsl):
就會是 .pipe(set_target, usl, lsl)
這裡雖然說的是pipe,但其實agg()也適用喔!
要是pandas提供的聚合函數滿足不了需求,就可以用 .agg(function_name)
或者是組合拳 .agg([function_name, 'mean', std'])
這取決於user想要多扁
#index only
flat_grouped = flat_grouped.reset_index()
#show the group column
flat_index = flat_grouped.index.to_flat_index()
flat_grouped.index = flat_index.map(lambda tup: "_".join(map(str, tup)))
user的需求總是變化多端,要是user又想看多層的資料怎麼辦呢?index的層級很容易增加,groupby column加下去就有了,但如果要新增三層以上column的層級就會需要一些手動加工。最原始的方式可以用 pd.MultiIndex.from_tuples([tuple陣列])
# 建立一個 DataFrame
df = pd.DataFrame({
"dept": ["A","A","B","B"],
"year": [2023,2023,2024,2024],
"sales_usd": [100,120,90,110],
"profit_usd": [30,40,25,35]
})
df["sales_ntd"] = df["sales_usd"] * 30
df["profit_ntd"] = df["profit_usd"] * 30
# 多層聚合:部門+年份
out = df.groupby(["dept", "year"]).agg(
sales_sum_usd=("sales_usd", "sum"),
sales_sum_ntd=("sales_ntd", "sum"),
sales_mean_usd=("sales_usd", "mean"),
sales_mean_ntd=("sales_usd", "mean"),
profit_sum_usd=("profit_usd", "sum"),
profit_sum_ntd=("profit_ntd", "sum"),
profit_mean_usd=("profit_usd", "mean"),
profit_mean_ntd=("profit_ntd", "mean")
)
# 把欄位 reshape 成 3 層 MultiIndex
out.columns = pd.MultiIndex.from_tuples([
("sales","sum","USD"),
("sales","sum","NTD"),
("sales","mean","USD"),
("sales","mean","NTD"),
("profit","sum","USD"),
("profit","sum","NTD"),
("profit","mean","USD"),
("profit","mean","NTD")
])
#Result--------------------------------->
sales profit
sum mean sum mean
USD NTD USD NTD USD NTD USD NTD
dept year
A 2023 220 6600 110.0 110.0 70 2100 35.0 1050.0
B 2024 200 6000 100.0 100.0 60 1800 30.0 900.0
明天來講filter和transform。

