在前一天的內容中,我們討論了為什麼要在自己的機器上部署 LLM,並且了解了開源模型在隱私、成本與自主性上的優勢。今天的主題將聚焦在 Ollama —— 一個近年非常受歡迎的本地 LLM 管理工具。透過 Ollama,你可以在本地快速下載、啟動並呼叫各種開源模型,而且介面設計與 OpenAI API 高度相容,非常適合與現有應用整合。
本文將帶你從安裝 Ollama 開始,逐步建構一個可以支援 RAG(Retrieval-Augmented Generation)的應用,並將 Day 19 的「公司年報問答系統」改寫成完全由本地 LLM 驅動的版本。
在眾多本地部署工具中,Ollama 最大的價值在於降低了模型運行的門檻,讓任何人都能快速上手。無論是單純想體驗 LLM 的入門者,還是需要將模型整合進專案的開發者,Ollama 都能提供相對友善的體驗。具體來說,它具備以下幾個優勢:
憑藉這些特點,Ollama 幾乎成為本地 LLM 的首選入門工具。對於個人開發者、研究人員或學生而言,它既能滿足學習與實驗的需求,也能作為開發原型的穩定基礎。
Ollama 的安裝過程非常簡單,官方已經針對不同平台提供了對應的下載方式與工具。只要依照以下步驟操作,就能快速完成安裝並開始使用。
首先,前往 Ollama 官方網站,在首頁即可看到下載選項。
點擊 「Download」 進入下載頁面後,根據你的作業系統選擇合適的安裝方式:
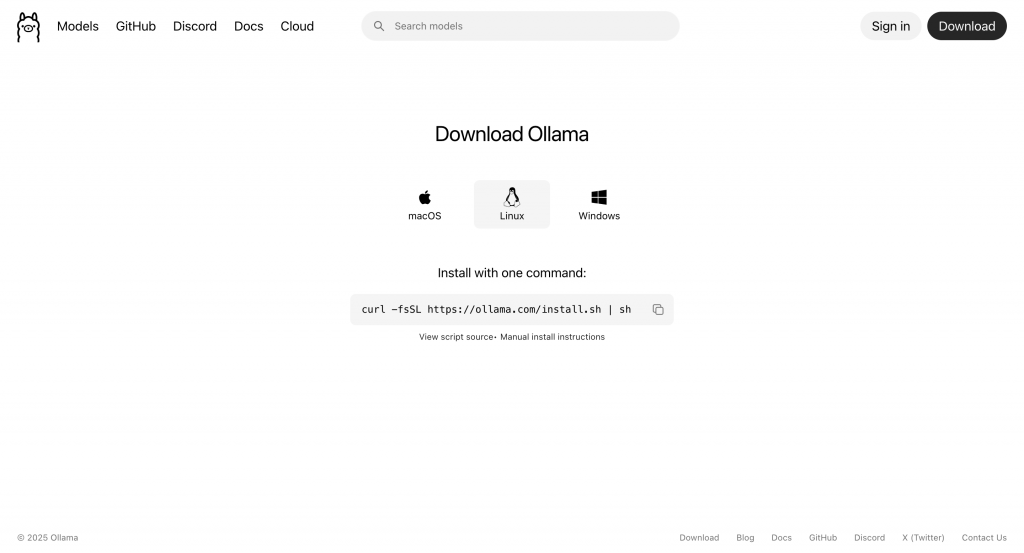
curl -fsSL https://ollama.com/install.sh | sh
安裝腳本會自動下載並配置所需環境。
安裝完成後,開啟終端機並輸入:
ollama
若能看到 Ollama 的指令清單,代表安裝已成功。
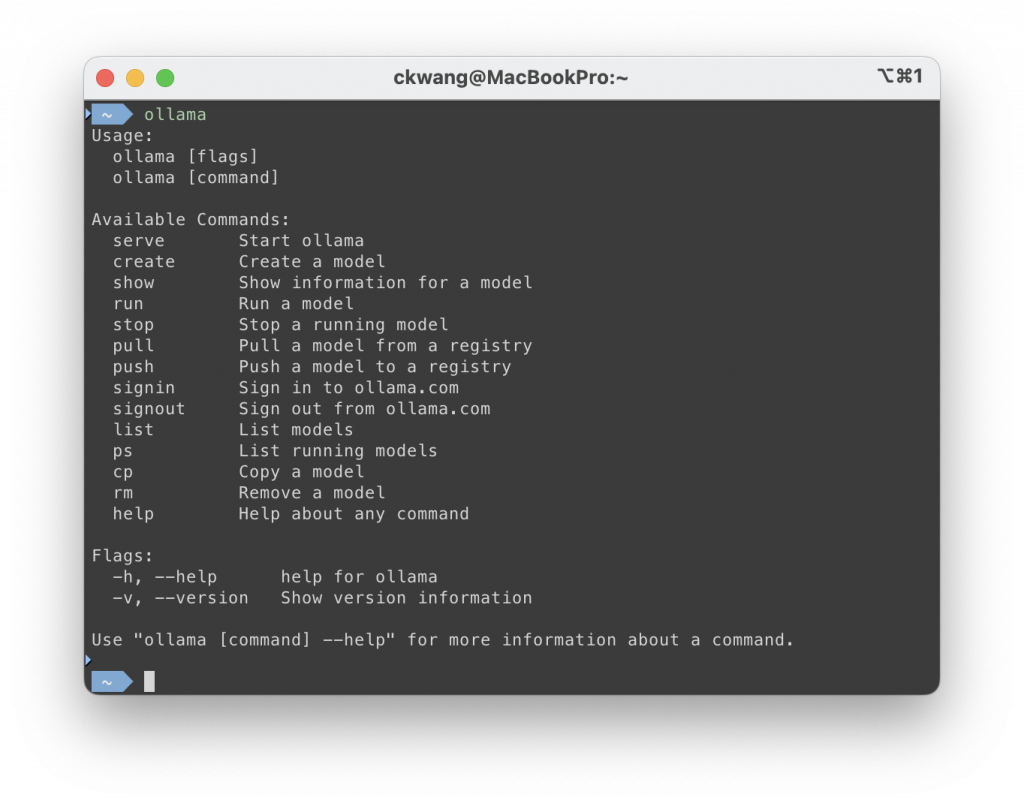
此時你的環境已準備就緒,接下來即可下載並執行模型,開始體驗本地 LLM。
