首先先來到 Ollama Github 頁面,並且根據作業系統選擇對應的安裝方式
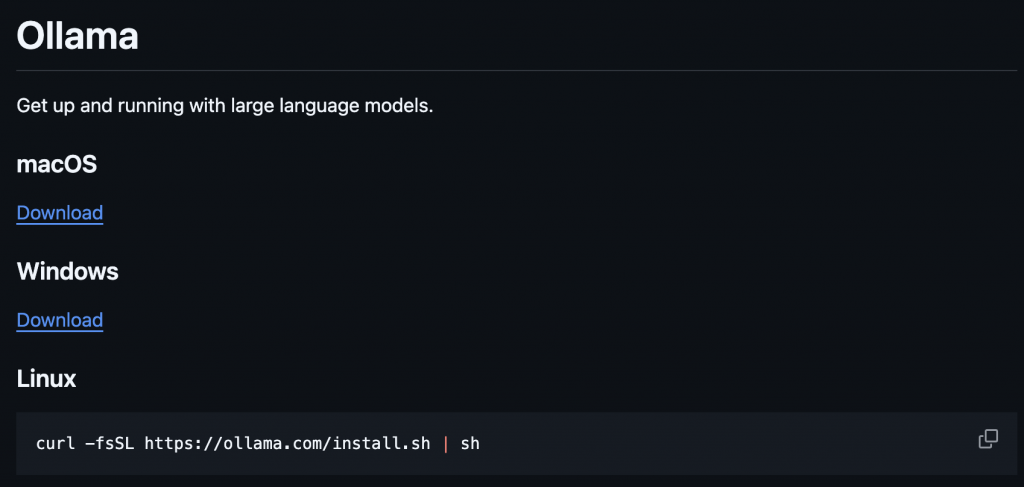
這邊以 Linux 為範例!
輸入這行指令 -> curl -fsSL https://ollama.com/install.sh | sh 並且等待下載完畢,由於 Llama.cpp 可以運行在只有 CPU 的環境,所以即使沒有 Nvidia GPU 也可以
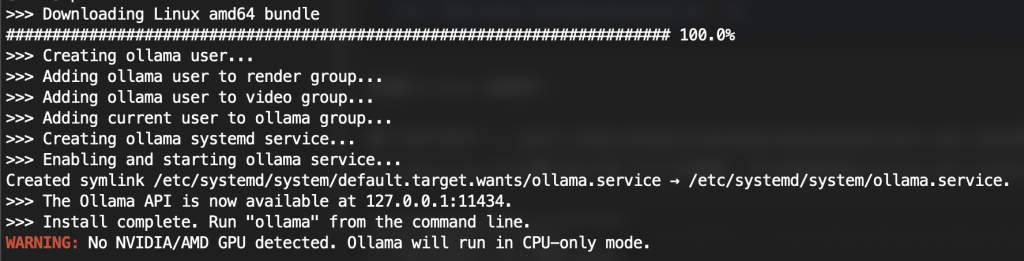
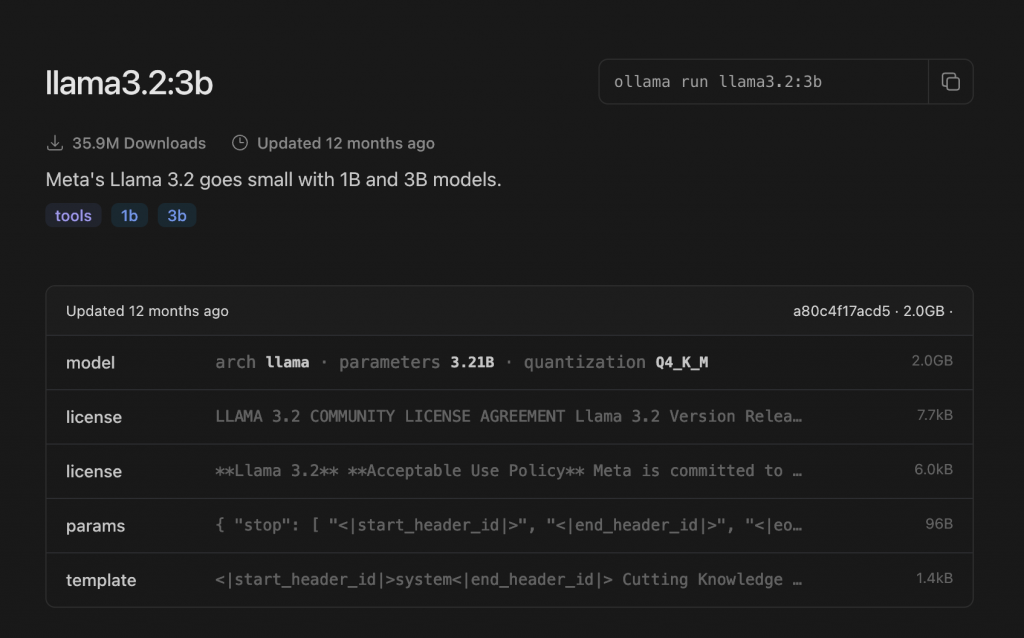
再來我們要下載我們需要使用的模型,這邊以 Meta 的 Llama3.2 3B 來做範例
我們來介紹一下,模型的資料庫 Ollama hub,
這邊存放了幾乎所有可以拿來推理的模型
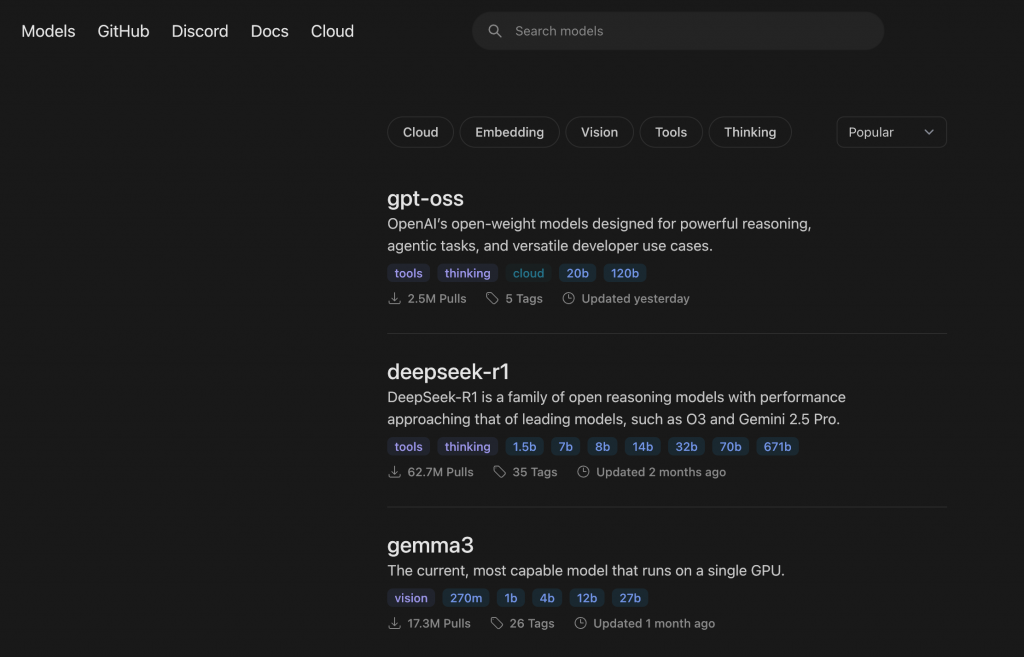
