延續昨天的討論:
基於上述觀察,一個自然的想法是:在一開始使用 Wiki 檢索後,就立即驗證是否有找到相關結果
這種在推理階段(inference time)就直接完成驗證的方式,我們稱為 online
今天的任務一樣是三步:
首先這是我們 online evaluator 的 prompt:
from llama_index.core.prompts import PromptTemplate
RETRIEVAL_EVALUATOR_PROMPT = PromptTemplate(
template="""你是一個具備判斷 retrieval 資料完整性與可靠性的助手。
輸入:
- query(string):一題單選題(例如 題目: 常見針灸配穴法中,所指的「四關穴」,為下列何穴位之組合?\n選項:\n A: 上星、日月\n B: 合谷、太衝\n C: 內關、外關\n D: 上關、下關\n)
- context(string):經過 Wiki 或其它來源檢索到的 text 資料,用來支持回答這個 query
你的任務是:
1. 判斷這個 context 是否已經足夠用來「正確地回答」這個單選題(correct),或是不行(incorrect)、或是有模糊性(ambiguous)。
2. 輸出一個 JSON 物件,格式如下:
{
"verdict": "<correct 或 incorrect 或 ambiguous>",
"next_query": "<可選的重寫 query,用於進一步檢索;當判斷是 correct 時可為空字串或 null>"
}
* 若判斷為 **correct**,表示 context 足夠回答問題,`next_query` 可以設為 `""` 或 `null`。
* 若判斷為 **incorrect**,表示 context 與題意不匹配、或根本無法支撐任何選項,`next_query` 要提供一個你幫我重寫(或擴增)的 query,我會拿它去做新的檢索。
* 若判斷為 **ambiguous**,表示 context 有部分相關性但仍有不確定性,或答案可能不唯一,這時 `next_query` 也是必須的:你提供一個 query,用來補充搜索。未來當我拿新的檢索結果補充時,我會把原 context 與新的結果 concat 在一起,再讓你重做這個判斷流程。
**注意事項:**
* `判斷標籤` 的三種情況應該代表不同策略:
• **correct**:context 已經明確支持某個選項,沒有爭議或缺漏
• **incorrect**:context 與題目方向錯誤(例如回答了另一個問題、講了題目沒有問的範圍)
• **ambiguous**:context 涉及題目相關內容,但缺少關鍵細節或多種可能性尚未排除
* 在決定 `next_query` 時,盡量把 query 重寫得更具體/更具針對性(可加入關鍵詞)以便後續檢索能補足缺口
* 輸出 JSON 時,**只有這兩個欄位**,不要額外說明或多餘包裝文字
---
### 範例
query = "哪一年諾貝爾獎創立?"
context = "諾貝爾獎是瑞典的獎項,始於十九世紀末…在 1901 年頒發第一屆。"
輸出:
{
"verdict": "correct",
"next_query": null
}
query = "哪一年諾貝爾獎創立?"
context = "諾貝爾獎由阿爾弗雷德·諾貝爾設立"
輸出:
{
"verdict": "ambiguous",
"next_query": "諾貝爾獎 第一屆 頒發 年份"
}
若 context 完全與題目無關,標記為 incorrect,並重寫一個可能的 query。
----------以下開始
query = {query}
context = {context}"""
)
這邊我們把 context relevancy 的結果區分為三種情況:
correct: context 已經包含足夠回答單選題的所有資訊
ambiguous: context 可能有相關,但仍然沒辦法回答問題
next_query 用來進行下一輪的檢索incorrect: 前一步的檢索與答案完全無關
next_query
這邊這個 correct, ambiguous, incorrect 的想法來自 Corrective RAG
我們直接開啟 json mode 方便我們後續的處置,以下是執行結果:
{'verdict': 'incorrect', 'next_query': '四關穴是哪些穴位組合?(查詢:四關穴 合谷 太衝 內關 外關 上星 日月 上關 下關)'}
{'verdict': 'correct', 'next_query': None}
{'verdict': 'correct', 'next_query': None}
