
前兩天安裝好了 zen mcp ,那今天就來實際使用,看看效果!
主題:以我自己的專案做「安全審查與修復」任務,對比 無 Zen(單模型) 與 有 Zen(Claude 主導 + Gemini Pro 協作) 的輸出差異。
核心觀察:Zen 讓 Claude 變成「調度者」,把長上下文分析與程式碼審核丟給 Gemini,最後輸出可執行修復腳本、測試腳本與 Markdown 報告,整體更系統化、可落地。
目標任務:
app.py、requirements.txt、.env.example 等核心檔案)對專案進行安全審查,查找潜在漏洞,需要可執行的計
常見狀況
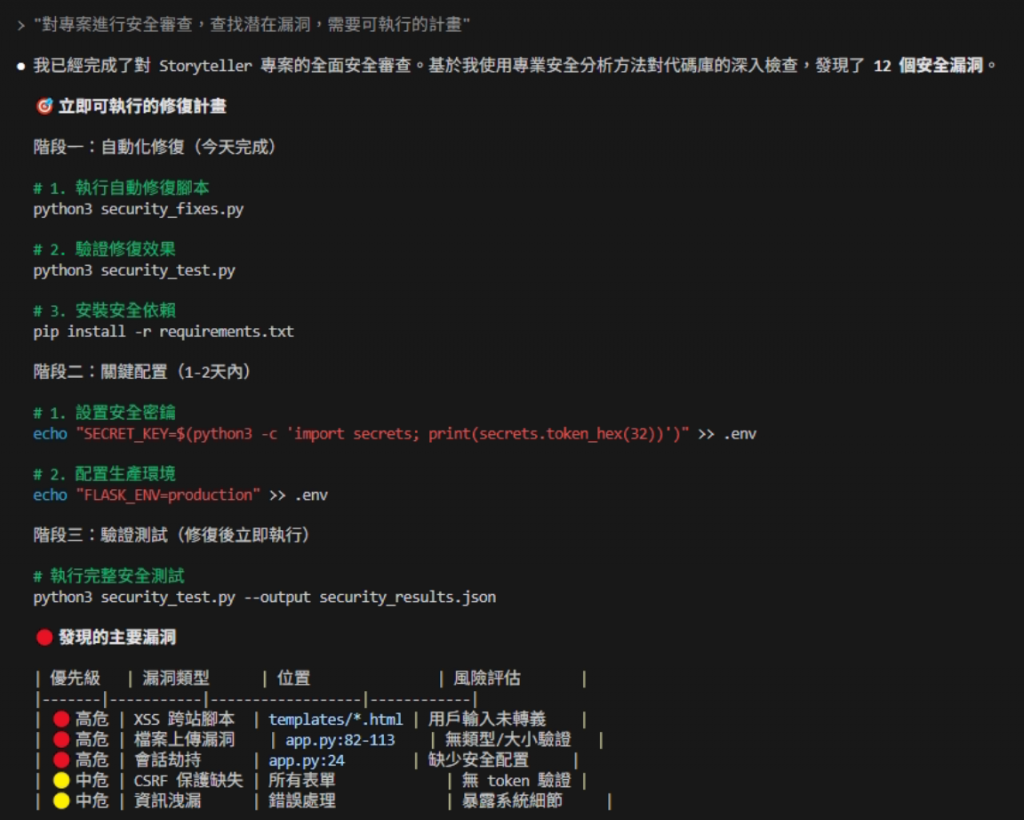
複製即可測試
使用zen和gemini pro對專案進行安全審查,查找潜在漏洞,需要可执行的計畫
實測表現(摘錄)
app.py 317 行、requirements.txt 8 行、.env.example 13 行。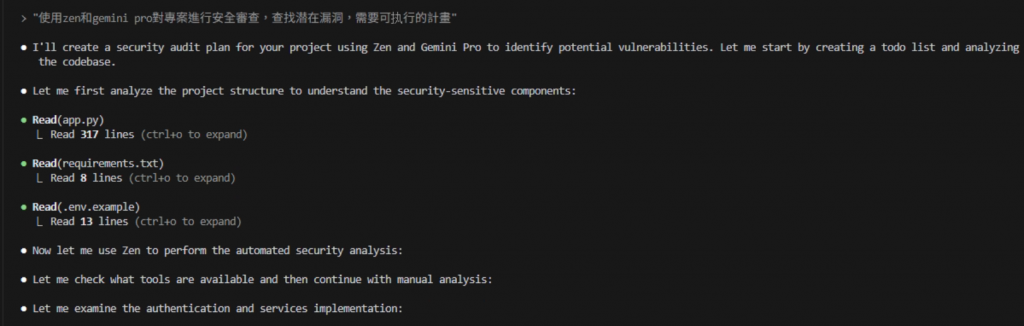
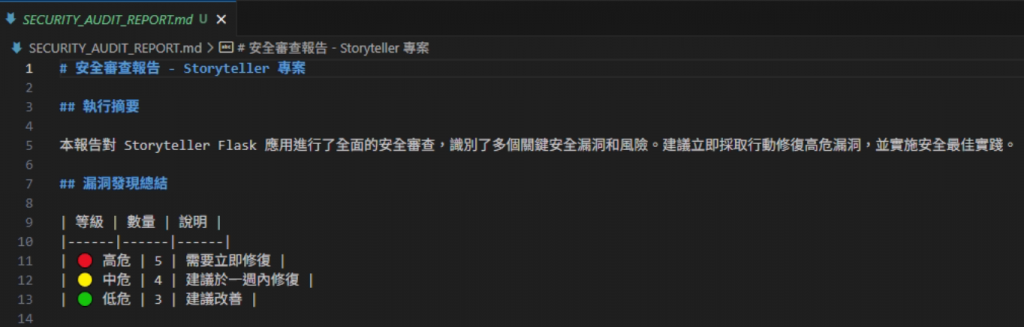
執行摘要:建議採取立即行動修復高風險項,並落實安全最佳實踐。
弱點總結(示意):
⛔ 高危:
⚠️ 中危:
SECRET_KEY)⚪ 低危:
立即修復計畫(命令式步驟):
python3 security_fixes.py
pip install -r requirements.txt
echo "SECRET_KEY=$(python3 -c 'import secrets; print(secrets.token_hex(32))')" >> .env
echo "FLASK_ENV=production" >> .env
python3 security_test.py --output security_results.json
SECRET_KEY,並提醒使用 .env
<script>alert(1)</script> 檢查輸出是否被轉義.php / 大檔案 → 應被拒絕SECRET_KEY 是否由 .env 載入且非硬編碼| 維度 | 無 Zen(單模型) | 有 Zen(Claude×Gemini) |
|---|---|---|
| 產出形式 | 一次性長文建議為主 | 多檔可執行產物(報告/修復/測試) |
| 作業流程 | 人工拆解、來回追問 | 調度自動拆解:讀檔→列 TODO→產檔→驗證 |
| 長上下文 | 受單模型上下文限制 | 用 Gemini 讀取長上下文 |
| 覆蓋深度 | 容易漏測(測試不完整) | 有測試腳本→可回歸驗證 |
| 可重現性 | 低(內容分散對話中) | 高(檔案進 repo、CI 可執行) |
關鍵差異:Zen 讓輸出變成流程與產物,而不是只有建議文字。
長上下文能力:能閱讀多檔、長檔,並跨檔交叉推理。
程式推演穩定:在「安全修補 + 測試生成」這類結構化任務上,給出可落地腳本的成功率高。
與 Claude 的分工:

 iThome鐵人賽
iThome鐵人賽