setup
# pip install llama-index-utils-workflow
# TAVILY_API_KEY, OPENAI_API_KEY
import os
from dotenv import find_dotenv, load_dotenv
_ = load_dotenv(find_dotenv())
pip install llama-index-utils-workflow,用來可視化定義出來的 workflow.env 檔案需要有 tavily 和 openai 的 api keyworkflow
Event
from llama_index.core.workflow import Event
from llama_index.core.schema import Document, NodeWithScore
class SearchEvent(Event):
"""Result of travily search"""
docs: list[Document]
class CreateCitationsEvent(Event):
"""Add citations to the nodes."""
nodes: list[NodeWithScore]
# CITATION_QA_TEMPLATE, CITATION_REFINE_TEMPLATE,
# DEFAULT_CITATION_CHUNK_SIZE = 512
# DEFAULT_CITATION_CHUNK_OVERLAP = 20
from llama_index.core.prompts import PromptTemplate
CITATION_QA_TEMPLATE_EN = PromptTemplate(
"Please provide an answer based solely on the provided sources. "
"When referencing information from a source, "
"cite the appropriate source(s) using their corresponding numbers. "
"Every answer should include at least one source citation. "
"Only cite a source when you are explicitly referencing it. "
"If none of the sources are helpful, you should indicate that. "
"For example:\n"
"Source 1:\n"
"The sky is red in the evening and blue in the morning.\n"
"Source 2:\n"
"Water is wet when the sky is red.\n"
"Query: When is water wet?\n"
"Answer: Water will be wet when the sky is red [2], "
"which occurs in the evening [1].\n"
"Now it's your turn. Below are several numbered sources of information:"
"\n------\n"
"{context_str}"
"\n------\n"
"Query: {query_str}\n"
"Answer: "
)
CITATION_QA_TEMPLATE = PromptTemplate(
"請僅根據所提供的來源回答問題。"
"在引用某個來源的資訊時,"
"請使用對應的編號來標註來源。"
"每個答案都必須至少包含一個來源的引用。" # 答案 / 陳述句
"僅在明確引用該來源時才標註來源。"
"如果沒有任何來源有幫助,你應該指出這一點。" # 所以其實自帶了 filter
"例如:\n"
"來源 1:\n"
"如果一隻土撥鼠會丟木頭,那牠能丟的木頭量,就等於「一隻會丟木頭的土撥鼠所能丟的木頭量」。\n"
"來源 2:\n"
"哪有土撥鼠真的會丟木頭。\n"
"問題:一隻土撥鼠如果會丟木頭,那牠能丟多少木頭?\n"
"答案:一般來說,土撥鼠其實並不會真的丟木頭 [2]。"
"不過如果牠真的會丟木頭,那牠能丟的數量,就等於一隻會丟木頭的土撥鼠所能丟的數量 [1]。\n"
"現在輪到你了。以下是數個已編號的資訊來源:"
"\n------\n"
"{context_str}"
"\n------\n"
"問題:{query_str}\n"
"答案:"
)
CITATION_REFINE_TEMPLATE_EN = PromptTemplate(
"Please provide an answer based solely on the provided sources. "
"When referencing information from a source, "
"cite the appropriate source(s) using their corresponding numbers. "
"Every answer should include at least one source citation. "
"Only cite a source when you are explicitly referencing it. "
"If none of the sources are helpful, you should indicate that. "
"For example:\n"
"Source 1:\n"
"The sky is red in the evening and blue in the morning.\n"
"Source 2:\n"
"Water is wet when the sky is red.\n"
"Query: When is water wet?\n"
"Answer: Water will be wet when the sky is red [2], "
"which occurs in the evening [1].\n"
"Now it's your turn. "
"We have provided an existing answer: {existing_answer}"
"Below are several numbered sources of information. "
"Use them to refine the existing answer. "
"If the provided sources are not helpful, you will repeat the existing answer."
"\nBegin refining!"
