
題目連結:https://rosalind.info/problems/hamm/
今天文章比較長,要冷靜 忍耐一下
(文末有提到zip()與asterisk星號用法,篇幅hen長)
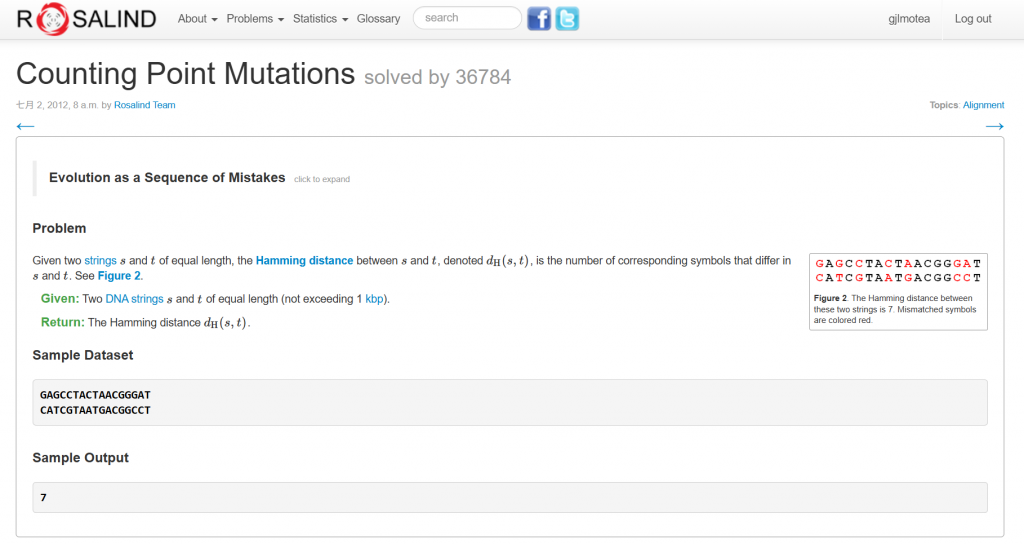
輸入兩基因序列,比對這兩序列中有幾個不一樣的地方。
計算兩字串不同字符的個數,這個就稱為漢明距離 (Hamming distance)
11110000
01110001
上述範例經過逐位比較後,得到漢明距離為2
代表需要兩個步驟(單一位元的替換)才能讓兩字串相同
順帶一提,漢明距離 與 漢明碼 有關聯
漢明碼(Hamming Code)是最早的一種 系統糾錯碼/錯誤更正碼(ECC, error-correcting code)
引入”檢查位元(Parity bits)“,可以發現並修正一個錯誤,常用在封包傳輸
輸入
GAGCCTACTAACGGGAT
CATCGTAATGACGGCCT
輸出
7
程式碼
data = \
"""
GAGCCTACTAACGGGAT
CATCGTAATGACGGCCT
"""
lines = data.splitlines()
lines = [line.strip() for line in lines if line.strip()]
count = 0
for i in range(len(lines[0])):
if lines[0][i] != lines[-1][i]:
count += 1
print(count)
函式寫法
def hamming_distance(s: str, t: str) -> int:
total = 0
zipped = zip(s, t)
for a, b in zipped:
if a != b:
total += 1
return total
# return sum(1 for a, b in zip(s, t) if a != b) # 這個函式可改成精簡的單行寫法
# 手動將資料拆分兩序列
source = "GAGCCTACTAACGGGAT"
target = "CATCGTAATGACGGCCT"
print(hamming_distance(source, target))
在過濾資料(剔除空字串、空物件)時,
不建議在叠代陣列(集合)的同時,對陣列本身進行新增/刪除
因為這會改變原先長度和索引順序,出現意料之外的結果
ex: 刪除陣列中的元素時,陣列會「變短」,然而for迴圈的索引卻「照原本的長度走」
items = ["a", "", "b", "", "c"]
for item in items:
if not item:
items.remove(item) # 不要這樣做!別在迴圈中修改列表,會造成執行順序錯亂(跳過元素)
print("錯誤寫法 例1:", items) # ["a", "b", "c"]
items = ["a", "", "b", "", "", "c"]
for item in items:
if not item:
items.remove(item)
print("錯誤寫法 例2:", items) # ["a", "b", "", "c"]
使用新的陣列來儲存所需要的資料
items = ["a", "", "b", "", "", "c"]
new_items = []
for item in items:
if item: # 只留下真值(篩掉所有falsy值 ex:"", 0, None, False)
new_items.append(item)
print("正確寫法(迴圈版):", new_items) # ['a', 'b', 'c']
items = ["a", "", "b", "", "", "c"]
items = [
item
for item in items
if item
]
# items = [item for item in items if item] # 單行寫法(List Comprehension)
print("正確寫法(精簡版):", items) # ['a', 'b', 'c']
另外,if item/if not item是判斷 truthy/falsy value
包含:空字串""、整數0、浮點數0.0、布林值False、空值None、空容器[]{}()
而 if (item != "") 則只有過濾空字串""
zip具有拉鍊、打包、壓縮的意思,可將多個元素配對,打包成一個元組
# ==== 範例1 ====
zipped = zip([1, 2, 3], ['a', 'b', 'c'])
print("範例1:", zipped) # <zip object at 0x12bc43a00> 直接輸出是物件位址
print("範例1:", list(zipped)) # [(1, 'a'), (2, 'b'), (3, 'c')]
