
經過前幾天的學習,我們已經掌握了 LangGraph 的基本操作、Agent 設計模式、人機協作流程,以及 MCP 工具的整合方法。今天,我們要把這些技術整合起來,打造一個更完整的應用案例:一個具備網路搜尋能力、能與使用者互動確認方向的 AI 驅動寫作代理。
這個案例其實可以看作是 Day 13「具網路搜尋能力的 AI 部落格寫手」 的升級版。不同的是,這次我們不再單純透過 LangChain 的 Chain 實作,而是使用 LangGraph 打造一個真正的 AI Agent。它能根據情境自主決定何時需要搜尋,並在寫作過程中與使用者確認需求,讓整體流程更加靈活、智慧化。
在開始前,我們先回顧一下在 Day 13 完成的「具網路搜尋能力的 AI 部落格寫手」的關鍵設計:
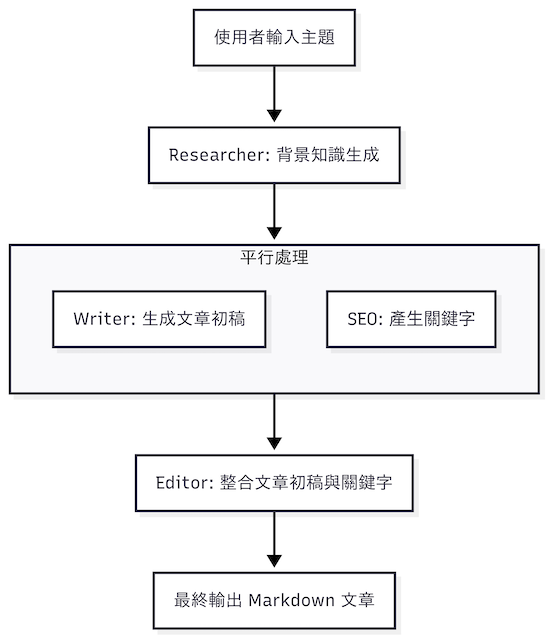
在這一版的設計中,我們利用 LangChain 的 RunnableSequence 與 RunnableParallel,結合網路搜尋、草稿生成、SEO 關鍵字與最終 Markdown 組裝,確實能完成「輸入主題 → 生成文章」的全流程。然而,這個版本仍存在幾個限制:
雖然能判斷是否需要搜尋,但整體仍是「單次呼叫 → 輸出文章」的模式,缺少多輪互動或修訂機制。在今天的版本中,我們改用 LangGraph 來重新設計整體架構,並做了以下強化:
整體流程如下:
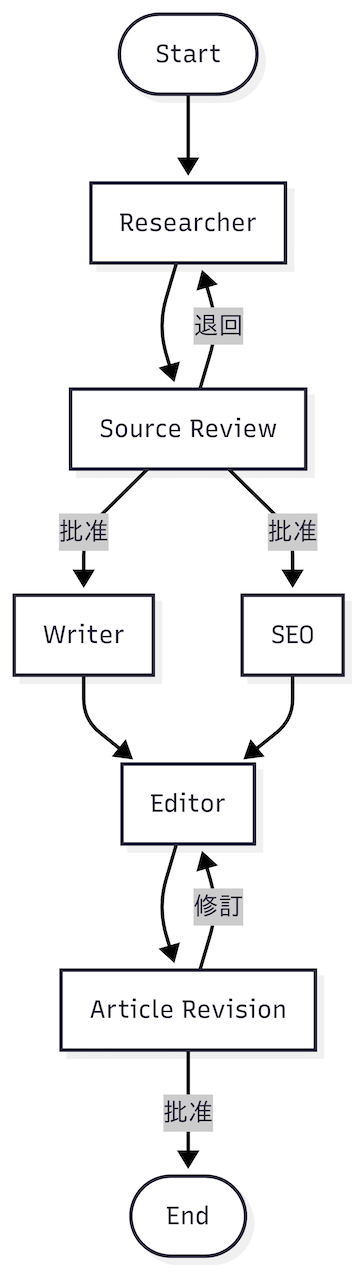
整個流程中的各個節點的角色職責如下:
透過這樣的改造,AI 部落格寫手不僅具備搜尋與內容生成能力,更能依靠 LangGraph 的狀態機設計與人機協作機制,形成一個可控、可審核、可迭代的寫作流程。
接下來,就要開始動手實作。為了方便管理程式碼並保持結構清晰,我們會建立一個全新的 LangGraph 專案,將這些節點與流程放進統一的架構中。
首先,我們使用官方工具 create-langgraph 來建立一個全新的專案:
create-langgraph blog-writer-agent
當工具詢問模板類型時,選擇 New LangGraph Project 即可。這個模板會自動幫你建立一個包含 src/agent 目錄的專案骨架。
接著進入專案資料夾並安裝相依套件:
cd blog-writer-agent
yarn install
初始化專案後,接著安裝以下套件:
yarn add @langchain/openai @langchain/mcp-adapters dotenv inquirer ora zod
這些套件的用途如下:
@langchain/openai:LangChain 提供的 OpenAI 模型整合套件。@langchain/mcp-adapters:用來將 MCP Server 提供的工具自動轉換為 LangChain 的 Tool。dotenv:用來讀取 .env 檔案中的環境變數,例如 API 金鑰。inquirer:建立互動式命令列介面,讓使用者可以輸入主題、確認是否繼續產生下一篇文章等。ora:在命令列介面中顯示動態的 loading 動畫與狀態提示,提升使用者體驗。zod:用來定義資料結構並驗證輸出的資料格式,確保 JSON 回傳內容符合我們預期的欄位與型別。在專案根目錄建立 .env 檔案,填入你的 OpenAI API 與 Tavily 金鑰:
LANGSMITH_KEY=llsv2...