安裝完成後,我們就能透過 Ollama 提供的 CLI 指令來管理與運行模型。若你熟悉 Docker,會發現 Ollama 的指令設計與之非常相似,對已經習慣容器化工作流程的開發者來說,幾乎可以零門檻上手。
以下以 Mistral 模型為例,示範幾個最常用的操作。
第一次執行某個模型時,Ollama 會自動下載對應的權重檔案。以下指令會下載並啟動 Mistral 模型,並直接進入互動模式:
ollama run mistral
此時你就能在終端機中與模型對話:
>>> What is Retrieval-Augmented Generation (RAG)?
RAG is a technique that combines large language models with external knowledge retrieval...
若只是想先下載模型,不立即進入互動模式,可以執行:
ollama pull mistral
這樣會將模型下載到本地,之後就能用 run 指令啟動模型。
列出目前已安裝在本地的模型:
ollama list
輸出範例:
NAME ID SIZE MODIFIED
mistral:latest 6577803aa9a0 4.4 GB 1 minutes ago
若要查看某個模型的規格與設定,可以使用:
ollama show mistral
輸出範例:
Model
architecture llama
parameters 7.2B
context length 32768
embedding length 4096
quantization Q4_K_M
Capabilities
completion
tools
Parameters
stop "[INST]"
stop "[/INST]"
License
Apache License
Version 2.0, January 2004
...