print("範例1:", list(zipped)) # [] => 空了
# ==== 範例2 ====
student = ['小明', '小華', '小美', '小夫']
score = [85, 92, 78, 88]
subject = ['數學', '數學', '數學', '數學']
class_gradebook = zip(student, score, subject)
# [('小明', 85, '數學'), ('小美', 92, '數學'), ('阿強', 78, '數學'), ('阿珍', 88, '數學')]
for student, score, subject in class_gradebook:
print("範例2:", student, score, subject)
# 小明 85 數學
# 小美 92 數學
# 阿強 78 數學
# 阿珍 88 數學
但是在運用zip()時,也要小心使用陷阱
# ==== 陷阱1 ====
zipped = zip([1, 2, 3], ['a', 'b', 'c'])
print("陷阱1:", zipped) # <zip object at 0x12bc43a00> 直接輸出是物件位址
print("陷阱1:", list(zipped)) # [(1, 'a'), (2, 'b'), (3, 'c')]
print("陷阱1:", list(zipped)) # [] => 空了
# ==== 陷阱2 ====
zipped = zip([1, 2, 3], ['a', 'b', 'c'])
list(zipped)
print("陷阱2:", list(zipped)) # [] => 直接空了
z = list(zipped) # 要用變數將zip叠代結果存起來,才有辦法重複使用
# ==== 陷阱3 ====
# 長度不一致時,zip 會自動對齊最短長度
# 超出部分會被忽略,而不會報錯
zipped = zip([1, 2, 3], ['a', 'b', 'c', 'd']) # 因長度不匹配,'d'會被丟掉
print("陷阱3:", list(zipped)) # [(1, 'a'), (2, 'b'), (3, 'c')]
zip()是一種懶惰叠代器(Lazy Iterator),是只能走過一遍的叠代器(一次性消耗品)
里面的東西(資料流)只能倒出來一次,用一次就沒了,再用就是空的。除非額外使用變數將「倒出結果」儲存起來。
相同類型的iterator還有:map(), filter(), enumerate(), open(), iter()
因為zipped過後,內容已經被分為「欄列」可以視作一張「表(Table)」了
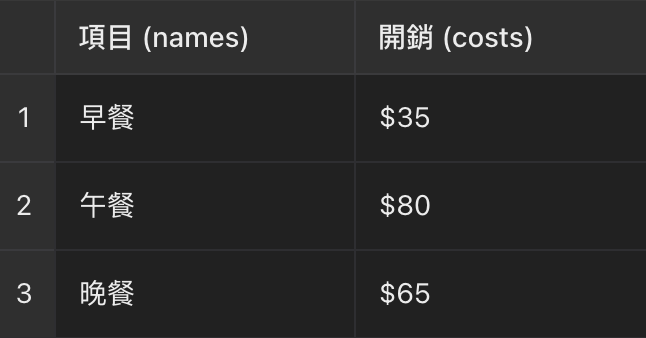
所以拆解zip包的方式,自然分成兩種:橫向拆分 vs 直的解開
兩種方式「變數的數量」都要正確
names = ['早餐', '午餐', '晚餐']
costs = ['$35', '$80', '$65']
zipped = list(zip(names, costs)) # 由3個tuple組成的list
print("記錄:", zipped) # [('早餐', '$35'), ('午餐', '$80'), ('晚餐', '$65')]
# 拆解方式1:拆包 多變數賦值/序列解包
record_1, record_2, record_3 = zipped
print(record_1, record_2, record_3) # ('早餐', '$35') ('午餐', '$80') ('晚餐', '$65')
# 拆解方式2:解包 轉置解包/參數解包
names, costs = zip(*zipped)
print(names, costs) # ('早餐', '午餐', '晚餐') ('$35', '$80', '$65')
print("項目:", names) # ('早餐', '午餐', '晚餐')
print("開銷:", costs) # ('$35', '$80', '$65')
在Python中,偶爾會看到*與**的用法
簡單來說,這兩者代表的是 一個元組/陣列/字典里面的剩餘元素
單星號*(asterisk, single star):
打包/解包 可叠代物件 unpack iterable(list/tuple)
處理的是位置參數(positional arguments),按照位置順序解析
雙星號**(double asterisk, double star):
打包/解包 字典 unpack dictionary(key/value)
處理的是具名參數(keyword arguments),按照參數名稱解析
兩者都可以做打包、解包,啥意思?