{'verdict': 'incorrect', 'next_query': '外丘 穴位 國際譯名 國際編號 WHO 外丘 (Waiqiu) 編號 GB33 GB34 GB35 GB36'}
{'verdict': 'ambiguous', 'next_query': '陰維脈 郄穴 是 哪一個?(交信、築賓、府舍、腹哀)'}
{'verdict': 'incorrect', 'next_query': '足太陰脾經 络穴 哪一穴?地機 漏谷 公孫 太白'}
{'verdict': 'ambiguous', 'next_query': '《難經·六十八難》 心下滿 主何穴? 前谷 液門 湧泉 跗陽'}
{'verdict': 'correct', 'next_query': None}
{'verdict': 'incorrect', 'next_query': '臑會、顴髎、秉風、聽宮、耳門 哪些屬於三焦經與膽經的交會穴'}
{'verdict': 'ambiguous', 'next_query': '通里穴 (HT5) 是否屬於 馬丹陽 天星十二穴?請列出馬丹陽天星十二穴的完整清單或來源。'}
evaluator_result: 與對應的 verdict 以及 next_query
context,至於 correct 的情況,由於沒有新一輪的檢索,因此 context 暫時留空old_context 留空,否則取出舊有的 old_context 與新的 context 拼接在一起def get_tavily_context(tavily_response):
txt = ''
rvs = []
for doc in tavily_response:
txt+=doc.text_resource.text
txt+='\n\n'
rvs.append({
'url': doc.metadata['url'],
'txt': doc.text_resource.text
})
return txt, rvs
rvs = []
for data in tavily_source:
rv = data.copy()
verdict = rv['evaluator_result']['verdict']
if verdict in ['incorrect', 'ambiguous']:
next_query = rv['evaluator_result']['next_query']
tavily_response = tavily_tool.search(next_query, max_results=5)
context, response = get_tavily_context(tavily_response)
rv['tavily_response'] = response
else:
context = ''
rv['tavily_response'] = None
if verdict == 'incorrect':
old_context = ''
else:
old_context = rv['context']
context_v2 = context + old_context
rv['context_v2'] = context_v2
rvs.append(rv)
ANSWER_PROMPT_WITH_CONTEXT = PromptTemplate(
template="""
你是一個中醫考題專家,請根據下面的題目回答單選題。
請遵守以下規則:
1. 嚴格依據提供的參考資料 context 作答。
2. 輸出 JSON 格式。
3. JSON 需包含兩個 key:
- "ans" :只回答單選答案 (A/B/C/D)
- "feedback" :簡短說明為什麼選這個答案
4. 不要加入題目之外的說明或其他文字。
題目:
#{query}
參考資料 (context):
#{context}
請直接輸出 JSON:
"""
)
結果為:
我們來檢查看看 evaluator 的結果
我們這邊會跑 Faithfulness Score 作為 x 軸,以及 Context Relevancy Score 作為 y 軸
用藍點標示答對的題目、用紅點標示答錯的題目
我們直接看圖: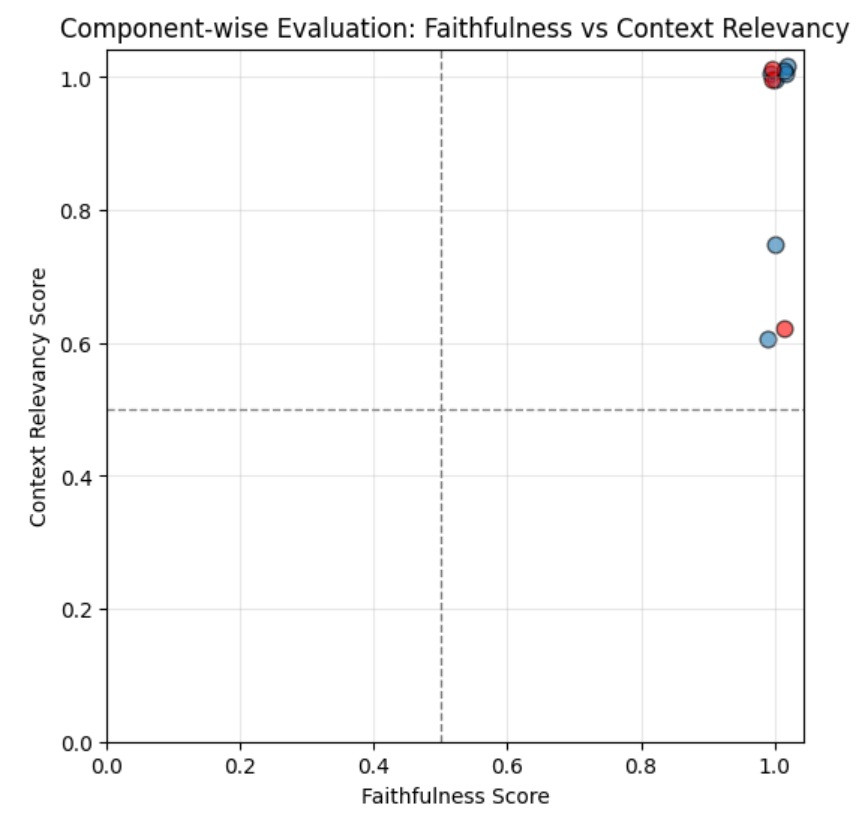
這張圖的所有自評結果都給出了不低的分數,尤其是 Faithfulness,基本上全部都是給出 1 分
Context Relevancy Score 最低的也有 0.6,而且那題還是答對的情況
所有的點都集中在右上角這個情況,屬於是我們的 evaluator 失效的情況
但我們仍然可以稍微推測一下:
我們明天來把 label-stduio 標註工具架起來,實際看一下這個情況究竟是怎麼回事


 iThome鐵人賽
iThome鐵人賽