Ollama 啟動模型後會在背景建立實例,可以透過以下指令查看目前狀態:
ollama ps
輸出範例:
NAME ID SIZE PROCESSOR CONTEXT UNTIL
mistral:latest 6577803aa9a0 5.3 GB 100% CPU 4096 1 minutes from now
若要停止某個模型,則執行:
ollama stop mistral
這樣能釋放 GPU 或 CPU 資源,避免長時間佔用。
若不再需要某個模型,可以透過以下指令移除,釋放磁碟空間:
ollama rm mistral
Tip:所有下載的模型會存放在
~/.ollama/models/資料夾中(Windows 則在使用者目錄下的對應路徑)。若磁碟空間有限,建議定期清理不再使用的模型,或設定環境變數OLLAMA_MODELS指定其他存放位置。
除了 CLI,Ollama 也提供 REST API,方便將模型整合到應用程式或後端服務中。API 預設運行在 http://localhost:11434,常用端點如下:
POST /api/generate:單次生成,適合一次性任務。POST /api/chat:多輪對話,可保留上下文。POST /api/embed:將文字轉換為向量嵌入,用於檢索或 RAG 系統。以下分別示範三個端點的使用方式。
/api/generate/api/generate 用於單次生成回應,適合摘要、翻譯或簡單問答:
curl http://localhost:11434/api/generate -d '{
"model": "mistral",
"prompt": "解釋什麼是 LLM (Large Language Model)。"
}'
回傳範例(流式輸出,節錄):
{"response":"大型語言模型 (LLM) 是一種人工智慧模型...","done":false}
{"response":"它透過大量文本訓練,能理解並生成自然語言...","done":true}
這個端點適合「單回合」場景,例如生成摘要、翻譯一句話或回答一次性問題,不需保留上下文。
/api/chat/api/chat 用於多輪對話,可傳入 system、user、assistant 角色,最接近我們常見的聊天模式:
curl http://localhost:11434/api/chat -d '{
"model": "mistral",
"messages": [
{ "role": "system", "content": "你是一個樂於助人的 AI 助理。" },
{ "role": "user", "content": "用簡單的方式解釋什麼是量化 (Quantization)。" }
]
}'
回傳範例(流式輸出,節錄):
{"message":{"role":"assistant","content":"量化 (Quantization) 是一種將高精度數值轉換為低精度格式的技術..."},"done":false}
{"message":{"role":"assistant","content":"它常用於降低模型的計算與記憶體需求..."},"done":true}
這個端點能維持對話上下文,非常適合用於聊天助理或 Agent 類型應用。
/api/embed/api/embed 會將文字轉換為向量嵌入,常見於語意檢索或 RAG 系統:
curl http://localhost:11434/api/embed -d '{
"model": "mistral",
"input": "量化 (Quantization) 是什麼?"
}'
回傳範例:
{
"embedding": [
-0.0213, 0.1021, 0.3307, -0.1456, ...
]
}
透過這個端點,可以將文字轉換成向量表示,再存入向量資料庫,用於相似度搜尋與知識檢索。
Note
/api/generate與/api/chat預設為 流式輸出,需逐行讀取直到done:true。/api/embed則一次回傳完整向量。- API 預設僅能在本機存取,若要對外提供服務,請務必加上存取控制與安全性設定。
在完成 Ollama 的本地環境設定後,我們來動手實作一個簡單的 CLI 聊天機器人。這次不再依賴 OpenAI API,而是透過 LangChain 串接本地的 Ollama 模型,讓我們能在終端機中與 AI 助理即時互動。
範例中我們將使用 OpenAI 提供的開源模型 gpt-oss,請先透過 Ollama 將模型下載至本地:
ollama pull gpt-oss
Note:如果沒有特別指定版本標籤(tag),會自動下載
latest版本,目前對應到gpt-oss:20b。這個模型屬於輕量化版本,適合在個人電腦上運行。
在開始之前,請先初始化一個新的專案,命名為 local-llm-chatbot,我們將在這個專案中完成實作內容。
Note:如果你對 Node.js 專案初始化流程還不熟悉,可以先回顧 Day 01 中「建立 Node.js 專案與 TypeScript 開發環境」的內容。
