在過去開發的過程中,不知道你有沒有以下的這些經驗:
情境一: 針對某個功能跟 GPT 討論,該給的情境、需求都說完了,也糾正它的回覆好幾次,發現它像是不接受你的回饋,一直鬼打牆要你用它的方法。
情境二: 複製貼上大量的程式碼請它分析,發現它的回覆不夠完整,不是漏掉元件中其實有 import 、就是漏掉中間的 function 內容
那為什麼會發生這些事情呢?

但因為我好奇為什麼會這樣,所以試著在本篇進行初步的探索
假設你今天在跟朋友聊 JOJO 的話題,中間你一句我一句,這過程的聊天內容對 LLM 來說,則被稱為 context ,LLM 跟人一樣會記住聊天內容 (context) 來進行回覆(如下圖)。

圖片來源:anthropic 官方文件
而圖中所謂的 Context window ,它代表的是 LLM 的記憶空間大小,其單位是 token。
你可以想像在跟朋友聊了好幾個小時後,你是不是會開始忘記剛見面聊天內容的細節,同理套用隨著 context 到達上限時,LLM 也會開始忘記一些對話細節。
不同模型的記憶上限都不同,這邊以平台使用舉例:
Plus 方案的 GPT5 可記憶的 context 上限約為 196k
Claude Sonnet 4 在 Beta 環境下可用 100 萬 token 的長上下文(超過 200K 會套用長上下文計價)。
當然,為了彌補模型本身的極限,不同應用都有各自的策略,盡力減輕這個問題帶來的影響,實作細節在這邊就不做太多的討論。
你有沒有幹過這樣的事情:
接下 jira 單後,找到了任務相關的元件檔案,因為想加速對元件內容的理解,就直接把整個元件內容丟給 LLM 解讀

如果你發現它對一些功能細節的理解有所疏漏,你可以大膽的懷疑 肯定是中間的內容被疏漏了。
這個現象被稱為 Lost in the middle,是在學術測試中被觀察到的:
當你把內容移到中間,準確率會顯著下降;放在開頭或結尾則較高
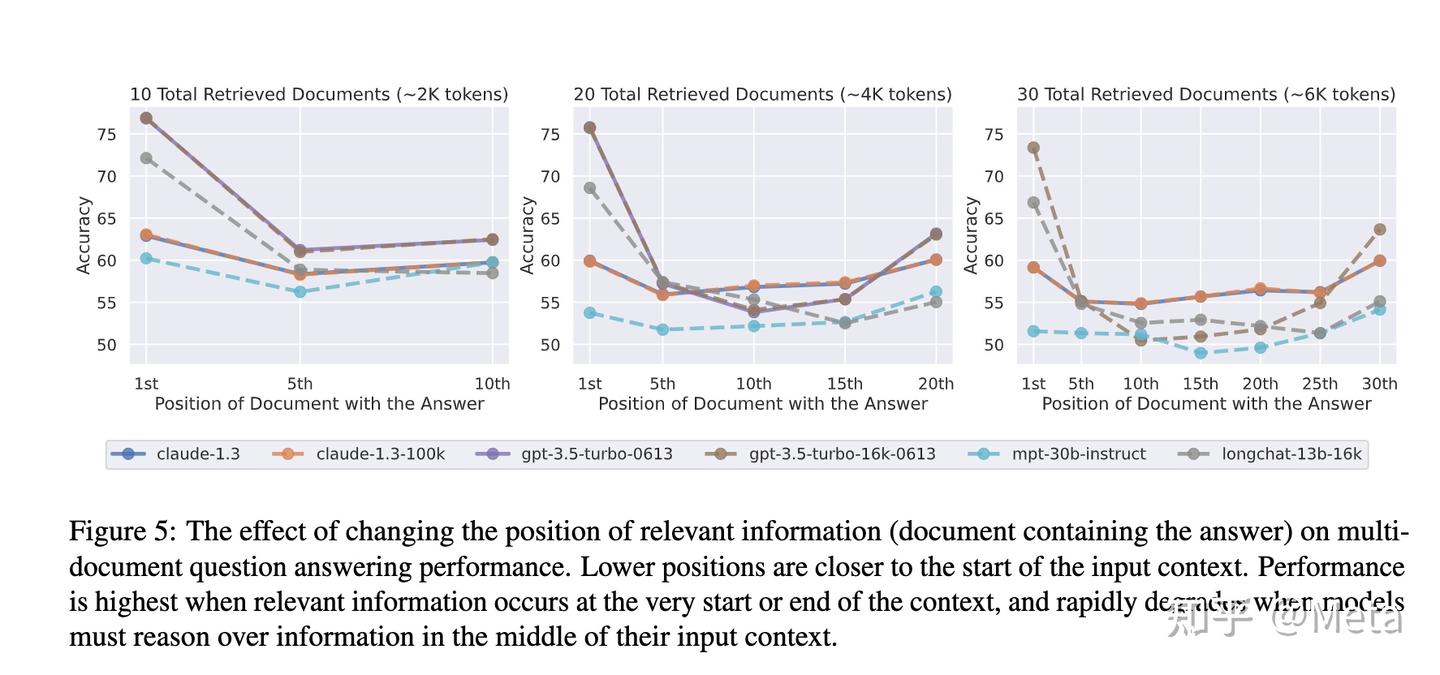
圖片來源:https://zhuanlan.zhihu.com/p/678614880
模型雖然「看得到」所有的 Prompt ,但在實務上會偏重開頭與結尾;中間的資訊較容易被忽略。
小提醒:這個學術測試發表於 2023 ,當時測試的 LLM 為 GPT-3.5-Turbo、Claude-1.3
在本篇我以自己開發經驗為發想,專注在解析現象與問題。
在下一篇將把重點對焦回 如何處理、改善,試著舉一些實際開發的案例輔助說明
那麼,明天見。
-- to be continued --


 iThome鐵人賽
iThome鐵人賽