前一篇研究了 web search 之後,因為後續想實做的 AI 小專案會用到上傳檔案功能,因此也來研究 file search 這個工具,在這一篇我主要會介紹:

是模型工具之一,顧名思義能解讀使用者上傳的檔案內容,基本的語法如下:
import OpenAI from "openai";
const openai = new OpenAI();
const response = await openai.responses.create({
model: "gpt-4.1",
input: "What is deep research by OpenAI?",
tools: [
{
type: "file_search",
},
],
});
console.log(response);
研究了 file search 的文件後,自己會用以下情境幫助讀者快速釐清是否需要更細讀文件內容
你是否需要基於上傳檔案內容製作檢索功能(RAG)?或是僅需要單次解讀這份檔案
如果你的功能情境是屬於前者,那恭喜,你很適合認真研究 retrieval 這個功能,並往下閱讀內容,反之可以跳過本篇文章。
最簡單來說 retrieval 是優化檔案搜尋的方法,先用語意搜尋從你的向量庫取回最相關片段,再把這些片段餵給模型生成更準確、可溯源的答案。
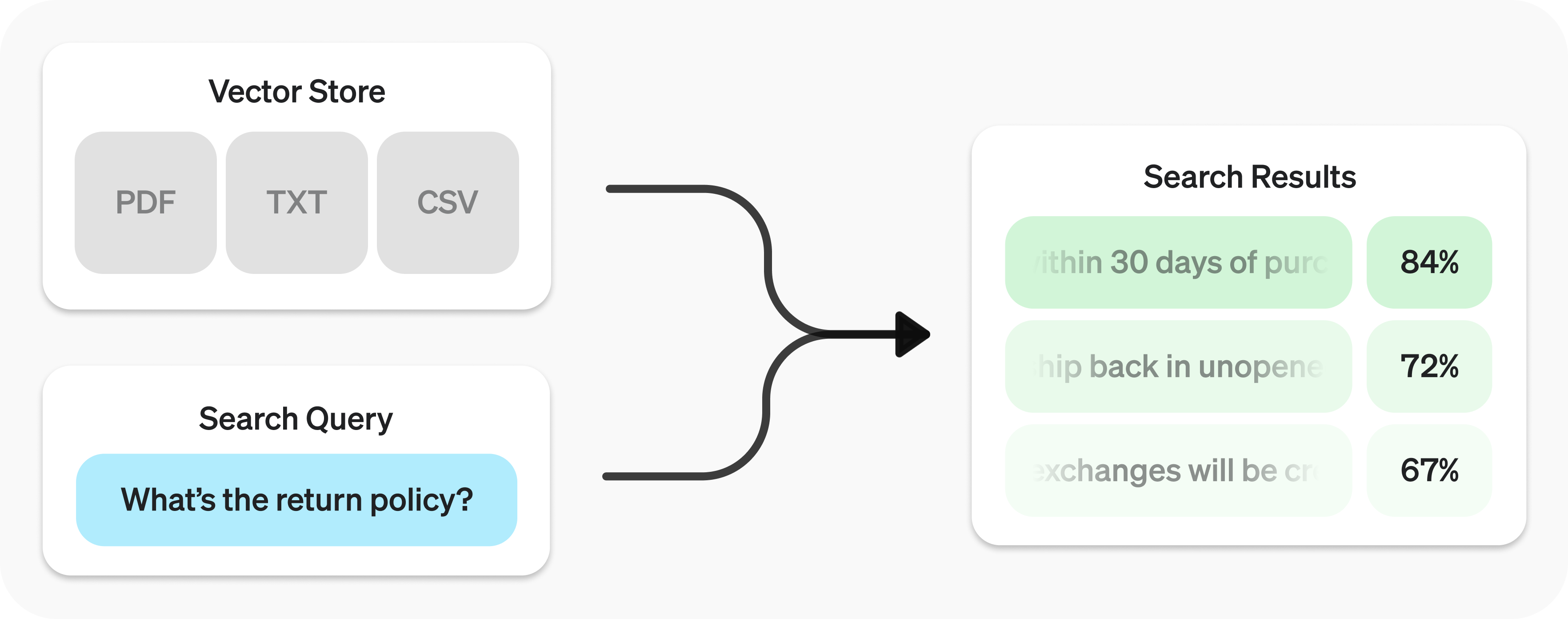
圖片來源:https://platform.openai.com/docs/guides/retrieval
那從背後解析,首先工具會自動解析與切塊 上傳檔案、建立嵌入並存到向量庫,當使用者後續進行提問時,會以向量+關鍵字混合檢索取得相關片段,然後生成回答,這樣做法的好處是:
透過官方提供方法建立
import OpenAI from "openai";
const client = new OpenAI();
const vector_store = await client.vectorStores.create({
//向量庫名稱
name: "Support FAQ",
});
什麼是語意化搜尋? 同樣以官方提供的範例,假設你今天輸入的查詢字是:
"When did we go to the moon?"
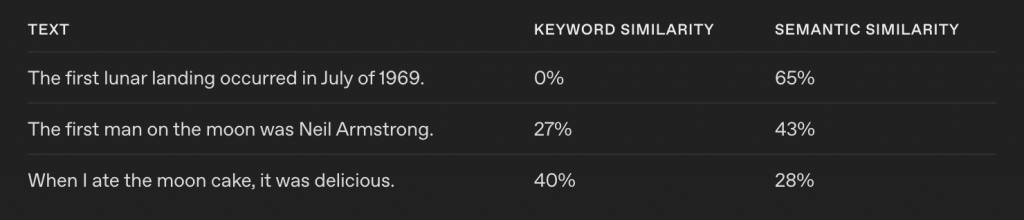
比較 關鍵字相似度 及 語意相似度 對內容的偵測方式,舉例來說:
當掃描到檔案內容是:"moon cake"
關鍵字相似度:因為這句含有 moon,因此關鍵字相似度 40%,但其實這和登月無關。
語意相似度:用嵌入模型(例:text-embedding-3-small)把句子轉成向量,再用餘弦相似度量測語意距離。(提供 By GPT)
那在使用上,官方也有提供方法
const results = await client.vectorStores.search({
// 向量庫識別碼
vector_store_id: vector_store.id,
// 語意化參數
query: "How many woodchucks are allowed per passenger?",
});
學會基本的向量庫的建立及語意搜尋的方法後,更新查詢流程為:
研究了之後,初步知道了 如何查詢檔案比較省 token 並兼顧精確性,但應該要帶入更多前端的視角,畢竟我本質是前端工程師,下一篇反省!轉往 token 節省工具去!
那麼,明天見
-- to be continued --


 iThome鐵人賽
iThome鐵人賽