
在本系列中,我們已經嘗試過使用 OpenAI API 的雲端模型,以及透過 Ollama 建立本地模型服務。這兩種方式各有優缺點:雲端模型能夠隨時更新、效能穩定,但成本與隱私是需要考量的地方;本地模型則擁有更高的控制權與安全性,但可能受限於硬體資源與模型效能。
那麼,如果我們想要同時兼顧兩者優勢,是否能設計一個「混合架構」?答案是肯定的。今天,我們將透過 LiteLLM 建立一個能夠同時調用雲端與本地模型的多模型代理層,為 AI 應用打造更彈性的執行環境。
當 AI 應用從實驗階段邁向實際部署與營運,開發者往往會遇到更多元且複雜的挑戰,必須在 成本、效能、穩定性與資安 之間找到平衡。這也引出一個核心問題:雲端模型與本地模型如何共存,並且在同一個應用環境中協同運作? 以下是幾個典型情境:
歸結而言,這些挑戰指向同一個需求:應用程式需要能在不同模型間靈活切換,並在雲端與本地共存的情境下維持一致的 LLM 環境。
為了實現這一點,我們需要一個能整合多種 LLM,並對外提供 統一 API 介面 的中介層。這正是「多模型代理架構」存在的核心價值,也是它能夠幫助 AI 應用真正落地的原因。
LiteLLM 是一個專注於 統一大語言模型介面 (LLM Proxy / Gateway) 的服務。它的核心理念是:開發者不必受限於單一廠商或 API,只要對接 LiteLLM,就能在不同模型與供應商間自由切換。這大幅降低了應用程式與模型的耦合度,並為系統帶來更高的擴展性。
LiteLLM 的主要特點包括:
openai SDK 的程式碼只需更換 API Base 與金鑰即可接入,大多數情況下無需調整程式邏輯。換句話說,應用程式只需串接 LiteLLM Proxy 提供的統一端點,不論背後實際使用的是 OpenAI、Claude,還是本地 Ollama 模型,都能在不改變應用邏輯的前提下進行切換,真正實現了後端模型的可插拔式設計。
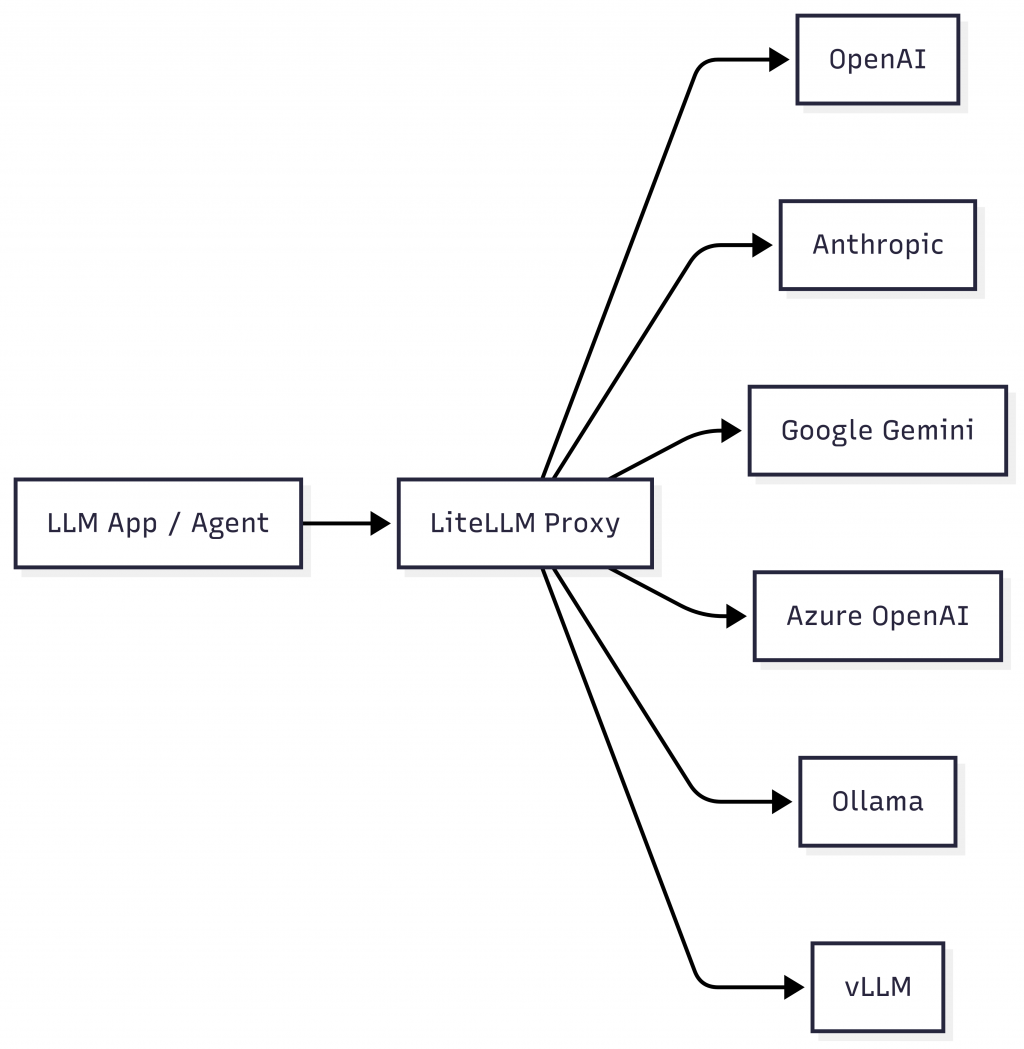
如你所見,LiteLLM 的出現,不僅簡化了 LLM 整合的複雜度,也讓雲端與本地模型能在同一個共存環境中協同運作,是建構多模型 AI 應用時不可或缺的基礎工具。接下來,我們將實際操作如何使用 Docker 部署 LiteLLM 並整合各種模型來源。
在本節,我們將透過 Docker Compose 快速部署 LiteLLM Proxy,並使用一份設定檔來集中管理多個模型的接入方式。這樣能讓應用程式只需對接 LiteLLM 的統一端點,而不必一一串接各家模型的 API。