建立專案環境後,請在專案根目錄中執行以下指令,安裝所需依賴套件:
npm install @langchain/core @langchain/ollama dotenv
這些套件的用途如下:
@langchain/core:LangChain 的核心模組,提供所有開發元件的共通介面與執行邏輯。@langchain/ollama:LangChain 提供的 Ollama 模型整合套件,能將本地 LLM 封裝為可呼叫的對話介面。dotenv:用來讀取 .env 檔案中的環境變數。在專案根目錄建立一個 .env 檔案,並填入以下內容,指定 Ollama API 伺服器的位置:
OLLAMA_BASE_URL=http://localhost:11434
Note:如果你使用
@langchain/ollama提供的ChatOllama,即使沒有特別指定baseUrl,也會自動連線到http://localhost:11434。不過,透過.env檔案設定可以讓專案更具可移植性,也方便日後切換不同的 API 伺服器位置。
接下來,我們撰寫一個互動式命令列程式,讓使用者可以在終端機中輸入訊息並即時獲得模型回覆。我們將透過 @langchain/ollama 提供的 ChatOllama,與本地部署的 LLM 進行互動。
請打開 src/index.ts 並輸入以下程式碼:
// src/index.ts
import 'dotenv/config';
import readline from 'readline';
import { ChatOllama } from '@langchain/ollama';
import { AIMessage, BaseMessage, HumanMessage, SystemMessage } from '@langchain/core/messages';
async function main() {
const llm = new ChatOllama({
model: 'gpt-oss',
baseUrl: process.env.OLLAMA_BASE_URL,
});
const messages: BaseMessage[] = [
new SystemMessage('你是一個樂於助人的 AI 助理。'),
];
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
console.log('Local LLM Chatbot 已啟動,輸入訊息開始對話(按 Ctrl+C 離開)。\n');
rl.setPrompt('> ');
rl.prompt();
rl.on('line', async (input) => {
messages.push(new HumanMessage(input));
try {
const stream = await llm.stream(messages);
let aiMessage = '';
process.stdout.write('\n');
for await (const chunk of stream) {
const content = chunk?.content ?? '';
process.stdout.write(content.toString());
aiMessage += content;
}
process.stdout.write('\n\n');
messages.push(new AIMessage(aiMessage));
} catch (err) {
console.error(err);
}
rl.prompt();
});
}
main();
在上述程式中,我們主要完成了以下工作:
ChatOllama 建立 LangChain 封裝的本地模型實例,並指定使用 gpt-oss。SystemMessage 設定助理的角色,並以 messages 陣列保存完整的對話上下文。HumanMessage 並加入 messages。llm.stream(messages) 以串流模式呼叫模型,逐步接收回覆。for await...of 即時輸出模型回應,同時將逐字輸出的內容累積為完整的 aiMessage。aiMessage 封裝為 AIMessage 加入 messages,確保後續對話能持續保持上下文。這樣我們就完成了一個最簡單的本地部署 LLM 的 CLI 聊天機器人,能即時與 GPT-OSS 模型互動。
完成程式後,就可以來測試看看效果了。在專案根目錄下執行以下指令啟動程式:
npm run dev
終端機會顯示以下訊息,代表聊天機器人已經啟動成功:
Local LLM Chatbot 已啟動,輸入訊息開始對話(按 Ctrl+C 離開)。
> Hello!
User: "Hello!" Very short greeting. Need friendly response.Hello! 👋 How can I help you today?