OPENAI_API_KEY=sk-...
TAVILY_API_KEY=tvly-dev-...
LANGSMITH_KEY:啟用 LangSmith 觀察功能(可選,但建議填入,方便後續在 Studio UI 追蹤流程)。OPENAI_API_KEY:OpenAI API 金鑰。TAVILY_API_KEY:Tavily API 金鑰。為了讓程式碼結構清晰、方便維護,我們將專案拆分為不同的模組與檔案。整體規劃如下:
blog-writer-agent/
├── src/
│ ├── agent # Agent 相關邏輯
│ │ ├── nodes # 各個流程節點的實作
│ │ │ ├── editor.node.ts # 編輯文章的節點
│ │ │ ├── final-approval.node.ts # Agent 相關邏輯
│ │ │ ├── researcher.node.ts # 搜尋與研究資料的節點
│ │ │ ├── seo.node.ts # 產生 SEO 關鍵字的節點
│ │ │ ├── source-review.node.ts # 資料來源審查節點 (HITL)
│ │ │ └── writer.node.ts # 撰寫文章草稿的節點
│ │ ├── graph.ts # 定義整個流程的狀態圖
│ │ └── state.ts # 定義整個流程的狀態圖
│ └── index.ts # CLI 主程式入口
├── package.json # 專案設定與依賴套件清單
├── tsconfig.json # TypeScript 編譯設定
├── .env # 環境變數設定
│
專案的核心程式碼都放在 src/ 目錄下。其中,agent/ 資料夾專門用來存放 Agent 的邏輯,index.ts,作為 CLI 主程式入口,負責啟動流程並與使用者互動。
在 LangGraph 中,每個節點都會存取與更新一份共享狀態,因此我們需要先定義一個統一的 State Schema。這份狀態能確保不同節點之間的輸入與輸出格式一致,也能避免資料在流程中遺失或不一致。
在 src/agent/state.ts 中,我們定義了一份共用狀態 StateAnnotation,用來描述文章生成流程中會用到的資料結構:
// src/agent/state.ts
import { BaseMessage, BaseMessageLike } from '@langchain/core/messages';
import { Annotation, messagesStateReducer } from '@langchain/langgraph';
export const StateAnnotation = Annotation.Root({
messages: Annotation<BaseMessage[], BaseMessageLike[]>({
reducer: messagesStateReducer,
default: () => [],
}),
topic: Annotation<string>(),
background: Annotation<string>(),
references: Annotation<{ title?: string, url?: string }[]>(),
title: Annotation<string>(),
content: Annotation<string>(),
keywords: Annotation<string>(),
draft: Annotation<string>(),
article: Annotation<string>(),
reviewed: Annotation<{ isApproved: boolean, feedback?: string }>(),
revised: Annotation<{ isApproved: boolean, feedback?: string }>(),
});
這裡的設計包含幾個重點欄位:
messagesStateReducer 管理累積邏輯。這樣的狀態設計能統一管理所有節點的輸入與輸出,避免資料出現不一致,同時讓整個流程更容易追蹤與維護。
這個節點的任務是負責主題調研與資料收集。它會根據使用者提供的主題,自動判斷是否需要呼叫外部搜尋工具,並整理出一份背景說明與可追溯的參考來源。這樣可以避免模型僅依靠舊知識,確保文章的資訊可靠且具有時效性。
以下是完整程式碼實作:
// src/agent/nodes/researcher.node.ts
import { createReactAgent } from '@langchain/langgraph/prebuilt';
import { ChatOpenAI } from '@langchain/openai';
import { MultiServerMCPClient } from '@langchain/mcp-adapters';
import { HumanMessagePromptTemplate, SystemMessagePromptTemplate } from '@langchain/core/prompts';
import { StructuredOutputParser } from '@langchain/core/output_parsers';
import z from 'zod';
import { StateAnnotation } from '../state.js';
export async function researcherNode(state: typeof StateAnnotation.State) {
const { messages, topic, background, references, reviewed } = state;
const client = new MultiServerMCPClient({
mcpServers: {
tavily: {
url: `https://mcp.tavily.com/mcp/?tavilyApiKey=${process.env.TAVILY_API_KEY}`,
transport: 'http',
},
},
});
const llm = new ChatOpenAI({ model: 'gpt-4o-mini', temperature: 0 });
const tools = await client.getTools();
