在前一篇文章中,我們探討了如何實現人機協作功能,其中 Checkpointer 扮演了關鍵角色,讓流程在中斷後能夠順利恢復。換句話說,它提供了一種 短期記憶 功能,可以記錄 AI 執行到哪個步驟,以及當下的狀態資訊。這樣的設計避免了每次中斷都必須從零開始執行,使系統運作更貼近實際應用需求。
不過,如果我們希望 AI Agent 不僅能暫停與恢復,還能在更長期的使用過程中保留經驗與上下文,就需要進一步的 長期記憶 機制。今天,我們將探討如何透過 Checkpointer 與 Store,讓 AI Agent 不只具備單次流程的記憶能力,還能跨任務、跨對話持續保存並回顧上下文,打造更智慧、可持續學習的 AI 系統。
當我們談到 AI Agent 的「記憶」,並不是指它能像人類一樣擁有情感或主觀經驗,而是指在運行過程中保留與管理資訊的能力。這些資訊可能包含目前的任務狀態、對話的上下文、過去的決策結果,甚至是跨任務累積下來的知識。
有了記憶,AI Agent 不需要在每次執行時都從零開始。它能在不同情境下發揮作用:
因此,記憶對 AI Agent 而言,不僅是一種提升效率的機制,更是讓系統具備連續性與智慧性的基礎。沒有記憶的 Agent,只能處理單次的輸入與輸出;而有了記憶,它才能真正承載更長期的任務,並在多次互動中展現出更符合人類期待的行為。
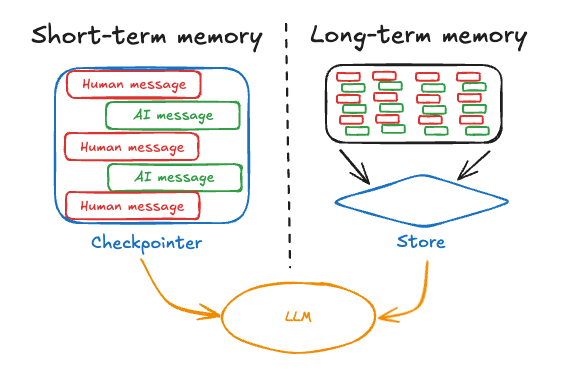
在設計 AI Agent 的記憶機制時,我們通常會依存續時間與用途區分為 短期記憶(Short-term Memory) 與 長期記憶(Long-term Memory)。這兩者並非互相取代,而是各自負責不同的任務,彼此互補:
圖片來源:LangChain Blog
以下表格整理了兩者的差異:
| 特性 | 短期記憶 | 長期記憶 |
|---|---|---|
| 作用範圍 | 單一對話流程(thread) | 跨多個對話流程、跨 Session 或使用者 |
| 實作方式 | Checkpointer | Store |
| 存取方式 | 依靠 Thread ID 維護對話狀態 | 依靠 namespace 與 key 查詢 |
| 使用場景 | 對話上下文、當前任務進度、工具呼叫結果 | 使用者偏好、長期知識、跨任務狀態 |
| 設計目標 | 保持「連續性」 | 支援「持久性」與「個人化」 |
簡單來說,短期記憶讓 Agent 在「當下」能理解上下文,而長期記憶則讓 Agent 在「未來」也能記住你。接下來,我們將說明如何在 LangGraph 中透過 Checkpointer 與 Store,來實際實現這兩種記憶機制。
短期記憶(Short-term Memory) 能讓 Agent 在同一個任務或對話中記住上下文。例如在多輪對話中,Agent 需要記住使用者的提問脈絡,才能在下一次回應時保持一致,而不是把每次輸入都當成全新的對話。
舉例來說,如果使用者先問「台灣最高的山是什麼?」接著又問「那日本呢?」——有了短期記憶,Agent 就能理解第二個問題是在延續「最高的山」這個主題,而不是完全新的提問。
在 LangGraph 中,短期記憶透過 Checkpointer 來實作的,主要依賴兩個關鍵要素:
checkpointer,用來保存 Agent 的執行狀態。這些狀態可能包含對話歷程、工具呼叫的輸出、任務的中間結果等。透過 checkpointer,Agent 可以在每次執行結束時保存進度,即使系統重啟或流程中斷,也能從中斷點繼續。在開發測試中,可以使用內建的 MemorySaver,它會把狀態存在記憶體裡。在正式環境中,則應該把狀態持久化到資料庫,確保提供持久化服務。thread_id。這個值就像是對話 Session 的專屬標識,能讓 Agent 理解多次呼叫屬於同一段對話,應該延續上下文而不是重新開始。thread_id 的值完全由使用者控制,可以是任意字串,例如 1 或 user-123-session-xyz。只要不同次呼叫使用相同的 thread_id,LangGraph 就會自動把之前的對話歷程帶入,讓 Agent 能在後續互動中自然延續對話。以下是一個簡單範例,展示如何讓 Agent 記住使用者先前的提問:
import { ChatOpenAI } from '@langchain/openai';
import { StateGraph, MessagesAnnotation, START, END } from '@langchain/langgraph';
import { MemorySaver } from '@langchain/langgraph-checkpoint';
// 建立 LLM
const llm = new ChatOpenAI({
model: 'gpt-4o-mini',
});
// 建立 Checkpointer
const checkpointer = new MemorySaver();
// 定義一個節點:呼叫 LLM
async function callModel(state: typeof MessagesAnnotation.State) {
const response = await llm.invoke(state.messages);
return { messages: [response] };
}
// 建立 workflow
const workflow = new StateGraph(MessagesAnnotation)
.addNode('call_model', callModel)
.addEdge(START, 'call_model')
.addEdge('call_model', END);
// 編譯成可執行的 app,並帶入 checkpointer