docker-compose.yml首先,在專案根目錄下建立 docker-compose.yml。你可以參考 LiteLLM 官方 Github 倉庫的 docker-compose.yml 範例檔案。以下是簡化並調整後的設定:
services:
litellm:
image: ghcr.io/berriai/litellm:main-stable
volumes:
- ./config.yaml:/app/config.yaml
command:
- "--config=/app/config.yaml"
ports:
- "4000:4000" # 對映容器的 4000 埠到主機,可依需求調整
environment:
DATABASE_URL: "postgresql://llmproxy:dbpassword9090@db:5432/litellm"
STORE_MODEL_IN_DB: "True" # 允許透過 UI 新增模型
env_file:
- .env # 載入本地 .env 檔案
depends_on:
- db
healthcheck:
test: [ "CMD-SHELL", "wget --no-verbose --tries=1 http://localhost:4000/health/liveliness || exit 1" ]
interval: 30s
timeout: 10s
retries: 3
start_period: 40s
db:
image: postgres:16
restart: always
container_name: litellm_db
environment:
POSTGRES_DB: litellm
POSTGRES_USER: llmproxy
POSTGRES_PASSWORD: dbpassword9090
ports:
- "5432:5432"
volumes:
- postgres_data:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -d litellm -U llmproxy"]
interval: 1s
timeout: 5s
retries: 10
volumes:
postgres_data:
name: litellm_postgres_data
Note:官方版本中還包含 Prometheus 監控的設定,本範例省略了該部分。若有監控需求,可依情境加入。
config.yaml接著,在相同目錄建立 config.yaml,定義 LiteLLM Proxy 的模型清單:
model_list:
- model_name: openai/gpt-4o-mini