const researcherAgent = createReactAgent({ llm, tools });
const parser = StructuredOutputParser.fromZodSchema(
z.object({
topic: z.string(),
background: z.string(),
references: z.array(
z.object({
title: z.string(),
url: z.string().url()
})
),
}),
);
const systemPrompt = SystemMessagePromptTemplate.fromTemplate(`
你是一位專業研究員,負責根據使用者提供的主題進行調查與整理。
請務必透過可用的搜尋工具獲取最新、可靠且相關的資訊,並用以補充背景知識。
請注意:
- 優先檢索最新資料,避免僅依靠舊知識。
- 背景說明需詳盡(至少 1000 字),提供足夠脈絡讓讀者快速理解主題。
- 引用資訊時,請提供清楚的來源與連結(references),確保可追溯性與可信度。
- 如果搜尋結果中包含相互矛盾的觀點,請明確指出並比較。
- 若相關資訊不足,也要誠實說明並提出可能的研究方向。
{format_instructions}
`);
const systemMessage = await systemPrompt.format({
format_instructions: parser.getFormatInstructions(),
});
if (background && topic && reviewed.feedback) {
const humanPrompt = HumanMessagePromptTemplate.fromTemplate(`
主題: {topic}
背景資訊: {background}
參考資料: {references}
使用者建議: {feedback}
請務必依據上述建議調整研究方向,必要時更新主題描述、背景內容以及參考資料。
{format_instructions}
`);
const humanMessage = await humanPrompt.format({
topic,
background,
references,
feedback: reviewed.feedback,
format_instructions: parser.getFormatInstructions(),
});
messages.push(humanMessage);
}
const result = await researcherAgent.invoke({
messages: [ systemMessage, ...messages ],
});
const lastMessage = result.messages[result.messages.length - 1];
const parsedMessage = await parser.parse(lastMessage.content as string);
return {
messages,
topic: parsedMessage.topic,
background: parsedMessage.background,
references: parsedMessage.references,
};
}
這裡的設計重點如下:
MultiServerMCPClient 連接 Tavily MCP Server,讓 Agent 具備即時搜尋能力。createReactAgent 套用 ReAct 模式,使 Agent 能先推理,再決定是否需要呼叫工具,而不是機械式地進行搜尋。zod 與 StructuredOutputParser 定義,確保結果一定包含主題、背景與參考來源三個欄位,避免模型輸出不一致或缺漏。這樣一來,Researcher 節點就能穩定提供結構化且可靠的背景資訊,成為後續寫作過程中最重要的知識基礎。
Source Review 節點是流程中的第一個 HITL 節點,負責讓使用者快速檢查 Researcher 整理出來的背景知識與參考來源。透過這一步,可以避免不可靠或不相關的資料直接流入後續的寫作流程,確保輸入內容的品質。
// src/agent/nodes/source-review.node.ts
import { interrupt, Command } from '@langchain/langgraph';
import { RemoveMessage } from '@langchain/core/messages';
import { StateAnnotation } from '../state.js';
export async function sourceReviewNode(state: typeof StateAnnotation.State) {
const { topic, background, references } = state;
const reviewed = interrupt({
type: 'source_review',
payload: { topic, background, references },
});
if (reviewed.isApproved) {
return new Command({
goto: ['writer', 'seo'],
update: {
reviewed,
messages: state.messages.map(message => new RemoveMessage({ id: message.id as string })),
},
});
} else {
return new Command({
goto: 'researcher',
update: { reviewed },
});
}
}
這裡的運作邏輯可以分成兩種情境:
換句話說,Source Review 節點就像流程中的守門人,在早期過濾掉錯誤或不完整的研究結果,確保輸入資料的品質。
Writer 節點的任務是將 Researcher 整理的背景資訊轉化為一篇具結構性的文章草稿。這個節點相當於一位專業的寫手,負責將研究成果包裝成適合一般讀者閱讀的內容,並確保文章具備吸引力與可讀性。
以下是完整的程式實作:
// src/agent/nodes/writer.node.ts
import { ChatOpenAI } from '@langchain/openai';