在這裡,我們使用的模型是 gpt-oss:20b。由於它屬於相對小型的模型,雖然能快速回應,但在語言流暢度與推理能力上,可能不如大型模型完整。此外,我們在 SystemMessage 中使用了中文提示,但模型本身並未特別針對中文做最佳化,因此回覆可能會出現中英文混雜或語氣不夠自然的情況。
Tip:若想比較不同模型的表現,可以先在 Ollama 中下載所需的模型,接著調整
ChatOllama的model參數(如llama3、mistral等),再重新執行程式,即可快速觀察各模型在回應速度與回答品質上的差異。
在 Day 19「打造可檢索公司年報的 AI 問答系統」 中,我們曾使用 OpenAI API 的雲端模型實作 RAG 系統。現在,我們要將這個專案改寫為 完全基於本地 LLM 的版本。因為對於有資料隱私或合規需求的企業來說,這樣的部署模式才是真正落地的典型應用場景。
在開始之前,你可以建立一個新專案,或直接沿用 Day 19 的程式範例,將專案更名為 local-llm-chatbot-with-rag。接下來的實作都會在這個專案中完成。
由於大多數開源語言模型主要以英文資料訓練,在中文場景下效果會打折扣,因此我們選擇在中文任務表現更佳的 qwen3 作為主要聊天模型。請先透過 Ollama 下載:
ollama pull qwen3
Note:為了方便演示,我們以官方提供的
qwen3模型作為示範。你也可以根據需求,改用其他針對中文應用場景進行過微調(Fine-tuning)的開源模型。
除了對話模型,我們還需要 嵌入模型(Embedding Model) 將文字轉換為向量,供後續檢索使用。對中文應用場景來說,這一環節同樣存在挑戰。根據 ihower 分享 使用繁體中文評測各家 Embedding 模型的檢索能力 的測試結果,bge-m3 是表現相對較佳的開源模型,因此我們選擇它作為本專案的嵌入模型,並同樣透過 Ollama 下載:
ollama pull bge-m3
當聊天模型與嵌入模型都準備好後,我們就能正式開始實作本地 RAG 問答系統。
建立專案環境後,請在專案根目錄中執行以下指令,安裝所需依賴套件:
npm install @langchain/core @langchain/ollama @langchain/qdrant @langchain/community pdf-parse langchain dotenv
這些套件的用途如下:
@langchain/core:LangChain 的核心模組,提供所有開發元件的共通介面與執行邏輯。@langchain/ollama:LangChain 提供的 Ollama 整合套件,其中包含 ChatOllama 與 OllamaEmbeddings,分別用於對話生成與向量嵌入。@langchain/qdrant:LangChain 的 Qdrant VectorStore 介面,讓我們能用一致的 API 存取/查詢 Qdrant 向量資料庫。@langchain/community::LangChain 社群維護的整合模組,包含各種資料來源的 Document Loader。這裡使用 PDFLoader 載入 PDF 檔案。pdf-parse:供 PDFLoader 使用的底層解析套件。langchain:LangChain 核心框架,提供 Chain、Tool、Retriever 等功能。dotenv:用來讀取 .env 檔案中的環境變數,例如 API 金鑰。在專案根目錄建立 .env 檔案,填入必要的設定:
OLLAMA_BASE_URL=
QDRANT_URL=
PDF_FILE_PATH=
各變數用途如下:
OLLAMA_BASE_URL:指定本地 Ollama 提供的 REST API 服務位址,預設為 http://localhost:11434。QDRANT_URL:Qdrant 服務的連線位址,預設本地執行會是 http://localhost:6333。PDF_FILE_PATH:指定要匯入的 PDF 文件路徑,本專案以公司年報為例。本地 RAG 專案的結構幾乎與 Day 19「打造可檢索公司年報的 AI 問答系統」 相同,只需要替換部分程式碼即可完成:
local-llm-chatbot-with-rag/
├── src/
│ ├── tools/ # 封裝工具模組
│ │ └── annual-report-retriever.tool.ts # 向量檢索封裝成 Tool
│ ├── vectorstores/ # 向量資料庫模組
│ │ └── qdrant.vectorstore.ts # 存取 Qdrant VectorStore
│ ├── index.ts # 程式進入點
│ └── ingest.ts # 一次性資料匯入流程
├── data/ # 公司年報 PDF 檔案放置處
├── package.json # 專案設定與依賴套件清單
├── tsconfig.json # TypeScript 編譯設定
└── .env # 環境變數設定
在這裡,我們只需要調整三個檔案:ingest.ts、qdrant.vectorstore.ts、index.ts。
首先修改 src/ingest.ts,將原本的 OpenAIEmbeddings 替換為 OllamaEmbeddings,並指定使用 bge-m3 模型:
// src/ingest.ts
import 'dotenv/config';
