想像你在考試。
LLM 就像是一個「很會考試的學生」,他腦袋裡記了很多書本知識,但這些知識只到他讀書的那一天。如果考題問到新出的資訊(例如最新的新聞、產品或研究),他可能就答不出來,或乾脆「亂掰」一個聽起來合理的答案。
但如果使用 RAG(Retrieval Augmented Generation 檢索增強生成)就像這個學生在考試時,允許他「打開課本或上網查資料」。他還是會用自己的理解能力(生成文字的能力)來回答問題,但同時可以把最新的、正確的資料拿進來輔助。
以下是 RAG 的優點:
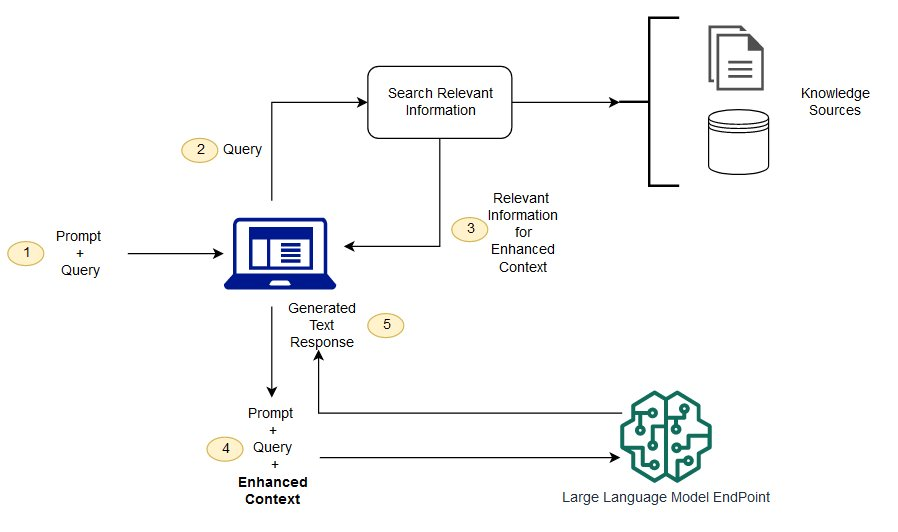
先來一張流程圖吧
在講解 RAG 時候,還有一個特別的東西要單獨講,「向量資料庫」,當你有成千上萬筆向量要儲存與比對時,單純放在一般資料庫裡效率就會變得很差。這時候就需要 向量資料庫,其重點有兩個 1. 專門針對高維度向量做優化 2. 能在龐大資料裡,秒級找到最相似的結果。
常見的向量資料庫有 FAISS、Qdrant、Pinecone 等。這些工具讓我們可以把 embedding 向量丟進去,然後透過「相似度搜尋」快速找到相關內容。
那這邊介紹兩個方便的向量搜尋的工具 Qdrant 與 Faiss 的用法吧
Faiss
import faiss
import numpy as np
import ollama
def get_embedding(text):
result = ollama.embeddings(
model="bge-m3:567m",
prompt=text,
keep_alive="1s"
)["embedding"]
return result
sentences = [
"貓喜歡吃魚",
"狗喜歡玩球",
"我今天去超市買牛奶",
"昨天晚上看了一部電影"
]
embeddings = []
for text in sentences:
embeddings.append(get_embedding(text))
# 建立 index
dim = len(embeddings[0]) # 向量維度
index = faiss.IndexFlatL2(dim) # L2 距離
index.add(np.array(embeddings).astype("float32"))
# 查詢
query = "超市買東西"
query_vec = np.array([get_embedding(query)]).astype("float32")
D, I = index.search(query_vec, k=1) # 找最相似的兩個
print("Faiss 結果:", sentences[I[0][0]])

Qdrant
import numpy as np
import ollama
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance, PointStruct
def get_embedding(text):
result = ollama.embeddings(
model="bge-m3:567m",
prompt=text,
keep_alive="1s"
)["embedding"]
return result
# 文件資料
sentences = [
"貓喜歡吃魚",
"狗喜歡玩球",
"我今天去超市買牛奶",
"昨天晚上看了一部電影"
]
# 建立 embedding
embeddings = [get_embedding(s) for s in sentences]
dim = len(embeddings[0]) # 向量維度
# 啟動 Qdrant (用記憶體模式,方便測試;正式環境可連線到伺服器)
qdrant = QdrantClient(":memory:")
# 建立 collection
qdrant.recreate_collection(
collection_name="docs",
vectors_config=VectorParams(size=dim, distance=Distance.COSINE),
)
# 插入資料 (帶 payload 以便查回原始句子)
qdrant.upsert(
collection_name="docs",
points=[
PointStruct(
id=i,
vector=embeddings[i],
payload={"text": sentences[i]}
)
for i in range(len(sentences))
]
)
# 查詢
query = "超市買東西"
query_vec = get_embedding(query)
search_result = qdrant.search(
collection_name="docs",
query_vector=query_vec,
limit=1
)
print("Qdrant 結果:", search_result[0].payload["text"])