import { PromptTemplate } from '@langchain/core/prompts';
import { StructuredOutputParser } from '@langchain/core/output_parsers';
import z from 'zod';
import { StateAnnotation } from '../state.js';
export async function writerNode(state: typeof StateAnnotation.State) {
const { topic, background } = state;
const llm = new ChatOpenAI({
model: 'gpt-4o-mini',
});
const prompt = PromptTemplate.fromTemplate(`
你是一位專業部落格寫手,請根據以下主題與背景知識撰寫一篇文章。
要求:
- 文章必須有清晰的結構(引言、主體、結論)。
- 內容需至少 800 字,條理分明,避免只有單一大段文字。
- 風格要流暢、具吸引力,讓一般讀者容易理解。
- 標題要簡潔、吸睛,並能反映主題核心。
- 適度使用小標題或段落分隔,提升可讀性。
主題: {topic}
背景資訊: {background}
{format_instructions}
`);
const parser = StructuredOutputParser.fromZodSchema(
z.object({
title: z.string(),
content: z.string(),
}),
);
const result = await prompt.pipe(llm).pipe(parser).invoke({
topic,
background,
format_instructions: parser.getFormatInstructions(),
});
return {
title: result.title,
content: result.content,
};
}
這裡的設計重點在於:
PromptTemplate,我們能夠明確告訴 LLM 輸出的文章需要具備哪些結構與格式,例如引言、主體與結論。StructuredOutputParser 搭配 zod 定義輸出模式,確保回傳的內容一定包含 title 與 content,避免模型輸出不完整或格式錯誤。最終效果是讓生成的文章草稿更有組織性、結構清楚,同時維持與研究內容的一致性,方便進入後續編輯流程。
SEO 節點的任務是從文章主題與背景知識中,產生一份適合搜尋引擎優化的關鍵字清單。這些關鍵字能幫助文章在搜尋結果中更容易被找到,同時也能在後續編輯流程中自然融入文章內容。
以下是完整的程式實作:
// src/agent/nodes/seo.node.ts
import { ChatOpenAI } from '@langchain/openai';
import { PromptTemplate } from '@langchain/core/prompts';
import { CommaSeparatedListOutputParser } from '@langchain/core/output_parsers';
import { StateAnnotation } from '../state.js';
export async function seoNode(state: typeof StateAnnotation.State) {
const { topic, background } = state;
const llm = new ChatOpenAI({
model: 'gpt-4o-mini',
temperature: 0,
});
const prompt = PromptTemplate.fromTemplate(`
你是一位 SEO 專家。請根據以下主題與背景知識,產出 **5–10 組適合搜尋優化的關鍵字**。
要求:
- 關鍵字需與主題高度相關。
- 請同時包含「短尾關鍵字」與「長尾關鍵字」。
- 避免過度泛用或模糊的詞彙(例如:科技、新聞、文章)。
- 僅輸出關鍵字清單,使用逗號分隔,不要多餘文字。
主題: {topic}
背景資訊: {background}
{format_instructions}
`);
const parser = new CommaSeparatedListOutputParser();
const result = prompt.pipe(llm).pipe(parser).invoke({
topic,
background,
format_instructions: parser.getFormatInstructions(),
});
return {
keywords: result,
};
}
這裡的設計有幾個重點:
CommaSeparatedListOutputParser 將模型的文字輸出轉換為結構化清單,方便後續在 Editor 節點中直接使用。這樣能保證文章同時涵蓋廣泛搜尋與精準搜尋需求,讓後續產出的內容更容易在搜尋引擎中獲得曝光。
Editor 節點的任務是將 Writer 生成的草稿、SEO 節點輸出的關鍵字,以及 Researcher 提供的參考資料 整合成一篇完整的 Markdown 文章。這個節點是整個流程的關鍵產出點,不僅要組裝內容,還必須兼顧結構化格式、可讀性,以及引用的正確性,讓最終文章具備可直接發佈的品質。
以下是完整的程式實作:
// src/agent/nodes/editor.node.ts
import { ChatOpenAI } from '@langchain/openai';
import { HumanMessagePromptTemplate, SystemMessagePromptTemplate } from '@langchain/core/prompts';
import { StringOutputParser } from '@langchain/core/output_parsers';
import { StateAnnotation } from '../state.js';
export async function editorNode(state: typeof StateAnnotation.State) {