const app = workflow.compile({ checkpointer });
// 設定 thread_id,讓多輪對話共享記憶
const config = { configurable: { thread_id: 'mountain-quiz' } };
// 第一次對話:詢問台灣最高的山
const taiwanRes = await app.invoke(
{ messages: [{ role: 'user', content: '台灣最高的山是什麼?' }] },
config,
);
console.log( '台灣最高的山:', taiwanRes.messages[taiwanRes.messages.length - 1].content);
// 第二次對話:延續前文,詢問日本最高的山
const japanRes = await app.invoke(
{ messages: [{ role: 'user', content: '那日本呢?' }] },
config,
);
console.log('日本最高的山:', japanRes.messages[japanRes.messages.length - 1].content);
在這段程式碼中:
MemorySaver 是最簡單的 Checkpointer,會把狀態存放在記憶體中,適合本地開發或測試。若要在正式環境中使用,建議改為資料庫或其他持久化儲存。thread_id 是對話流程的唯一識別字串。這裡使用 mountain-quiz,代表「山岳問答」這個對話主題。thread_id 重複呼叫 Agent 時,之前的對話歷史會自動保留,因此 Agent 能理解「那日本呢?」是在延續查詢最高山的問題。執行程式後,你會得到類似以下的輸出:
台灣最高的山: 玉山是台灣最高的山,標高約 3952 公尺。
日本最高的山: 富士山是日本最高的山,標高約 3776 公尺。
透過這樣的設計,短期記憶能讓 Agent 在同一段對話或任務流程中維持連續性,使用者不需要重複背景資訊,互動就能自然又順暢。
在前面的範例中,我們使用 MemorySaver 作為 Checkpointer,把狀態暫存在記憶體中。這種方式很適合本地開發與測試,但一旦應用程式進入正式環境,就需要更可靠的 持久化儲存 來保存狀態,避免伺服器重啟或應用重置時導致對話歷史遺失。
LangGraph 提供了多種 Checkpointer 實作,它們都遵循 BaseCheckpointSaver 介面,並以獨立套件的形式提供,讓開發者可以依照應用需求自由選擇:
@langchain/langgraph-checkpoint:內建的基礎套件,包含 BaseCheckpointSaver 介面與序列化(Serialization)協定。內建提供的 MemorySaver 就是這裡的實作,適合開發階段或快速實驗。@langchain/langgraph-checkpoint-sqlite:使用 SQLite 的 SqliteSaver,適合本地或小型應用。由於是單檔資料庫,安裝簡單,方便快速啟動。@langchain/langgraph-checkpoint-postgres:使用 PostgreSQL 的 PostgresSaver,是正式環境最常見的選擇。具備高可靠性、交易支援與水平擴充能力,適合需要長期穩定運行的應用。@langchain/langgraph-checkpoint-mongodb:使用 MongoDB 的 MongoDBSaver,適合文件導向的應用場景。如果你的專案本來就依賴 MongoDB,這會是最自然的選擇。@langchain/langgraph-checkpoint-redis:使用 Redis 的 RedisSaver,能提供高速的讀寫效能。適合需要低延遲、即時存取的場景,例如即時對話系統或高併發應用。這些 Checkpointer 雖然在底層使用的儲存機制不同,但都遵循相同的 BaseCheckpointSaver 介面,因此具備一致的操作方式,支援以下核心方法:
.put():儲存一個完整的 checkpoint。.getTuple():依照條件讀取指定的 checkpoint,並恢復狀態。.list():查詢符合條件的 checkpoint 清單,用於檢視歷史紀錄。.putWrites():儲存與 checkpoint 相關的中間結果。開發者可以根據不同場景挑選合適的 Checkpointer:
此外,若內建方案無法滿足需求,開發者也能自行實作 BaseCheckpointSaver 介面,打造專屬的持久化策略。
透過選擇合適的實作方式,我們能確保 AI Agent 的短期記憶不會因服務重啟或環境切換而消失,進一步提升系統的穩定性與實用價值。
長期記憶(Long-term Memory) 則超越單一對話 Session 的限制,能夠在多次會話之間保存並重用資訊。這讓 Agent 能在不同時間點與使用者互動時,回想起之前學到的知識或記錄下來的偏好。
舉例來說,若使用者第一次告訴系統「我的名字是王小明」,下次對話時 Agent 仍能記得,並在互動中持續使用這些資訊。這樣的能力,能讓 AI 更個人化,也更接近真實助理的使用體驗。
在 LangGraph 中,長期記憶是透過 Store 來實現的。只要在流程中傳入 store,我們就能在節點或工具裡讀寫資料。長期記憶的實作包含兩個步驟:
InMemoryStore,而在正式環境中,則建議使用資料庫,確保資料能穩定保存。config.store 存取:當 Agent 建立時將 store 傳入,之後就能在工具、節點或 prompt 中透過 config.store 存取或更新長期記憶。例如,你可以在工具中查詢使用者資料,或在對話過程中動態更新偏好,讓這些資訊在下次互動時仍然有效。下面的範例示範如何事先把使用者資訊寫入 Store,並在工具中查詢:
import { ChatOpenAI } from '@langchain/openai';
import { StateGraph, MessagesAnnotation, START, END, LangGraphRunnableConfig } from '@langchain/langgraph';
import { ToolNode } from '@langchain/langgraph/prebuilt';
import { InMemoryStore } from '@langchain/langgraph-checkpoint';
import { tool } from '@langchain/core/tools';
import { z } from 'zod';
// 建立 Store
const store = new InMemoryStore();
// 預先寫入一筆使用者資料
await store.put(
['users'], // namespace
'user_123', // key
{ name: '王小明', language: '中文' } // value
);
// 定義查詢使用者資訊的工具
const getUserInfo = tool(
async (_input: Record<string, any>, config: LangGraphRunnableConfig) => {
const store = config.store;
const userId = config.configurable?.userId;
const userInfo = await store?.get(['users'], userId);
return userInfo ? JSON.stringify(userInfo.value) : '未知的使用者';
},
{
name: 'get_user_info',
description: '查詢使用者資訊',
schema: z.object({}),
}
);
// 包裝成 ToolNode
const tools = [getUserInfo];
const toolNode = new ToolNode(tools);
// 建立 LLM
const model = new ChatOpenAI({
model: 'gpt-4o-mini',
}).bindTools(tools);
// 建立流程
const workflow = new StateGraph(MessagesAnnotation)
.addNode('call_model', async (state) => {
const response = await model.invoke(state.messages);
return { messages: [response] };
})
.addNode('tools', toolNode) // 工具節點
.addEdge(START, 'call_model')
.addEdge('call_model', 'tools')
.addEdge('tools', END);
// 編譯成可執行的 app,並傳入 store
const app = workflow.compile({ store });
// 執行:查詢使用者資訊
const response = await app.invoke(
{ messages: [{ role: 'user', content: '幫我查一下使用者資訊' }] },
{ configurable: { userId: 'user_123' } }
);
console.log(response.messages[response.messages.length - 1].content);
在這段程式碼中:
getUserInfo 工具,會從 Store 中讀取指定 userId 的資訊並回傳。ToolNode 將工具包裝成節點,並與 LLM 節點串接。configurable.userId 傳入欲查詢的使用者,讓工具能讀取對應的資料。執行程式後,你會得到類似以下的輸出:
{"name":"王小明","language":"中文"}
這表示 Agent 已經成功讀取到跨會話保存的使用者資訊。下次即使是新的對話流程,只要帶上相同的 userId,Agent 依然能存取同一份資料。
除了讀取之外,Agent 也能在互動過程中動態更新長期記憶,例如保存新的偏好或修改使用者資料。以下範例示範如何讓 Agent 把使用者名稱寫入 Store:
import { ChatOpenAI } from '@langchain/openai';
import { StateGraph, MessagesAnnotation, START, END, LangGraphRunnableConfig } from '@langchain/langgraph';
import { ToolNode } from '@langchain/langgraph/prebuilt';
import { InMemoryStore } from '@langchain/langgraph-checkpoint';
import { tool } from '@langchain/core/tools';
import { z } from 'zod';
// 建立 Store
const store = new InMemoryStore();
// 定義更新使用者資訊的工具
const saveUserInfo = tool(
async (input: { name: string }, config: LangGraphRunnableConfig) => {