import { OllamaEmbeddings } from '@langchain/ollama';
import { QdrantVectorStore } from '@langchain/qdrant';
import { PDFLoader } from '@langchain/community/document_loaders/fs/pdf';
import { RecursiveCharacterTextSplitter } from 'langchain/text_splitter';
const filePath = process.env.PDF_FILE_PATH as string;
async function ingest() {
const loader = new PDFLoader(filePath);
const rawDocs = await loader.load();
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200,
});
const docs = await splitter.splitDocuments(rawDocs);
const embeddings = new OllamaEmbeddings({
model: 'bge-m3',
baseUrl: process.env.OLLAMA_BASE_URL,
});
await QdrantVectorStore.fromDocuments(docs, embeddings, {
url: process.env.QDRANT_URL,
collectionName: 'annual-report',
});
console.log('done');
}
ingest();
然後執行以下指令,將 PDF 年報轉換並匯入 Qdrant:
npm run ingest
接著修改 src/vectorstores/qdrant.vectorstore.ts,同樣將 OpenAIEmbeddings 替換為 OllamaEmbeddings,並指定使用 bge-m3 模型:
// src/vectorstores/qdrant.vectorstore.ts
import { QdrantVectorStore } from '@langchain/qdrant';
import { OllamaEmbeddings } from '@langchain/ollama';
let vectorStore: QdrantVectorStore | null = null;
export const getVectorStore = async () => {
if (vectorStore) {
return vectorStore;
}
const embeddings = new OllamaEmbeddings({
model: 'bge-m3',
baseUrl: process.env.OLLAMA_BASE_URL,
});
vectorStore = await QdrantVectorStore.fromExistingCollection(embeddings, {
url: process.env.QDRANT_URL,
collectionName: 'annual-report'
});
return vectorStore;
};
最後,修改 src/index.ts,將原本的 ChatOpenAI 改為 ChatOllama,並指定 qwen3 作為主要對話模型:
// src/index.ts
import 'dotenv/config';
import readline from 'readline';
import { ChatOllama } from '@langchain/ollama';
import { BaseMessage, HumanMessage, SystemMessage } from '@langchain/core/messages';
import { getRetrieverTool } from './tools/retriever.tool';
async function main() {
const llm = new ChatOllama({
model: 'qwen3',
baseUrl: process.env.OLLAMA_BASE_URL,
});
const retrievalTool = await getRetrieverTool();
const llmWithTools = llm.bindTools([retrievalTool]);
const messages: BaseMessage[] = [
new SystemMessage('你是一個樂於助人的 AI 助理。'),
];
const toolsByName: Record<string, any> = {
[retrievalTool.name]: retrievalTool,
};
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
console.log('Local LLM Chatbot 已啟動,輸入訊息開始對話(按 Ctrl+C 離開)。\n');
rl.setPrompt('> ');
rl.prompt();
rl.on('line', async (input) => {
try {