const { messages, title, content, keywords, references, draft, revised } = state;
const llm = new ChatOpenAI({
model: 'gpt-4o-mini',
temperature: 0,
});
if (!draft) {
const systemPrompt = SystemMessagePromptTemplate.fromTemplate(`
你是一位專業編輯,請根據以下資訊撰寫一篇完整的文章,並輸出為 **Markdown 格式**。
要求:
- 文章必須包含:標題、引言、主體(可用小標題分段)、結論。
- 適度融入提供的 SEO 關鍵字,但不要過度堆疊。
- 使用 Markdown 格式(# 標題、## 小標題、段落、列表)。
- 文風要流暢、自然,適合一般讀者閱讀。
- 若有參考資料,請在文末附上「參考資料」區塊。
- 請在文章最後新增一行,以 #hashtag 形式列出提供的 SEO 關鍵字。
{data}
`);
const systemMessage = await systemPrompt.format({
data: JSON.stringify({ title, content, keywords, references }),
});
messages.push(systemMessage);
} else {
const humanMessagePrompt = HumanMessagePromptTemplate.fromTemplate(`
你是一位專業編輯,請根據以下用戶建議修改文章,並輸出為 **Markdown 格式**。
要求:
- 務必依照「使用者建議」進行調整。
- 在保留文章原有結構的基礎上,改善內容與表達。
- 若需要補充,請保持一致的語氣與風格。
- 確保仍包含標題、引言、主體、結論,並維持清晰結構。
- 請在文章最後新增一行,以 #hashtag 形式列出提供的 SEO 關鍵字。
使用者建議: {feedback}
{draft}
`);
const humanMessage = await humanMessagePrompt.format({
draft,
feedback: revised.feedback,
})
messages.push(humanMessage);
}
const parser = new StringOutputParser();
const result = await llm.pipe(parser).invoke(messages);
return {
messages,
draft: result,
};
}
在這段程式設計中,可以看到幾個重點:
StringOutputParser 來保證最終輸出是一個乾淨的 Markdown 字串,方便直接輸出或儲存。因此,Editor 節點扮演了整合者的角色,把研究、撰稿與關鍵字結果轉化為可直接發佈的完整文章。
Article Revision 節點是流程中的第二個 HITL 節點,負責讓使用者在文章草稿完成後進行最後一輪審查。這裡使用者可以選擇直接批准初稿,將其輸出為完整文章,或是提供具體修改建議,再次退回 Editor 節點進行修訂。
// src/agent/nodes/article-revision.node.ts
import { interrupt, Command } from '@langchain/langgraph';
import { StateAnnotation } from '../state.js';
export async function articleRevisionNode(state: typeof StateAnnotation.State) {
const { draft } = state;
const revised = interrupt({
type: 'article_revision',
payload: { draft },
});
if (revised.isApproved) {
return { article: draft }
} else {
return new Command({
goto: 'editor',
update: { revised },
});
}
}
這裡的運作方式可以拆解為兩種情境:
article 狀態,流程隨即結束,輸出完整文章。revised 狀態,並退回 Editor 節點,再次進行修訂與重組。有了這個設計,最終的審稿環節能真實反映使用者的意圖與建議,讓輸出的文章更貼近需求。
前面我們已經分別建立了 Researcher、Source Review、Writer、SEO、Editor、Article Revision 等節點。接下來要做的,就是把這些節點組裝成一個完整的 LangGraph 流程,讓整個 Agent 能自動執行從研究、撰稿到最終審稿的全過程。
以下是主流程的組裝程式碼:
// src/agent/graph.ts
import { StateGraph, MemorySaver, START, END } from '@langchain/langgraph';
import { StateAnnotation } from './state.js';
import { researcherNode } from './nodes/researcher.node.js';
import { sourceReviewNode } from './nodes/source-review.node.js';
import { writerNode } from './nodes/writer.node.js';
import { seoNode } from './nodes/seo.node.js';
import { editorNode } from './nodes/editor.node.js';
import { articleRevisionNode } from './nodes/article-revision.node.js';
const builder = new StateGraph(StateAnnotation)
.addNode('researcher', researcherNode)
.addNode('source_review', sourceReviewNode, { ends: ['researcher', 'writer', 'seo'] })