"\n------\n"
"{context_msg}"
"\n------\n"
"Query: {query_str}\n"
"Answer: "
)
CITATION_REFINE_TEMPLATE = PromptTemplate(
"請僅根據所提供的來源來生成答案。"
"在引用來源中的資訊時,"
"請使用對應的來源編號進行標註。"
"每個答案都必須至少包含一個來源引用。"
"僅在你明確參考來源時才進行引用。"
"如果提供的來源沒有幫助,你應該直接重複既有的答案。"
"例如:\n"
"來源 1:\n"
"如果一隻土撥鼠會丟木頭,那牠能丟的木頭量,就等於「一隻會丟木頭的土撥鼠所能丟的木頭量」。\n"
"來源 2:\n"
"哪有土撥鼠真的會丟木頭。\n"
"問題:一隻土撥鼠如果會丟木頭,那牠能丟多少木頭?\n"
"答案:一般來說,土撥鼠其實並不會真的丟木頭 [2]。"
"不過如果牠真的會丟木頭,那牠能丟的數量,就等於一隻會丟木頭的土撥鼠所能丟的數量 [1]。\n"
"現在輪到你了。"
"這裡有一個既有答案:{existing_answer}\n"
"以下是幾個編號的資訊來源。"
"請使用這些來源來改進既有的答案。"
"如果來源沒有幫助,你就直接重複既有答案。"
"\n開始改進!"
"\n------\n"
"{context_msg}"
"\n------\n"
"問題:{query_str}\n"
"答案:"
)
DEFAULT_CITATION_CHUNK_SIZE = 512
DEFAULT_CITATION_CHUNK_OVERLAP = 20
class CitationQueryEngineWorkflow(Workflow):
@step
async def search(
self, ctx: Context, ev: StartEvent
) -> Union[SearchEvent, None]:
"Entry point for RAG, triggered by a StartEvent with `query`."
query = ev.get("query")
if not query:
return None
print(f"Query the tavily with: {query}")
# store the query in the global context
await ctx.store.set("query", query)
docs = tavily_tool.search(query, max_results=3)
print(f"get {len(docs)} docs.")
return SearchEvent(docs=docs)
@step
async def create_citation_nodes(
self, ev: SearchEvent
) -> CreateCitationsEvent:
"""
Returns:
List[NodeWithScore]: A list of NodeWithScore objects, where each object
represents a smaller chunk of the original docs, labeled as a source.
"""
docs = ev.docs
nodes: List[NodeWithScore] = []
text_splitter = SentenceSplitter(
chunk_size=DEFAULT_CITATION_CHUNK_SIZE,
chunk_overlap=DEFAULT_CITATION_CHUNK_OVERLAP,
)
for doc in docs:
text_chunks = text_splitter.split_text(
doc.get_content(metadata_mode=MetadataMode.NONE)
)
for text_chunk in text_chunks:
text = f"Source {len(new_nodes)+1}:\n{text_chunk}\n"
text_node = TextNode(
text=text,
metadata=doc.metadata,
id_=doc.doc_id # 注意:Document 有 doc_id 屬性
)
node = NodeWithScore(node=text_node, score=1.0)
nodes.append(node)
return CreateCitationsEvent(nodes=nodes)
@step
async def synthesize(
self, ctx: Context, ev: CreateCitationsEvent
) -> StopEvent:
"""Return a streaming response using the retrieved nodes."""
llm = OpenAI(model="gpt-5-mini")
query = await ctx.store.get("query", default=None)
synthesizer = get_response_synthesizer(
llm=llm,
text_qa_template=CITATION_QA_TEMPLATE,
refine_template=CITATION_REFINE_TEMPLATE,
response_mode=ResponseMode.COMPACT,
use_async=True,
)
response = await synthesizer.asynthesize(query, nodes=ev.nodes)
return StopEvent(result=response)
from llama_index.utils.workflow import draw_all_possible_flows
draw_all_possible_flows(
CitationQueryEngineWorkflow,
filename="Search_CitationQueryEngine_Workflow.html",
# Optional, can limit long event names in your workflow
# Can help with readability
# max_label_length=10,
)
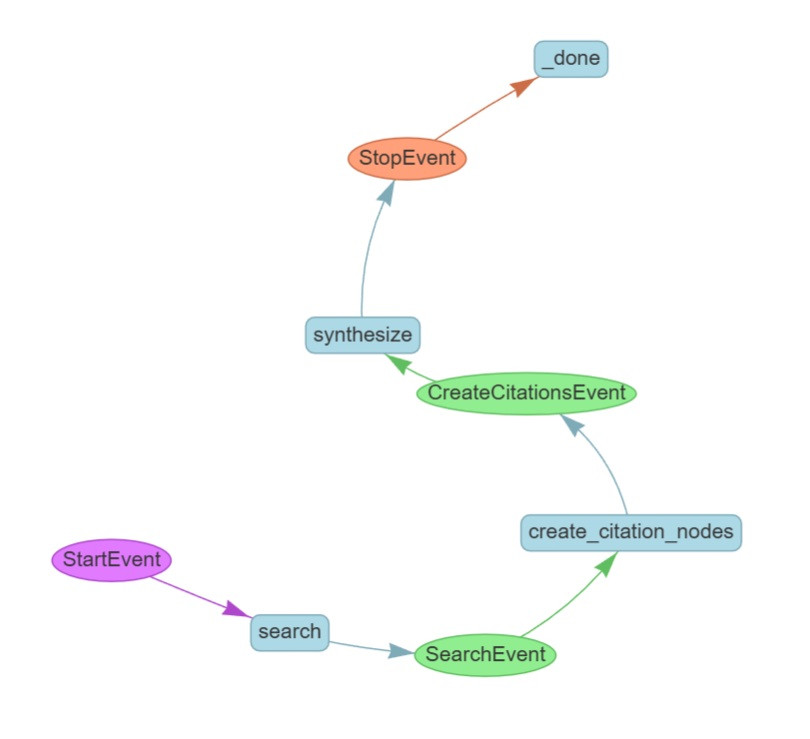
w = CitationQueryEngineWorkflow()
# Run a query
query = '徵象(Signs)及症狀(Symptoms)之區別?'
result = await w.run(query=query)
print(result.response)
Query the tavily with: 徵象(Signs)及症狀(Symptoms)之區別?
get 3 docs.
'答案:\n\n- 症狀(Symptoms):指病人主觀感受或陳述的異常經驗,例如覺得發燒、頭痛、麻木或疼痛等,這些是來自病人的主觀描述 [1][3]。症狀有時為非特異性(例如疲倦可見於多種疾病或正常勞累後)[3]。\n\n- 徵象/體徵(Signs):指可被外部觀察或客觀檢查到的發現,例如肌肉紅腫、體溫異常、血壓偏高或在影像檢查中看到的異常,通常可被測量或由醫師觀察確認。有些徵象病人本身可能察覺不到(如高血壓、血糖超標),但對診斷與治療很重要 [1][2]。\n\n- 二者的主要區別:症狀為病人的主觀感受,出現在病史中;徵象為客觀可觀察或測量的發現,會出現在病史與理學檢查中(即可由醫師在檢查時確認)[3]。'
print(result.source_nodes[0].node.get_text())
print(result.source_nodes[2].node.get_text())
Source 1:
維基百科,自由的百科全書
| |
| 此條目可參照英語維基百科相應條目來擴充。若您熟悉來源語言和主題,請協助參考外語維基百科擴充條目。請勿直接提交機械翻譯,也不要翻譯不可靠、低品質內容。依版權協議,譯文需在編輯摘要註明來源,或於討論頁頂部標記`{{Translated page}}`標籤。 |
症狀和徵候(symptoms and signs)是有關疾病、創傷或是其他醫學狀況,患者經歷到的症狀(symptom),以及可以觀測到的徵候(sign)。症狀是患者所述的主觀體驗;而徵候是客觀,可以外部偵測到的。
症狀是患者主觀感受,例如感覺發燒、頭痛、麻痹或是身體其他部分的疼痛;徵候的例子則包括肌肉紅腫、體溫偏高或偏低,血壓偏高或偏低,或是在醫學影像檢查中發現的異常情形。。
Source 3:
例如疲倦是許多急性或慢性疾病的特徵,可能是心理疾病,也可能不是,可能是初次症狀,也可能是二次症狀。疲倦也是一個人在經過勞累或是一天結束後所會有的正常反應。
### 活性及負性症狀
[編輯]
精神疾病的症狀(特別是思覺失調症的症狀)可以分為活性症狀及負性症狀。 [...] 有些症狀只有病人本身感知,然而徵候卻有可能被病人以外的人察覺到。兩者之間的差異和病史及理學檢查之間的差異有些關係。症狀只會在病史中出現,而徵候會出現在病史及理學檢查中。像是皮疹和肌肉顫動等臨床徵候(clinical sign)是病人及其他人都可以察覺的。有些徵候需要醫學上的專業才會知道,因此只會在理學檢查中出現。例如低血鈣或是嗜中性白血球低下都需要血液檢查才可得知。


 iThome鐵人賽
iThome鐵人賽