litellm_params:
model: gpt-4o-mini
api_key: os.environ/OPENAI_API_KEY
- model_name: ollama/gpt-oss:20b
litellm_params:
model: ollama/gpt-oss:20b
api_base: "http://host.docker.internal:11434"
此設定會在 LiteLLM 啟動時載入,並註冊模型代理服務。以上例子包含兩個模型:
gpt-4o-mini:model_name 應用程式呼叫時使用的別名(例:openai/gpt-4o-mini)。model 實際的模型名稱。api_key 設定 os.environ/OPENAI_API_KEY,表示 LiteLLM 會自 .env 或系統環境變數中讀取 OPENAI_API_KEY 的值。gpt-oss:20b:model_name 應用程式呼叫時使用的別名(例:ollama/gpt-oss:20b)。model:實際使用的 Ollama 模型。api_base:模型 API 位址。由於 LiteLLM 在 Docker 容器中運行,要連線宿主機上的 Ollama,需透過 host.docker.internal:11434。Note:請先確保本地的 Ollama 已安裝並下載
gpt-oss:20b模型。
透過這份設定,LiteLLM 會在啟動時自動註冊代理服務,應用程式只需指定 model_name 即可使用對應模型,而不必各自處理不同的 SDK 與 API 格式。
.env在相同目錄中新增 .env 檔案,用於儲存 API 金鑰與必要設定。可參考官方的 .env.example 。範例如下:
# OpenAI
OPENAI_API_KEY = "sk-xxxxx..."
# Development Configs
LITELLM_MASTER_KEY = "sk-1234"
DATABASE_URL = "postgresql://llmproxy:dbpassword9090@db:5432/litellm"
STORE_MODEL_IN_DB = "True"
其中 LITELLM_MASTER_KEY 將作為 LiteLLM Admin Panel 的管理員密碼。
確認設定無誤後,執行以下指令:
docker compose up -d
啟動完成後,LiteLLM 會監聽在 http://localhost:4000,並提供符合 OpenAI 格式的 /v1/chat/completions API。