.addNode('writer', writerNode, { ends: ['editor'] })
.addNode('seo', seoNode, { ends: ['editor'] })
.addNode('editor', editorNode)
.addNode('article_revision', articleRevisionNode, { ends: ['editor', END] })
.addEdge(START, 'researcher')
.addEdge('researcher', 'source_review')
.addEdge('writer', 'editor')
.addEdge('seo', 'editor')
.addEdge('editor', 'article_revision')
.addEdge('article_revision', END);
export const graph = builder.compile({
checkpointer: new MemorySaver(),
});
graph.name = 'Blog Writer Agent';
這裡的流程設計可以拆解為幾個階段:
START 進入 researcher,由 Researcher 節點負責蒐集並整理背景知識。source_review,由人類審核研究結果;若通過,流程會同時分支到 writer 與 seo,否則退回 researcher 重新查詢。editor,由 Editor 節點組裝完整文章。article_revision,由人類做最終確認。若批准,輸出完整文章;若要求修訂,流程會退回 Editor 重新修改。此外,這裡使用了 MemorySaver 作為 checkpoint 機制,讓 HITL 節點(Source Review、Article Revision)中斷後也能順利恢復,確保人機協作流程穩定運行。
透過這樣的組裝方式,我們就完成了一個具備研究、撰稿、審查與修訂能力的 AI 部落格寫手流程圖,讓 Agent 不僅能生成文章,還能與人類協作完成高品質的內容產出。
當我們完成了各個節點與流程設計後,我們最後實作一個命令列介面主程式,來串接整個 Agent,讓使用者能直接在終端機輸入主題、參與審查,並輸出最終文章。這個 CLI 程式的角色就像「操作台」,把人機互動的流程包裝成一個直觀的工具。
以下是完整程式碼:
// src/index.ts
import 'dotenv/config';
import inquirer from 'inquirer';
import ora from 'ora';
import { randomUUID } from 'crypto';
import { Command, INTERRUPT, isInterrupted, type Interrupt } from '@langchain/langgraph';
import { graph } from './agent/graph.js';
import { StateAnnotation } from './agent/state.js';
// 取得文章主題輸入
async function promptTopicInput() {
const { topic } = await inquirer.prompt<{ topic: string }>([
{
type: 'input',
name: 'topic',
message: '請輸入文章主題:',
filter: (value) => (value ?? '').trim(),
validate: (value: string) => value.trim().length > 0 || '請輸入主題',
},
]);
return { messages: [{ role: 'user', content: topic }] };
}
// Source Review 人類審查流程
async function promptSourceReview(payload: {
topic: string;
background: string;
references: Array<{ title: string; url: string }>;
}) {
console.log('\n=== 研究結果審核 ===');
console.log(`主題: ${payload.topic}`);
console.log('\n背景概要:\n');
console.log(payload.background);
if (payload.references?.length) {
console.log('\n參考資料:');
payload.references.forEach((ref, index) => {
console.log(` ${index + 1}. ${ref.title} - ${ref.url}`);
});
}
const answers = await inquirer.prompt<{
decision: 'approve' | 'reject';
feedback?: string;
}>([
{
type: 'list',
name: 'decision',
message: '請選擇審核結果:',
choices: [
{ name: '批准內容,進入撰稿階段', value: 'approve' },
{ name: '退回內容,提供修正建議', value: 'reject' },
],
default: 'approve',
},
{
type: 'input',
name: 'feedback',
message: '請輸入需要補充或修正的說明:',
when: (prev) => prev.decision !== 'approve',
filter: (value: string) => value.trim(),
validate: (value: string) => value.trim().length > 0 || '請提供說明內容',
},
]);
return {
isApproved: answers.decision === 'approve',
...(answers.feedback ? { feedback: answers.feedback } : {}),
};
}