那我們在搜尋框輸入 llama3.2 並且點選搜尋結果,右上角會有一個 ollama pull <model> 的指令,我們將其複製起來,並且貼到終端上面

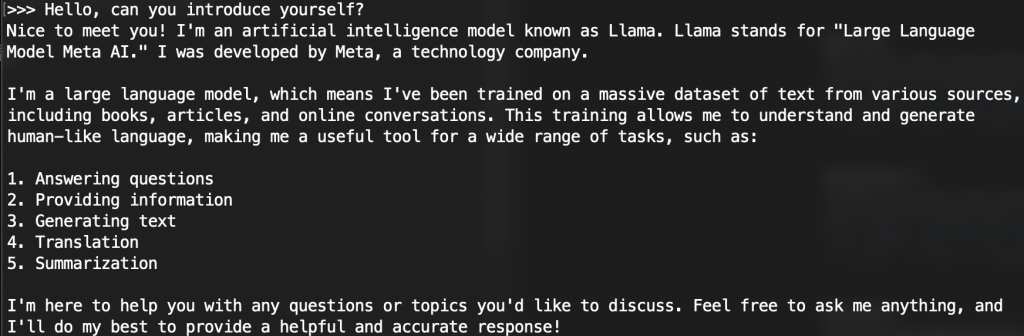
在下載過後就能與 llm 模型進行對話
那麼至於實作的話,其實也很簡單,這邊也用 Python 去實作
那這邊我們需要先安裝套件
pip install ollama
再來直接上一個範例程式碼
import ollama
client = ollama.Client()
print(client.chat(
model="llama3.2:3b",
messages=[{
"role": "user",
"content": "Hello, can you introduce yourself"
}]
).message.content)

我們可以單純的透過程式碼去與 LLM 互動了!