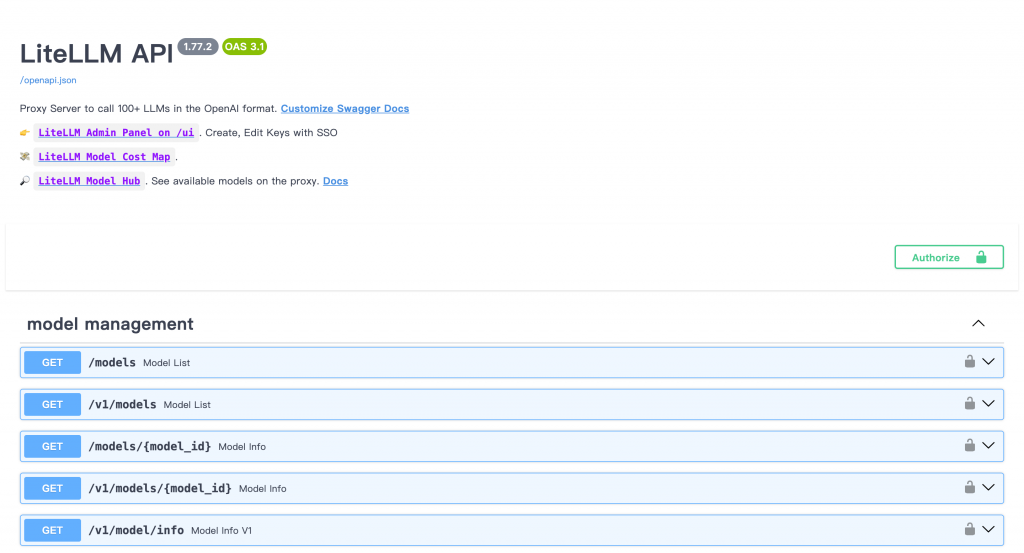
你可以透過以下網址進行測試與管理:
http://localhost:4000:查看 API 文件。http://localhost:4000/ui/:進入 LiteLLM Admin Panel(金鑰管理、模型監控)。首次進入 Admin Panel 會要求登入,帳號為 admin,密碼則是 .env 檔中設定的 LITELLM_MASTER_KEY(此例為 sk-1234)。
完成以上步驟後,我們就成功在本地環境啟動了一個可同時管理雲端與本地模型的 LiteLLM Proxy。接下來,我們將透過 LiteLLM Admin Panel 建立虛擬金鑰,讓應用程式能以安全、可控的方式存取不同模型。
完成 LiteLLM Proxy 的部署後,下一步就是確保應用程式能以安全且可控的方式呼叫這些模型。LiteLLM 提供 虛擬金鑰(Virtual Key) 機制,讓你能針對不同用途發放金鑰,並設定存取範圍與使用限制。
登入 LiteLLM Admin Panel 後,切換到 Virtual Keys 頁面,點選「Create New Key」。
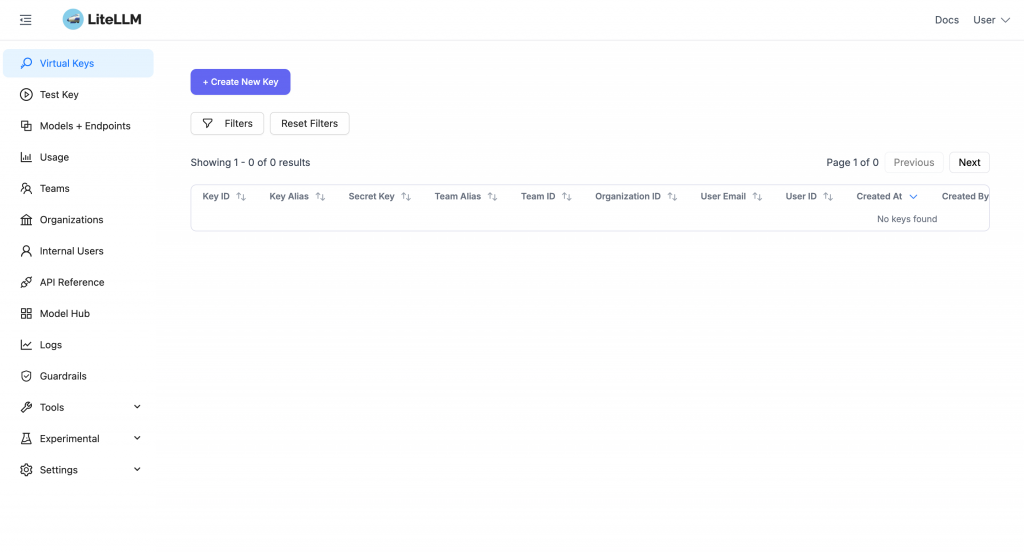
輸入金鑰名稱,並選擇允許使用的模型。
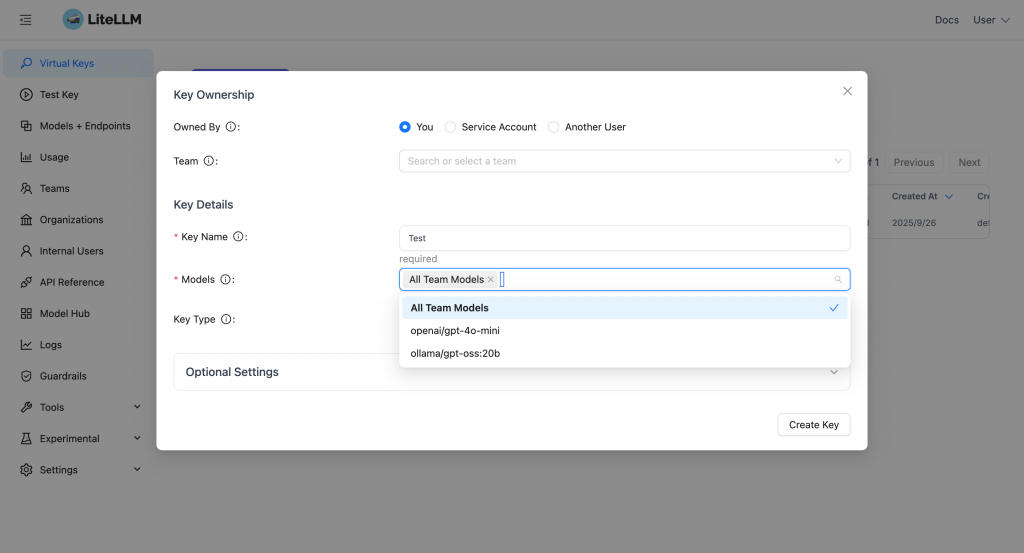
由於我們先前在 config.yaml 中設定了 openai/gpt-4o-mini 與 ollama/gpt-oss:20b,系統會自動列出這些模型。
確認金鑰名稱與可使用模型等設定無誤後,點擊「Create Key」按鈕,即可生成一組新的虛擬金鑰。系統會隨即顯示金鑰字串,這是應用程式呼叫 LiteLLM Proxy 時所必須使用的憑證。
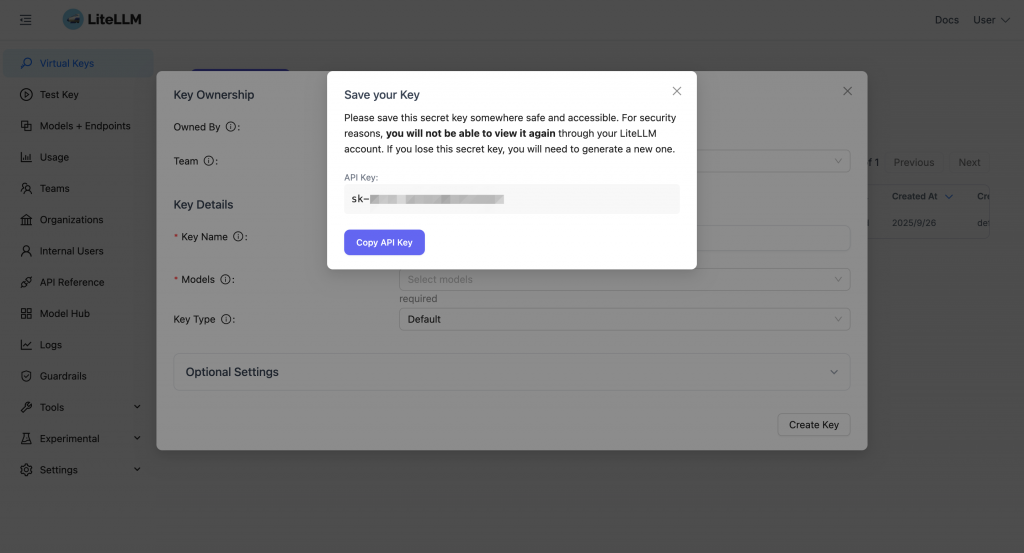
注意:金鑰在建立後只會顯示一次,請務必立即複製並妥善保存,建議將它放入
.env檔案或安全的金鑰管理工具中。若日後遺失,必須重新建立新的金鑰。
完成虛擬金鑰的建立後,應用程式就能透過這些金鑰來安全存取 LiteLLM Proxy,接下來我們將實際用 curl 測試是否能成功呼叫不同的模型服務。
LiteLLM 採用與 OpenAI 完全相容的 API 格式,因此可以直接使用熟悉的 curl 指令驗證是否成功對接模型。以下我們分別測試雲端與本地模型。
gpt-4o-mini 模型執行以下指令,確認能否正確呼叫雲端的 OpenAI 模型:
curl -X POST http://localhost:4000/v1/chat/completions \
