各位夥伴,從 Day 6 到 Day 10,我們已經徹底拆解並在 Playground 中見證了 DNN (深度神經網路) 的所有核心要素。今天,我們將對這些基礎知識進行總結,並正式揭示 DNN 在處理視覺任務時的致命缺陷!
一、DNN 知識總結:神經網路的基石
 👉 核心:加權總和 → 非線性轉換。
👉 核心:加權總和 → 非線性轉換。沒有 ReLU、Tanh 等非線性,無論把層堆得多深,整體仍只是單一線性變換,難以刻畫像 XOR 這類複雜邊界;深度的威力來自多層結構:單一神經元只能畫出線性分界,而多層 DNN 依通用近似定理能逼近任意複雜函數,這正是深度學習的根源強項;而學習本質上就是不斷調整 w 與 b:透過反向傳播計算梯度,由優化器沿梯度下降方向修正參數,使模型逐步降低損失並提升表現。
二、DNN 在圖像上的兩大致命傷
即便 DNN 很強,一到高解析影像就撞牆,原因有二。
DNN 需要把整張圖 Flatten 成向量再餵入全連接層,參數量瞬間飆升。
| 圖像大小 | 輸入層神經元數 | 若第一隱藏層為 1000 個神經元 → 權重數量 |
|---|---|---|
| CIFAR-10 32×32×3 | 3,072 | 3,072 × 1000 ≈ 300 萬 |
| 標準圖 256×256×3 | 196,608 | 196,608 × 1000 ≈ 2 億 |
光是第一層就可能上千萬到上億參數:算力高、記憶體爆、訓練難收斂。
把 2D 影像攤平成 1D,鄰近像素的相對位置與局部結構全丟失。
邊緣、角點、紋理等局部特徵難以有效學到。
三、明星技能登場:CNN 簡介與歷史回顧
為了在大幅減少參數的同時保留空間結構與局部特徵,我們採用卷積神經網路 CNN:以卷積核在影像上掃描,逐層學得從邊緣到物件的階層式特徵,廣泛應用於手寫數字、人臉、自駕、醫療影像與生成式影像模型的基礎。
里程碑時間線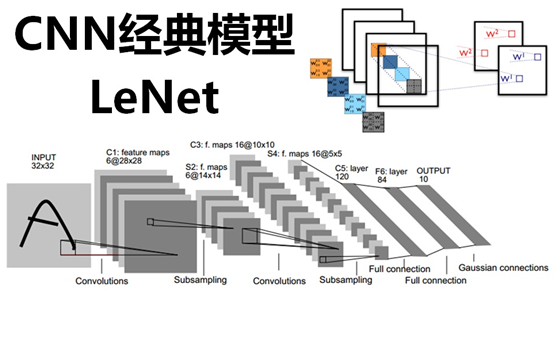
CNN 發展脈絡:1998 的 LeNet 奠定卷積雛形;2012 的 AlexNet 以更深網路、ReLU 與多 GPU 引爆深度學習,ImageNet 錯誤率降至 16.4%;2014 的 VGG 以大量 3×3 小卷積堆疊證明「更深更好」,同年的 GoogLeNet 用 Inception 與 1×1 卷積在效能與參數間取得平衡;2015 的 ResNet 以殘差連接解決超深網路訓練難題;其後 DenseNet 主打特徵重用、SENet 引入通道注意力。整體路線清楚指向:更深的結構 + 更有效的特徵流動。
四、核心問題:CNN 到底怎麼「學」?
CNN 的學習流程與 DNN 類似但關鍵流程有卷積的結構差異:前向以卷積核滑動產生特徵圖,經非線性與池化或正規化逐層堆疊後送入分類器;反向由損失訊號更新卷積核與偏差以習得邊緣、紋理與形狀等特徵;並由優化器配合學習率排程提升收斂效率與穩定性。