// Article Revision 人類審查流程
async function promptArticleReview(payload: { draft: string }) {
console.log('\n=== 文章初稿 ===\n');
console.log(payload.draft);
const answers = await inquirer.prompt<{
decision: 'approve' | 'revise';
feedback?: string;
}>([
{
type: 'list',
name: 'decision',
message: '請選擇後續動作:',
choices: [
{ name: '接受內容,輸出完整文章', value: 'approve' },
{ name: '重新編輯,提出修改建議', value: 'revise' },
],
default: 'approve',
},
{
type: 'input',
name: 'feedback',
message: '請輸入修改建議:',
when: (prev) => prev.decision !== 'approve',
filter: (value: string) => value.trim(),
validate: (value: string) => value.trim().length > 0 || '請提供具體建議',
},
]);
return {
isApproved: answers.decision === 'approve',
...(answers.feedback ? { feedback: answers.feedback } : {}),
};
}
// 根據中斷類型呼叫對應的審查流程
async function resolveInterrupt(interrupt: Interrupt): Promise<unknown> {
const { type, payload } = interrupt.value;
switch (type) {
case 'source_review': return promptSourceReview(payload);
case 'article_revision': return promptArticleReview(payload);
default: throw new Error('unknown interrupt type');
}
}
// 主程式入口
async function main() {
const spinner = ora();
const threadConfig = { configurable: { thread_id: randomUUID() } };
let finalState: typeof StateAnnotation.State;
let nextInput;
console.log(`=== ${graph.name} 已啟動 ===`);
nextInput = await promptTopicInput();
try {
while (true) {
spinner.start('處理中, 請稍候...');
const result = await graph.invoke(nextInput, threadConfig);
// 處理 HITL 中斷
if (isInterrupted(result)) {
spinner.stop();
const interrupts = result[INTERRUPT] ?? [];
const resume = await resolveInterrupt(interrupts[0]);
nextInput = new Command({ resume });
continue;
}
finalState = result;
break;
}
spinner.succeed('完成!');
} catch (error) {
spinner.fail('發生錯誤:');
throw error;
}
console.log('\n=== 文章內容 ===\n');
console.log(finalState.article);
process.exit(0);
}
main().catch(console.error);
在這段程式中,幾個重要的功能點:
inquirer 讓使用者輸入文章主題,並在 HITL 節點中參與審查或修訂。ora 顯示 CLI 的處理進度,提升使用體驗。randomUUID 建立獨立的 thread_id,確保上下文正確隔離。isInterrupted() 與 resolveInterrup() 搭配使用,能夠在流程遇到 HITL 節點時暫停,等待人類輸入,再繼續執行。憑藉這個 CLI 主程式,整個 AI 部落格寫手 Agent 就能以互動方式運行,讓使用者在每個關鍵環節中決定文章的品質與方向。
由於透過 create-langgraph 建立的專案採用 ES Module,在結構上與我們之前採用 CommonJS 的專案略有不同,因此在執行前需要先進行一些調整。
首先,打開專案目錄下的 package.json,在 "scripts" 欄位新增以下內容:
"scripts": {
"start": "yarn build && node dist/index.js"
}
這樣一來,每次執行 npm start 或 yarn start 時,會先進行編譯,再自動執行主程式。
在實際執行時,你可能會遇到 tests 目錄下出現編譯錯誤的情況,原因是我們並沒有撰寫任何測試程式。為了避免這個問題,可以打開 tsconfig.json,將 "include" 欄位修改為:
"include": ["src"]
這樣就能限制 TypeScript 只編譯 src 目錄下的檔案,排除掉測試資料夾。
完成設定後,就可以輸入以下指令執行測試:
npm start
程式啟動後,終端機會提示輸入文章主題,例如:
請輸入文章主題: AI 金融
在 研究階段 完成後,會進入第一個 來源審查 節點:
=== 研究結果審核 ===
主題: AI in Finance
背景資訊:
...(略)
參考資料:
...(略)
? 請選擇審核結果: (Use arrow keys)
❯ 批准內容,進入撰稿階段
退回內容,提供修正建議
使用者可以選擇 批准內容,讓流程進入撰稿階段;或選擇 退回內容,並提供修正建議,讓 Researcher 重新補充資料。
