昨天我們正式向 DNN 告別,因為它在處理高解析度圖片時,無法避免參數爆炸與空間資訊丟失這兩大致命傷。今天,我們就要實際走一遍 CNN 的完整流程,看看這個「圖像界的明星架構」是如何優雅且高效地,將一張圖片從單純的像素矩陣,一路轉換成模型能理解的高階概念。
這整個過程,就是 CNN 的 前向傳播 (Forward Pass),它就像一場高效、精密的圖片解析冒險之旅。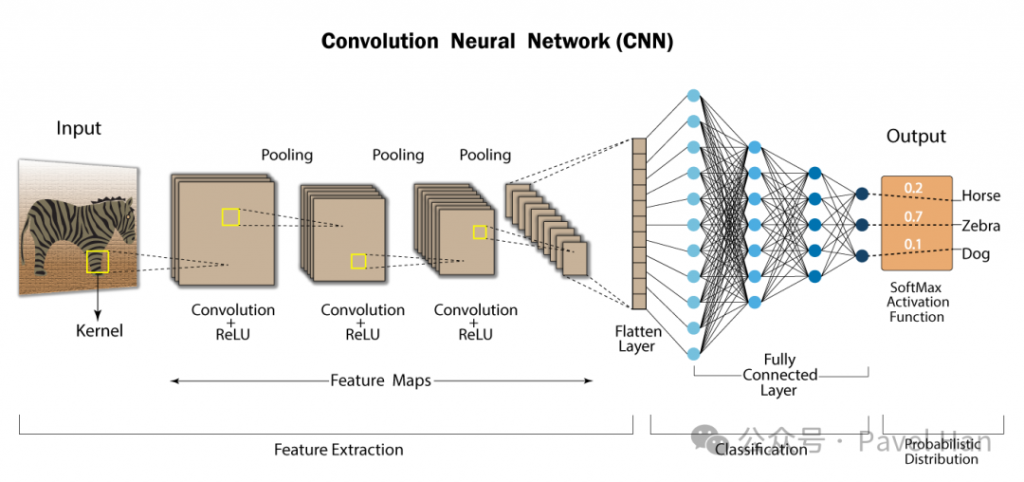
🚨 CNN 的解決方案:保留空間結構與局部感知
CNN 的核心價值在於:它能通過特殊的**「局部掃描」機制來高效地提取特徵,同時完美保留像素間的空間鄰近關係**。
一、輸入影像 (Input Layer)
當一張圖片進入 CNN 時,它會先被轉換成一個數字矩陣,每個元素對應到一個像素值。
例如手寫數字資料集 (MNIST) 的影像大小是 28×28,對應到 784 個數字特徵。
可以把這一步想像成遊戲的「地圖讀取」,CNN 需要先完整讀進整張地圖,才能開始冒險。
二、卷積層 (Convolution Layer)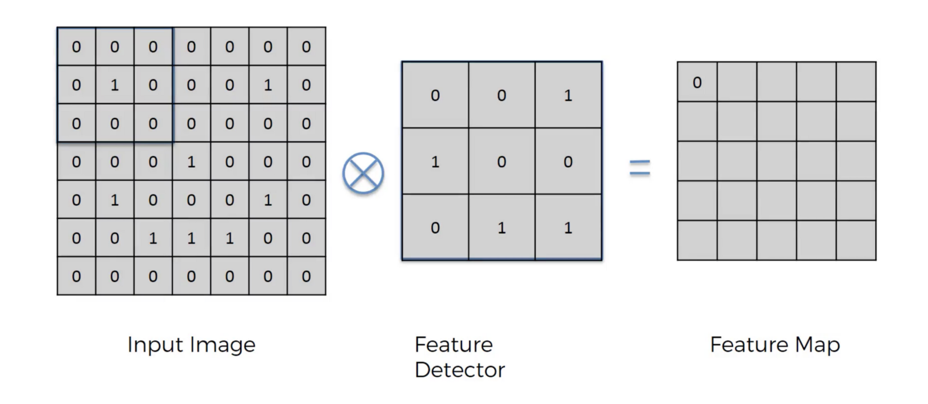
卷積運算圖解
圖中展示了卷積運算的核心機制:一個 3X3 的 濾波器 (Filter) 在 5X5 的 輸入影像 上滑動,並對應區域進行矩陣相乘後加總,得到特徵圖上的一個新值。這個過程重複進行,最終將 5X5 的輸入轉換為 3X3 的輸出。這說明了卷積層如何以極少的參數,高效地提取圖像中的局部特徵。
CNN 的核心技能就是「卷積運算」。卷積層會使用小小的矩陣(Filter 或 Kernel),像一個「特徵偵測器」,在圖片上滑動並檢查局部區域。這個運算過程是:Filter 與區域進行點乘,再把結果加總,最後得到一張新的「特徵圖 」。卷積層之所以強大,來自幾個設計:
權重共享 (Weight Sharing):同一個 Filter 掃整張圖,讓參數量大幅減少。
Padding:在圖片邊界補零,避免特徵在邊緣被忽略。
Stride:決定 Filter 每次滑動的步幅,會直接影響輸出的尺寸。
卷積層的角色,就像是玩家拿著放大鏡,一格一格掃描地圖,把重要的細節標記出來。
三、激活函數 (Activation Function)
在完成卷積後,CNN 還需要透過激活函數來引入非線性能力,否則整個網路再多層也只是一個線性函數。目前最常用的是 ReLU (Rectified Linear Unit),它的規則很簡單:輸入小於 0 的部分直接歸零,輸入大於 0 的部分原樣輸出。激活函數就像是在地圖上「加強亮點標記」,把沒用的訊號忽略,只留下有意義的部分。
四、池化層 (Pooling Layer)
為了讓運算更有效率,CNN 還會使用池化層來縮小圖片,濃縮資訊並降低計算量。最常見的方法是 MaxPooling,它會在一個小區域內挑出最大值,作為該區域的代表特徵。這一步驟就像冒險者整理背包,只留下最強的裝備,把無關緊要的東西丟掉,讓整體更輕便。
五、多層堆疊
CNN 的強大之處在於可以不斷堆疊「卷積 → 激活 → 池化」的組合,逐層學習更高階的特徵。
在前幾層,網路學到的可能是邊緣或顏色;再往後一些層,它會捕捉形狀和局部結構;等到最後幾層,網路已經能夠辨識完整的物件,例如數字、臉孔或車輛。「由淺入深」的特徵抽象能力,使 CNN 成為影像辨識的明星架構。
六、展平與分類 (Flatten & Fully Connected Layer)
當 CNN 完成特徵提取後,最後一步是把特徵圖 展平 (Flatten) 成一維向量,再送進傳統的全連接層 (Fully Connected Layer, FC)。像一個最終判斷器,會整合所有學到的特徵,並透過 Softmax 輸出每個類別的機率。
此時,CNN 的 Forward Pass 就結束了:它會告訴你「這張圖是狗?還是貓?」
整個 CNN 的前向傳播流程就像一場冒險破關:
輸入圖片 → 卷積 → 激活 → 池化 → 多層堆疊 → 展平 → 全連接層 → 最終分類。
明天,我們將繼續深入,看看 CNN 如何透過反向傳播 (Backward Pass) 從錯誤中學習,調整自己的 Filter,讓模型越來越強。