const store = config.store;
const userId = config.configurable?.userId;
await store?.put(['users'], userId, input);
return '使用者資訊已成功更新';
},
{
name: 'save_user_info',
description: '更新使用者資訊',
schema: z.object({ name: z.string() }),
}
);
// 包裝成 ToolNode
const tools = [saveUserInfo];
const toolNode = new ToolNode(tools);
// 建立 LLM
const model = new ChatOpenAI({
model: 'gpt-4o-mini',
}).bindTools(tools);
// 建立流程
const workflow = new StateGraph(MessagesAnnotation)
.addNode('call_model', async (state) => {
const response = await model.invoke(state.messages);
return { messages: [response] };
})
.addNode('tools', toolNode) // 工具節點
.addEdge(START, 'call_model')
.addEdge('call_model', 'tools')
.addEdge('tools', END);
// 編譯成可執行的 app,並傳入 store
const app = workflow.compile({ store });
// 執行:更新使用者資訊
await app.invoke(
{ messages: [{ role: 'user', content: '我的名字是王小明' }] },
{ configurable: { userId: 'user_123' } }
);
// 驗證寫入結果
const userInfo = await store.get(['users'], 'user_123');
console.log(userInfo.value);
在這段程式碼中:
tool() 定義了一個 saveUserInfo 工具,能將使用者的姓名存入 Store。ToolNode 將工具包裝成節點,並接在 LLM 節點後。store.get() 驗證資料是否成功寫入。執行程式後,你會得到類似以下的輸出:
{ name: '王小明' }
這樣一來,Agent 不僅能讀取既有的長期記憶,還能在對話過程中即時更新使用者資料,讓後續互動能延續新的資訊,逐步建立個人化的持續記憶。
在前面的範例中,我們示範了使用 InMemoryStore 來保存使用者資訊。這種方式雖然方便,但資料只存在於記憶體中,一旦服務重啟就會遺失,因此僅適合在本地開發或測試階段使用。
若要在正式環境中運行,長期記憶必須具備 持久化能力,確保跨對話、跨 Session 的資料能被安全保存並隨時取用。LangGraph 為此提供了統一的 BaseStore,讓開發者能在不同後端間切換或自行擴充。
目前官方支援的實作包括:
InMemoryStore:內建的記憶體型 Store,適合快速開發與本地測試,但不具持久化能力。PostgresStore:從 @langchain/langgraph-checkpoint-postgres/store 引入,官方推薦的生產環境解決方案。除了能將資料持久化到 PostgreSQL,還能搭配 pgvector 擴充支援語意檢索與相似度搜尋,是目前最完整、最穩定的選項。Note:根據 LangGraph 官方文件,目前正式支援的持久化後端主要是 Postgres,其他資料庫方案尚未提供官方套件。若有需求,建議使用
PostgresStore,或自行依照BaseStore介面擴充。
雖然 LangGraph 已經提供了 Store 作為長期記憶的基礎設計,但必須承認,長期記憶並不是一個已經被徹底解決的問題。正如 LangChain 官方在 部落格文章 中提到的,目前沒有一種「放諸四海皆準」的記憶方案,每個應用仍需要依照自身需求來調整設計。
開發者在實作長期記憶時,通常會面臨以下幾個挑戰:
因此,我們可以把 LangGraph 的 Store 視為一個基礎框架,但實際要如何「設計記憶」、以及「如何在任務中取用記憶」,仍然需要開發者根據應用情境做取捨與最佳化。
今天我們探討了如何讓 AI Agent 具備「記憶」,不再只能處理單次互動,而是能跨任務、跨對話保存狀態與知識,讓系統更智慧、更貼近真實應用:
MemorySaver 適合開發測試,官方另提供 SQLite、Postgres、MongoDB、Redis 等持久化方案。InMemoryStore 適合開發測試,而生產環境則推薦使用 PostgresStore,並可搭配 pgvector 提供語意檢索。記憶機制推動 AI Agent 從一次性回應走向持續學習與個人化助理的關鍵,而「記得什麼、記多久、如何安全保存」將是未來設計的核心課題。
本系列文已正式出版為《Node.js 生成式 AI 應用開發實戰:實作 OpenAI API × LangChain × LangGraph × RAG,打造從雲端到本地 LLM 的混合式安全架構》。內容全面升級,提供更完整的實戰範例與 LLM 應用架構設計。歡迎參考選購,開啟你的生成式 AI 開發之路!
天瓏網路書店連結:https://www.tenlong.com.tw/products/9786264144964