接著,當 文章初稿 生成後,會進入第二個 文章審查 節點:
=== 文章初稿 ===
...(略)
? 請選擇後續動作: (Use arrow keys)
❯ 接受內容,輸出完整文章
重新編輯,提出修改建議
若選擇 接受內容,則直接輸出完整文章;若選擇 重新編輯,需要輸入具體的修改建議:
✔ 請選擇後續動作: 重新編輯,提出修改建議
? 請輸入修改建議:
LLM 會根據回饋修正文章,並重新送審,這個過程可以重複進行,直到你對內容滿意為止。
當所有流程完成後,會輸出一篇完整的文章,例如:
=== 文章內容 ===
# 人工智慧在金融業的應用:改變未來金融服務的關鍵
### 引言
隨著科技的迅速進步,人工智慧(AI)正在以前所未有的速度改變金融行業的運作方式。從風險管理到客戶互動,AI的應用不僅僅是一種趨勢,而是金融業的一次根本性變革。本文將深入探討AI在金融領域的關鍵應用、未來趨勢以及面臨的挑戰,讓我們一起了解這場金融革命。
### AI在金融中的關鍵應用
#### 1. 信用評分與風險評估
傳統的信用評分方法往往依賴有限的數據,這可能會排除那些信用檔案較薄的潛在借款人。AI系統能夠分析更廣泛的數據,包括社交媒體活動和交易歷史,從而更準確地評估信用風險。這種能力使銀行能夠識別出顯示客戶還款可能性的模式,從而降低違約風險。
#### 2. 欺詐檢測
AI算法能夠實時分析交易模式,以檢測可能表明欺詐活動的異常情況。透過機器學習技術,這些系統可以不斷從新數據中學習,隨著時間的推移提高準確性,並能更快地對潛在的欺詐行為作出反應,保護客戶的資金安全。
#### 3. 客戶服務自動化
AI驅動的聊天機器人和虛擬助手在銀行業中越來越多地被用來處理客戶查詢、提供賬戶信息和協助交易。這種自動化不僅提高了客戶滿意度,因為它提供了即時的回應,還使人類代理能夠專注於更複雜的問題,提升整體服務質量。
#### 4. 個性化金融服務
AI使金融機構能夠提供針對個別客戶需求的個性化服務。通過分析客戶行為和偏好,銀行可以提供定制的投資建議、預算工具和產品推薦,從而增強客戶的參與感和忠誠度,讓每位客戶都能感受到獨特的關懷。
#### 5. 投資管理
AI正在徹底改變資產管理,通過使更複雜的投資策略成為可能。算法可以分析大量的市場數據,以識別趨勢並做出預測,從而使投資決策更加明智。由AI驅動的機器人顧問也越來越受歡迎,提供自動化的投資管理服務,並降低成本,讓更多人能夠享受專業的投資服務。
#### 6. 監管合規
金融機構面臨著嚴格的監管要求。AI可以通過自動化交易監控和報告來協助合規,確保機構遵守規定,同時降低人為錯誤的風險,讓金融運作更加透明和安全。
### 未來趨勢
AI在金融領域的未來看起來非常光明,預測AI每年可能為全球銀行業創造2000億到3400億美元的價值,僅僅通過提高生產力。隨著AI技術的持續發展,它們可能會導致更大的金融包容性、增加透明度以及更智能的決策。
然而,AI的整合也引發了有關數據隱私、倫理考量和需要強有力的監管框架的擔憂。金融機構必須在創新與負責任的AI實踐之間取得平衡,以建立信任並確保AI應用在金融領域的長期可持續性。
### 結論
總之,AI將在塑造金融服務的未來中發揮核心作用,推動創新、效率和以客戶為中心的解決方案。隨著行業適應這些變化,戰略性地擁抱AI的組織將可能引領市場,並為金融服務設立新的卓越標準。
### 參考資料
- [AI in Banking: Real Use Cases and Industry Applications - Appinventiv](https://appinventiv.com/blog/ai-in-banking/)
- [Fintech Artificial Intelligence 2025: Strategic Applications for a ...](https://www.linkedin.com/pulse/fintech-artificial-intelligence-2025-strategic-applications-6eu9c)
- [AI in Banking: Reshaping the Future of Financial Services - LinkedIn](https://www.linkedin.com/pulse/ai-banking-reshaping-future-financial-services-strivemindz-lcgrc)
- [The Future of Finance: 2025 Predictions and Trends - Dwolla](https://www.dwolla.com/updates/the-future-of-finance-2025)
- [Digital innovation and artificial intelligence - KPMG International](https://kpmg.com/xx/en/our-insights/transformation/evolving-asset-management-regulation/digital-innovation-and-ai.html)
#AI #Finance #ArtificialIntelligence #FinancialServices #Innovation #RiskManagement #CustomerService #FraudDetection #InvestmentManagement
這樣,我們就完成了一次完整的 CLI 測試流程:從輸入主題、研究、來源審查,到文章撰稿、修訂與最終發佈,完整體驗 人機協作的部落格寫手 Agent。
今天我們用 LangGraph 完成了一個 具網路搜尋與人機互動能力的 AI 驅動寫作代理,將之前學到的技術整合成一個完整的應用:
這個範例展現了 LangGraph 的彈性與人機協作的實用性,讓 AI 不只是自動生成文章,而能與人互動完成更高品質、可控的內容產出。
本系列文已正式出版為《Node.js 生成式 AI 應用開發實戰:實作 OpenAI API × LangChain × LangGraph × RAG,打造從雲端到本地 LLM 的混合式安全架構》。內容全面升級,提供更完整的實戰範例與 LLM 應用架構設計。歡迎參考選購,開啟你的生成式 AI 開發之路!
天瓏網路書店連結:https://www.tenlong.com.tw/products/9786264144964


 iThome鐵人賽
iThome鐵人賽