const humanMessage = new HumanMessage(input);
messages.push(humanMessage);
const aiMessage = await llmWithTools.invoke(messages);
messages.push(aiMessage);
const toolCalls = aiMessage.tool_calls || [];
if (toolCalls.length) {
for (const toolCall of toolCalls) {
const selectedTool = toolsByName[toolCall.name];
const toolMessage = await selectedTool.invoke(toolCall);
messages.push(toolMessage);
}
const followup = await llmWithTools.invoke(messages);
messages.push(followup);
}
const lastMessage = messages.slice(-1)[0];
console.log(`${lastMessage.content}\n`);
} catch (err) {
console.error(err);
}
rl.prompt();
});
}
main();
可以看到,除了將聊天模型換成 qwen3、嵌入模型換成 bge-m3,整體程式邏輯幾乎不需要修改。這正是使用 LangChain 的優點:只需替換元件即可完成模型切換,無須重寫整個流程。
當所有程式碼都完成後,就可以啟動專案來驗證整個問答流程是否正常運作。在此之前,請先確認已經執行過 資料匯入流程,並且 Qdrant 服務已啟動,否則檢索功能將無法正常運作。
由於我們已在 package.json 中設定了 dev 指令,在開發階段可以直接使用以下命令啟動:
npm run dev
啟動後,終端機會顯示提示字元 > ,代表聊天機器人已經就緒。此時你可以輸入任何與公司年報相關的問題,例如:
Local LLM Chatbot 已啟動,輸入訊息開始對話(按 Ctrl+C 離開)。
> 2024 年公司的營收是多少?請用繁體中文回答。
Tip:由於 Qwen 模型主要以簡體中文資料訓練,若希望輸出為繁體中文,可以在提示中明確指定回答語言。
以下為輸出範例:
<think>
好的,用户问的是2024年的营收,我需要从提供的工具响应中找到相关信息。首先,我看到工具返回的内容中有多个数据点,需要仔细筛选。
首先注意到用户的问题是关于2024年的,但工具响应中有提到“民國一百一十二年度營業報告書”和“民國一百一十三年”,这可能对应的是2023年和2024年的数据。需要确认时间对应关系。例如,民國一百一十二年是2023年,民國一百一十三年是2024年。
在工具响应中,有一段提到:“全年合併營收約為新台幣2兆1,617億4,000萬元”,这里明确提到了2023年的营收数据。接着,另一段提到“2024年公司的營收是多少?”对应的可能数据在后面的部分,但需要仔细查找。
继续查看,发现有一段提到“2024年公司的營收是多少?”对应的回答部分,其中提到“合併營收新台幣2兆8,943億1,000萬元”,这里明确是2024年的数据。因此,正确的答案应该是2024年的营收为新台币2兆8,943亿1,000万元,即2.89431兆元。
需要确认是否有其他数据可能混淆,比如后面的“全年合併營收約為新台幣2兆1,617億4,000萬元”是2023年的数据,而2024年的数据是后面的2兆8,943亿。因此,最终答案应为2024年营收2兆8,943亿1,000万元。
</think>
2024年公司的合併營收為新台幣 **2兆8,943億1,000萬元**,較前一年增長33.9%,創下歷史新高。
可以觀察到,LLM 在過程中透過工具檢索了年報內容,並根據檢索到的資料生成最終答案。
這樣,我們就完成了 基於本地 LLM 的 RAG 應用。透過 Ollama 提供的模型整合,我們將原本依賴雲端模型的應用順利遷移到本地環境,並同時保留完整的檢索與問答流程。
今天我們快速上手了 Ollama,並在本地完成了一個可即時互動的 CLI 聊天機器人,以及基於本地 LLM 的 RAG 應用:
run、pull、list、show、ps、stop、rm,涵蓋下載、啟動、管理與移除模型。/api/generate、/api/chat、/api/embed,能支援單次生成、多輪對話與文字向量化。ChatOllama,我們實作一個本地的 CLI 聊天機器人,支援多輪互動與串流回應。qwen3 與 bge-m3 模型與 Qdrant 向量資料庫,打造隱私、安全且可控的檢索系統。整體而言,Ollama 讓本地部署 LLM 的門檻大幅降低,從下載模型到整合應用僅需數分鐘,就能快速進行學習、實驗與原型開發,是探索本地 AI 應用的理想工具。
本系列文已正式出版為《Node.js 生成式 AI 應用開發實戰:實作 OpenAI API × LangChain × LangGraph × RAG,打造從雲端到本地 LLM 的混合式安全架構》。內容全面升級,提供更完整的實戰範例與 LLM 應用架構設計。歡迎參考選購,開啟你的生成式 AI 開發之路!
天瓏網路書店連結:https://www.tenlong.com.tw/products/9786264144964



 iThome鐵人賽
iThome鐵人賽