先來看解包的例子:
# ==== single star ====
args = (1, 2, 3, 4)
print(*args) # 解開成 1 2 3 4
list1 = [1, 2, 3]
list2 = [4, 5]
combined = [*list1, *list2] # 解開陣列,存入新陣列中
print(combined) # [1, 2, 3, 4, 5]
zipped = [('早餐', '$35'), ('午餐', '$80'), ('晚餐', '$65')]
record_1, *others = zipped # 把右邊拆開放到左邊
print(record_1) # ('早餐', '$35')
print(others) # [('午餐', '$80'), ('晚餐', '$65')]
# ==== double star ====
dict1 = {"a": 1, "b": 2}
dict2 = {"c": 3}
merged = {**dict1, **dict2} # 解開字典,存入新字典中
print(merged) # {'a': 1, 'b': 2, 'c': 3}
再來看打包(收集、組裝)的例子:
# ==== single star ====
def add_all(*args): # 收參數(打包),把傳進來的位置參數放進tuple中
print(*args) # 1 2 3 4 => 解參數、解包後的樣子
print(args) # (1, 2, 3, 4) => 未解包的模樣
print(args[0]) # 1
return sum(args)
total = add_all(1, 2, 3, 4)
print(total) # 10
# ==== double star ====
def parse_data(**kwargs): # 允許無限制數量的關鍵字參數
for name, cost in kwargs.items():
print(name, cost)
record = {'早餐': '$35', '午餐': '$80'}
parse_data(**record)
# 早餐 $35
# 午餐 $80
parse_data(午餐='$50', 晚餐='$30', 宵夜='$250') # 支援跟鬼一樣的用法
# 午餐 $50
# 晚餐 $30
# 宵夜 $250
最後是
強制使用具名參數/位置參數
# 一般寫法
def record_item(item: str, cost: str):
print(item, cost)
record_item("早餐", "$10") # 位置參數,按照順序填
record_item(item="午餐", cost="$120") # 具名參數,指定關鍵字
# 強制使用具名參數 => 在*右側的參數,只能用具名參數(keyword)
def record_item_k1(*, item: str, cost: str):
print(item, cost)
# record_item_k1("早餐", "$10") => 會出錯,不能用"位置參數"
record_item_k1(item="午餐", cost="$120")
def record_item_k2(item: str, *, cost: str): # *在中間 => 只有*右側的cost需要使用具名參數
print(item, cost)
record_item_k2(item="午餐", cost="$120")
record_item_k2("晚餐", cost="$250") # 這行可運作
# 強制使用位置參數 => 在/左側的參數,只能用位置參數(positional)
def record_item_p1(item: str, cost: str, /):
print(item, cost)
# record_item_p1(item="午餐", cost="$120") # 會出錯,不能用"具名參數"
record_item_p1("晚餐", "$250") # 這行可運作
# 兩者混用mix(強制具名、強制位置)
# 若兩同時存在,/必須出現在*前面
def record_item_m1(item: str, /, cost: str, *, notes: str):
print(item, cost)
record_item_m1("蹦迪", "$1000", notes="好貴")
# def record_item_m2(item: str, *, cost: str, /): # 這行會報錯 SyntaxError: / must be ahead of *
# print(item, cost)
最終的大雜燴
打包/解包 搭配 強制使用具名參數/位置參數
# item, cost 只能用位置參數。剩下傳入的位置參數都會被*extra收集起成tuple
def record_1(item, cost, /, *extra):
print(item, cost, extra) # 早餐 $50 ('便利商店', '一杯咖啡、兩顆茶葉蛋')
print(*extra) # 早餐 $50 ('便利商店', '一杯咖啡、兩顆茶葉蛋')
record_1("早餐", "$50", "便利商店", "一杯咖啡、兩顆茶葉蛋")
# item, cost 只能用具名參數。剩下傳入的具名參數都會被**extra收集成dict
def record_2(*, item, cost, **extra):
print(item, cost, extra) # 晚餐 $120 {'地點': '火鍋店', '備註': '原味健康火鍋'}
print(*extra) # 地點 備註 => 印出key
# print(**extra) # 會報錯 => print()不支援印出具名參數
record_2(item="晚餐", cost="$120", 地點="火鍋店", 備註="原味健康火鍋")
