昨天介紹了 Agent Card 的格式以及如何 Launch 一個 Agent Server(還沒真的接上 LLM),今天透過官方的範例來示範如何使用 Ollama 作爲 LLM backend 並且結合 a2a-sdk 來實作一個簡單的 Agent Server。
本次使用 a2aproject/a2a-samples 中的 LangGraph 範例來示範來操作如和使用 Ollama 作爲 LLM backend 並且結合 a2a-sdk 來實作一個簡單的 Agent Server。
git clone https://github.com/a2aproject/a2a-samples.git
cd a2a-samples/samples/python/agents/langgraph
uv sync
uv add langchain-ollama
app/
├── __init__.py
├── __main__.py # 主程式,啟動 A2A 伺服器
├── agent.py # 核心 AI Agent(使用 LangGraph)
├── agent_executor.py # Agent Executor,負責管理整個 Agent 的生命週期
└── test_client.py
agent.pyCurrencyAgent)self.model = ChatOllama(
model=os.getenv('TOOL_LLM_NAME'),
base_url=os.getenv('TOOL_LLM_URL'),
)
agent_executor.pyclass AgentExecutor(ABC):
"""Agent Executor interface.
Implementations of this interface contain the core logic of the agent,
executing tasks based on requests and publishing updates to an event queue.
"""
@abstractmethod
async def execute(
self, context: RequestContext, event_queue: EventQueue
) -> None:
"""Execute the agent's logic for a given request context.
The agent should read necessary information from the `context` and
publish `Task` or `Message` events, or `TaskStatusUpdateEvent` /
`TaskArtifactUpdateEvent` to the `event_queue`. This method should
return once the agent's execution for this request is complete or
yields control (e.g., enters an input-required state).
Args:
context: The request context containing the message, task ID, etc.
event_queue: The queue to publish events to.
"""
@abstractmethod
async def cancel(
self, context: RequestContext, event_queue: EventQueue
) -> None:
"""Request the agent to cancel an ongoing task.
The agent should attempt to stop the task identified by the task_id
in the context and publish a `TaskStatusUpdateEvent` with state
`TaskState.canceled` to the `event_queue`.
Args:
context: The request context containing the task ID to cancel.
event_queue: The queue to publish the cancellation status update to.
"""
execute 以及 cancel 方法 async def execute(
self,
context: RequestContext,
event_queue: EventQueue,
) -> None:
error = self._validate_request(context)
if error:
raise ServerError(error=InvalidParamsError())
query = context.get_user_input()
task = context.current_task
if not task:
task = new_task(context.message) # ⭐ (1) 建立一個新的 Task
await event_queue.enqueue_event(task) # ⭐ (2) 發布到事件佇列
updater = TaskUpdater(event_queue, task.id, task.context_id) # ⭐ (3) 建立一個 TaskUpdater 來更新 Task 狀態
try:
# ⭐ (4) 處理過程中會持續的 stream response
async for item in self.agent.stream(query, task.context_id):
is_task_complete = item['is_task_complete']
require_user_input = item['require_user_input']
if not is_task_complete and not require_user_input:
await updater.update_status(
TaskState.working,
new_agent_text_message(
item['content'],
task.context_id,
task.id,
),
)
elif require_user_input:
await updater.update_status(
TaskState.input_required,
new_agent_text_message(
item['content'],
task.context_id,
task.id,
),
final=True,
)
break
else:
await updater.add_artifact(
[Part(root=TextPart(text=item['content']))],
name='conversion_result',
)
await updater.complete()
break
except Exception as e:
logger.error(f'An error occurred while streaming the response: {e}')
raise ServerError(error=InternalError()) from e
if not os.getenv('GOOGLE_API_KEY'):
raise MissingAPIKeyError(
'GOOGLE_API_KEY environment variable not set.'
)
model_source 爲 ollama
TOOL_LLM_URL 爲 http://localhost:11434
TOOL_LLM_NAME 成 model name,例如 llama3.2:3b
# .env
model_source=ollama
API_KEY=your_api_key_here
TOOL_LLM_URL=http://localhost:11434
TOOL_LLM_NAME=llama3.2:3b
uv run app
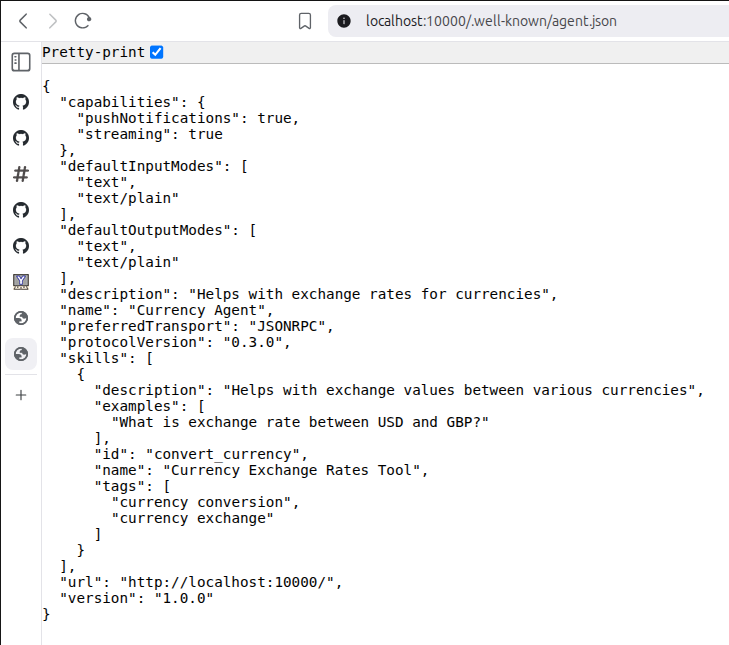
可以在 http://localhost:10000/.well-known/agent.json 看到 Agent Card
# 測試 ollama API
curl -X POST http://localhost:11434/api/chat \
-H "Content-Type: application/json" \
-d '{
"model": "llama3.2:3b",
"messages": [
{
"role": "user",
"content": "Hello"
}
]
}'
test_client.py 來測試uv run app/test_client.py
a2a-sdk 來實作一個簡單的 Agent Server
