實作 MCP Server 有點挫折,但經過一番努力振作後,因為希望可以實作一個 AI 相關的小應用,所以轉往研究 LLM API,那這篇主要是初步介紹我對於模型的認識,以及從前端須要考量的面向去探討模型的差異性

Openai 目前提供幾個大類別的模型API,讓開發者根據情境需求選擇
由於目前沒有自架推理服務、即時語音等需求,因此閱讀的順序是:
Frontier models > Specialized models
這邊我以前端身份,初步列出了幾項選擇模型上的考量:
先假想以下情境:
那以目前的模型來說,可以考慮的有哪些?
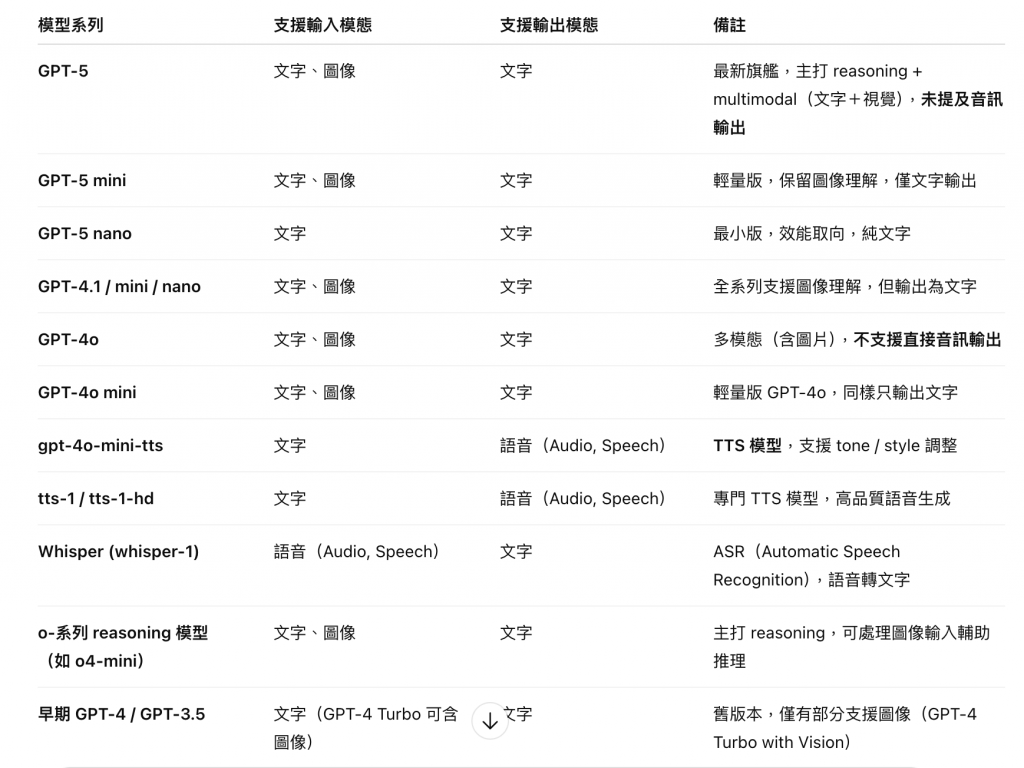
本表由 GPT 協助整理而成
結論:很意外地發現上述三個情境無法直接被模型處理,我理解是都需要額外搭配工具去協助處理,但每個模型可支援的工具也都不同,這部分留到下一篇詳細討論。
這邊我是參考模型文件中 Speed 以及 Reasoning 欄位去評比

本表由 GPT 協助整理而成
結論:原則上較高的回覆速度,回覆品質通常差一點,反之也通,因此就看使用者看中哪個因素較多。
在 D2 的文章有介紹過 Context Window 的概念,所以這邊就不多做贅述,我們直接看結果
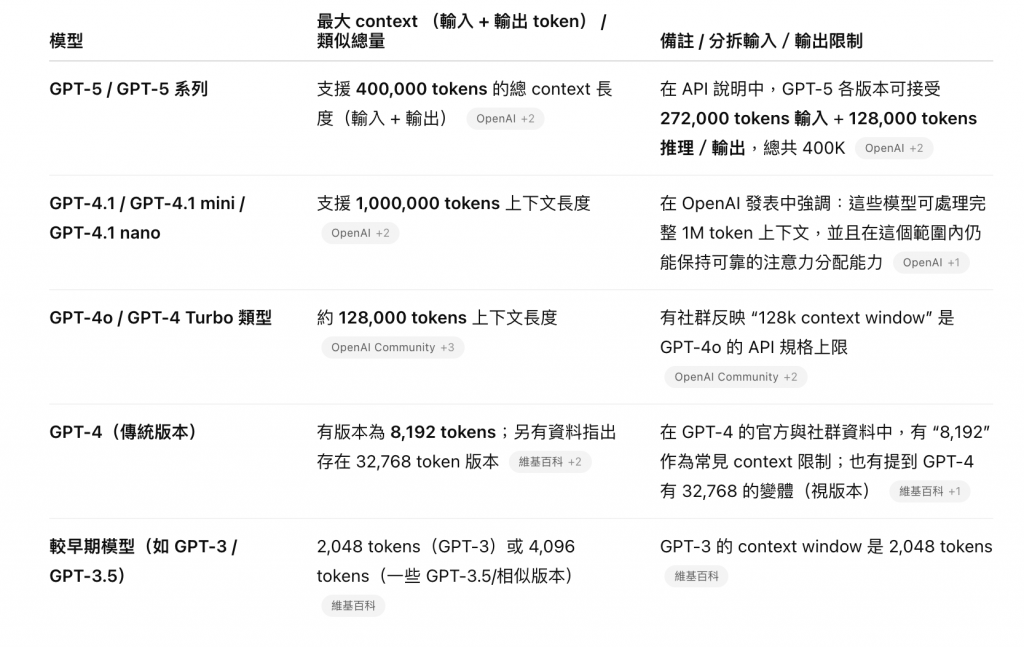
本表由 GPT 協助整理而成
結論:越新的模型 Context Window 越大,所以在可接受的成本開銷下,應該優先選擇使用最新的模型。
在下一篇目標是開始研究模型的支援工具以及 Token 費用的計算等,老實說這部分最初在發想階段時,想像的是要比較 Claude, Gemini, GPT 的方法、工具,但是真的開始研究發現光一個就很夠讀了。
那麼,明天見。
-- to be continued --


 iThome鐵人賽
iThome鐵人賽