-H 'Authorization: Bearer sk-xxxxx-xxxxxxxxxxxxxxxx' \
-H 'Content-Type: application/json' \
-d '{
"model": "openai/gpt-4o-mini",
"messages": [
{ "role": "system", "content": "你是一個樂於助人的 AI 助理。" },
{ "role": "user", "content": "請簡單說明什麼是多模型代理架構?" }
]
}'
若設定正確,應會得到模型生成的回應。
gpt-oss:20b 模型接著,執行以下指令測試本地 Ollama 模型是否能被 Proxy 呼叫:
curl -X POST http://localhost:4000/v1/chat/completions \
-H 'Authorization: Bearer sk-xxxxx-xxxxxxxxxxxxxxxx' \
-H 'Content-Type: application/json' \
-d '{
"model": "ollama/gpt-oss:20b",
"messages": [
{ "role": "system", "content": "你是一個樂於助人的 AI 助理。" },
{ "role": "user", "content": "請簡單說明什麼是多模型代理架構。" }
]
}'
如果模型已正確載入並啟動,你會看到來自本地模型的回應。
若測試過程中出現錯誤,可以依下列方向排查:
.env 檔案與金鑰是否設定正確。完成以上測試後,即可確認 LiteLLM 已成功運作。此時你的應用程式就能透過 統一的 Proxy 端點,靈活切換雲端與本地模型。
經過前面的部署、金鑰建立與 API 測試,我們已經確認 LiteLLM Proxy 可以正常整合雲端與本地模型。接下來,就可以把它實際接入 LangChain,讓應用程式透過統一的介面直接調用多模型服務。
由於 LiteLLM 與 OpenAI API 高度相容,你可以直接透過 @langchain/openai 套件呼叫 LiteLLM。換句話說,原本串接 OpenAI 的程式邏輯幾乎不需任何調整,就能無縫切換到 LiteLLM Proxy。
在建立 LangChain 模型實例時,只需指定 LiteLLM Proxy 的 API 位址 與 對應的 model 名稱 即可:
import 'dotenv/config';
import { ChatOpenAI } from '@langchain/openai';
