上一篇初步了解了模型的類型後,以前端考量去評比,在這一篇要進一步認識模型的工具,畢竟都上車了 ..

下圖是官方提供給模型的工具,這邊最簡要的重點就是 使用前記得確認工具是否支援模型,這邊只舉最通用的概念:
下面主要會針對有興趣的工具去進一步認識,搭配簡單舉實例測試
圖片來源:https://platform.openai.com/docs/guides/tools
Context Window:128000
概念:用途是允許模型讀取使用者提供的網址內容,最直覺的使用情境就是 彌補模型的知識限制影響回答品質
因為模型的知識會受限,以 GPT-5 來說它所知只到 2024 年 9月 30 日前的事情,因此超過日期的知識、消息,則需要以 Web Search 讀取理解。
語法架構
import OpenAI from "openai";
const client = new OpenAI();
//基本的提問架構
const response = await client.responses.create({
model: "gpt-5",
//加入工具
tools: [
{ type: "web_search" },
],
//使用者的 prompt
input: "What was a positive news story from today?",
});
console.log(response.output_text);
以陣列格式添加指定的 Domain ,可添加的數量上限為 20 個,其用途是 限制模型只能在這些 Domain 資源下進行查詢,特別注意:
allowed_domains:['cake.me.tw'] //O
allowed_domains:['https://cake.me.tw'] //x
舉一個實際案例:假設我今天請模型幫忙查詢前端 vue 的職缺,分別以兩種方式查詢:
import OpenAI from "openai";
const client = new OpenAI();
//基本的提問架構
const response = await client.responses.create({
model: "gpt-5",
tools: [
{ type: "web_search",
filters:{
allowed_domains:['104.com.tw','cake.me']
},
},
],
input: "請幫我查詢前端 vue 的職缺",
});
console.log(response.output_text);
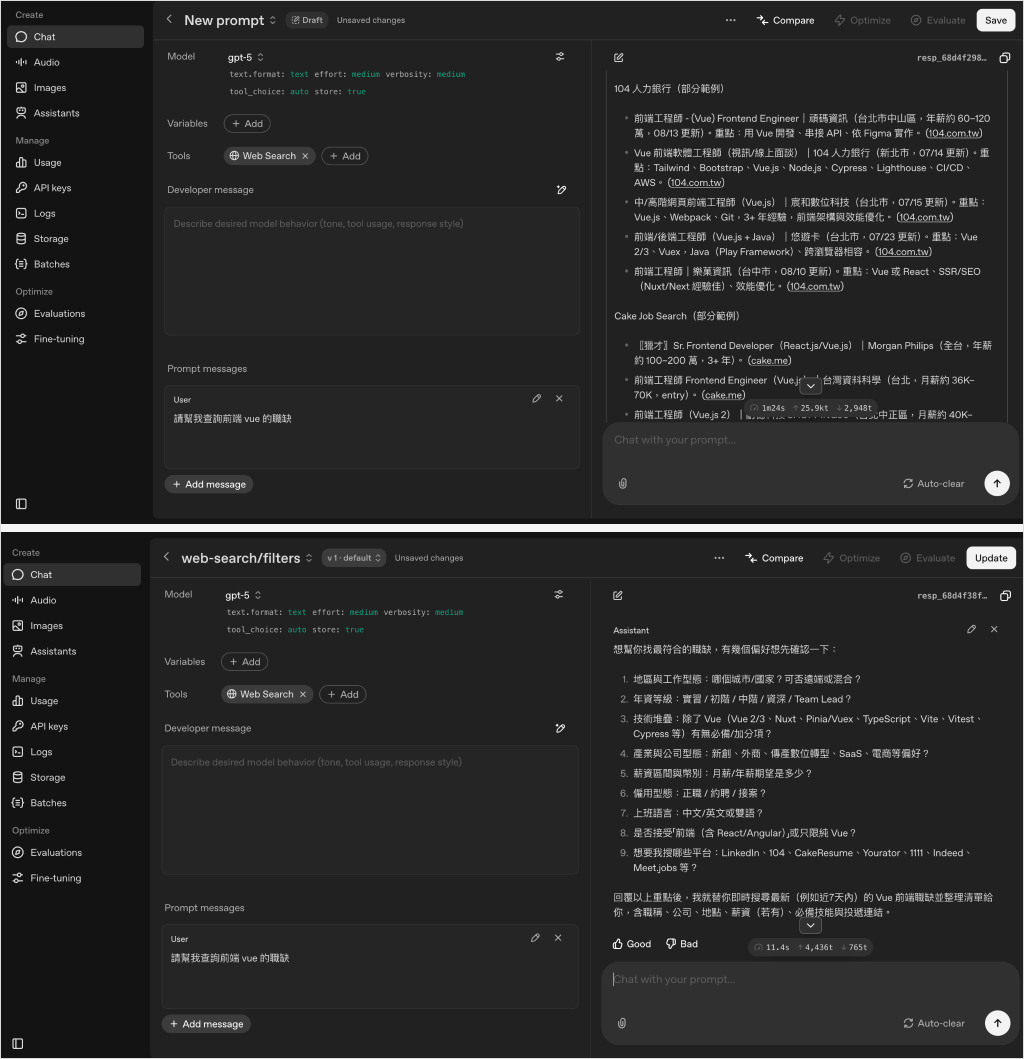
這邊使用 Openai Playground 進行測試,結果如下:
Domain 限制搜尋 (上圖) / 無篩選搜尋(下圖)
Token 消耗: 28,847 / Token 消耗:210,906
即便可能受使用者 prompt 技巧影響結果,但是耗費差距還是非常驚人。
除了指定 Domain 外,它也有提供區域的定位方法,讓搜尋更貼近使用者期待。
語法
user_location:{
country:'',
city:'',
region:''
}
country:使用的是 ISO country code,以台灣為例就是 TWcity:這個就不用特別說了,就是城市英文timezone:設定時區
除了讚嘆 API 跟方法都封裝得簡易好讀外,適當使用工具配置,也是節省 Token 重要的方式之一,在下一篇我們要接著研究另一個好用的模型工具 file search
那麼,明天見
-- to be continued --
OpenAI Web Search API
Web Search


 iThome鐵人賽
iThome鐵人賽