const llm = new ChatOpenAI({
configuration: {
baseURL: 'http://localhost:4000/v1', // LiteLLM Proxy 的 API 端點
},
model: 'ollama/gpt-oss:20b', // 對應 config.yaml 中的 model_name
apiKey: process.env.LITELLM_API_KEY, // 使用虛擬金鑰或 LiteLLM Admin 發放的金鑰
});
呼叫方式與一般 OpenAI 模型完全一致。例如:
const response = await llm.invoke([
{ role: 'system', content: '你是一個樂於助人的 AI 助理。' },
{ role: 'user', content: '請簡單說明什麼是多模型代理架構?' },
]);
console.log(response.content);
輸出的結果會依照你在 config.yaml 中所設定的模型來源(雲端或本地)而改變,但程式碼邏輯保持一致。
這樣的架構帶來幾個好處:
model 參數,就能自由切換雲端或本地模型。。config.yaml,應用程式端維持不變。。透過這樣的整合方式,LLM 應用不再受限於單一模型,而能在 LiteLLM 的代理層下隨插即用,真正實現彈性、穩定又可擴充的多模型架構。
今天我們透過 LiteLLM 示範了如何打造一個能同時使用雲端與本地模型的「多模型代理架構」,讓 AI 應用具備更高的彈性與穩定性:
總而言之,LiteLLM 讓多模型應用不再是繁瑣的整合工程,而是可快速搭建的基礎設施,協助團隊在不同場景下靈活切換模型,真正實現「一套應用,隨插即用」。
至此,本系列的 30 天內容也正式告一段落。希望透過這個系列,你能逐步建立起完整的 AI 應用開發藍圖,從最基本的 OpenAI API,到進階的 LangChain、RAG、AI Agent,再到本地與混合模型架構,最終能打造出屬於自己的智慧應用。
本系列文已正式出版為《Node.js 生成式 AI 應用開發實戰:實作 OpenAI API × LangChain × LangGraph × RAG,打造從雲端到本地 LLM 的混合式安全架構》。內容全面升級,提供更完整的實戰範例與 LLM 應用架構設計。歡迎參考選購,開啟你的生成式 AI 開發之路!
天瓏網路書店連結:https://www.tenlong.com.tw/products/9786264144964


 iThome鐵人賽
iThome鐵人賽