由於還有 15 天,接下來打算抽換 memory 與 net,並且比較效果,那我們勢必要有一個可以 客觀比較效果 的方法。
講到 evaluation 就該有 dataset !
那我想了一下 對於測試 agent-brain 的 dataset 應該具備幾種特性:
內建 tools (functions):最好是能 local execute 的,不需要依賴額外 LLM server。MCP server 先不考慮,放到 future work。
不使用 LLM 當 evaluator:雖然很多頂會 paper(ACL、ICLR)都會用 LLM-as-a-judge,但
今天最主要 survey 了多個 paper 後,感覺有兩個 dataset 是比較適合的
背景: Accepted by ACL 2025 Main Conference,bytedance-research 字節跳動
paper: https://arxiv.org/abs/2501.02506
應該是有一定說服力的...
然後我也很順利的從 hugging face 上找到資料集了。
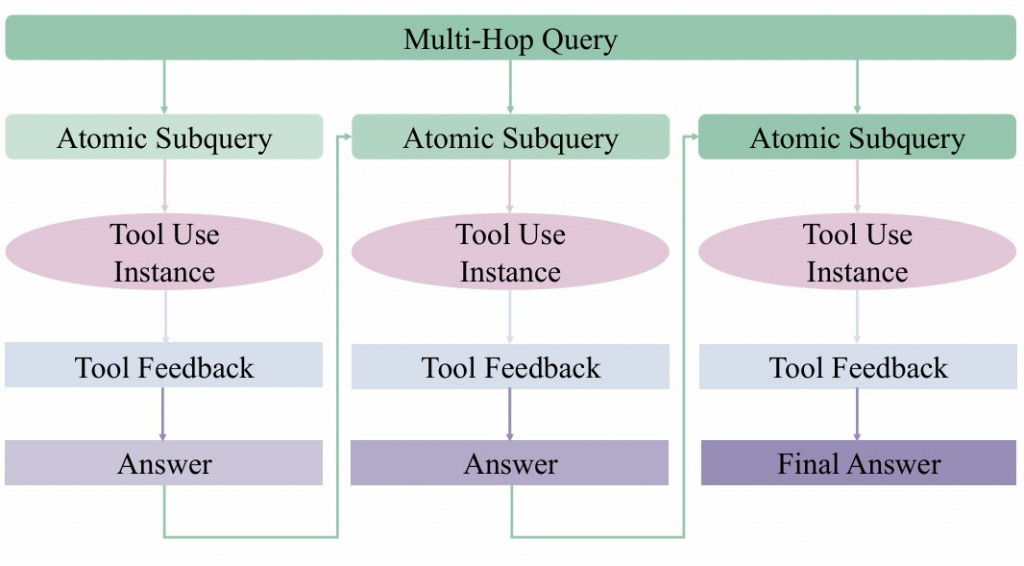
反正主要想測試,這種需要多次使用 tools,才能解決的問題

ToolHop 的核心想法是:有些問題必須透過多次 tool calls才能得到答案。
例如:Which day of the week was the date of birth of the English inventor that developed the Richard Hornsby & Sons oil engine?
所以以這題來說,我們有三個步驟要做
這正好符合測試 agent-brain 的情境:multi-turn 的 tool usage 與更新 memory,而不是單純一次查詢。
但我覺得也有可能 tool use 的上下文太短,導致使用更好的 memory 沒什麼效果,或者進步幅度比較不明顯。
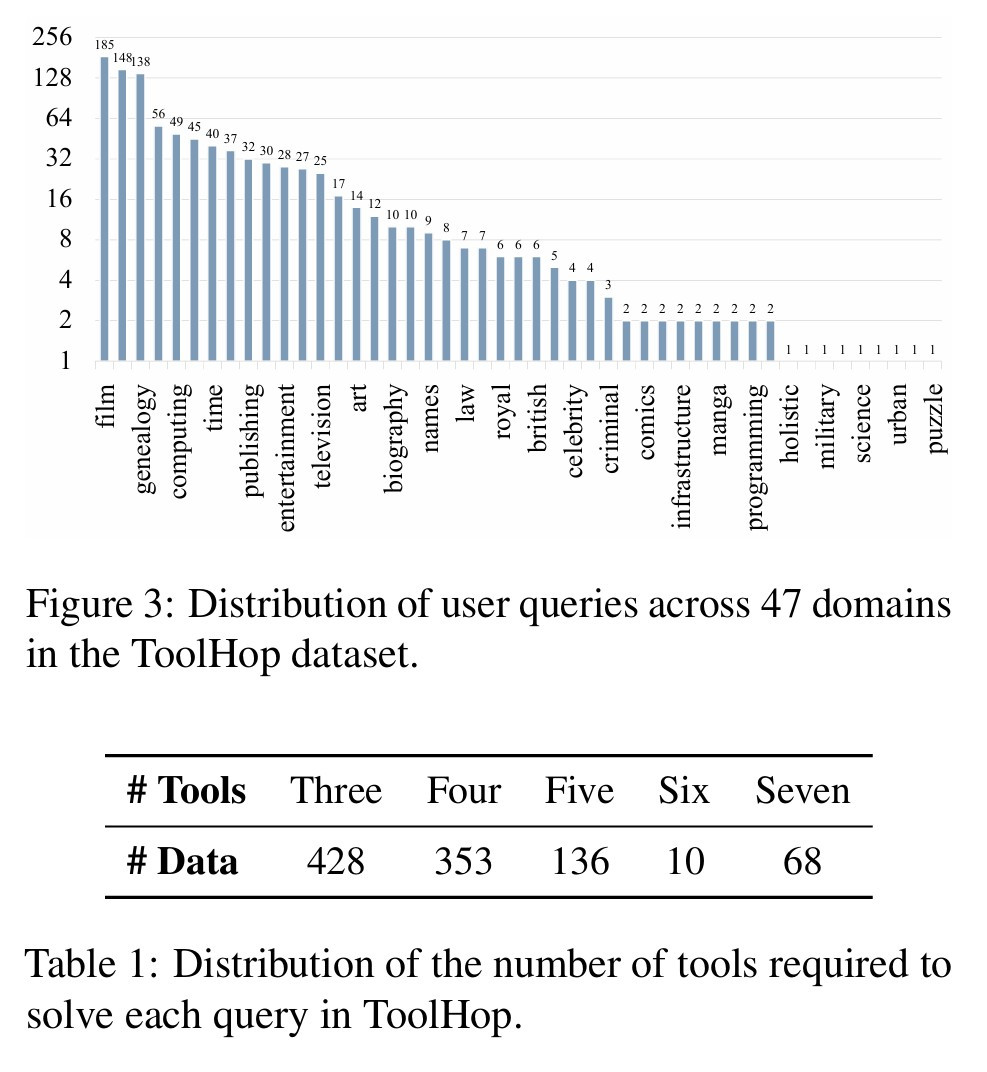
最多到 7 次 tool call 才能回答出來的題目。
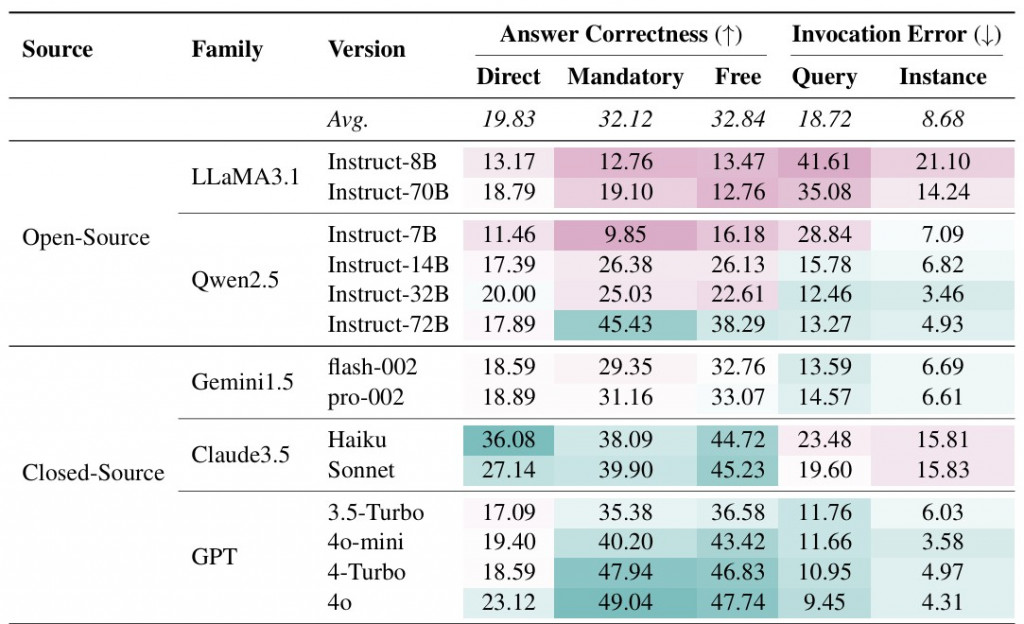
實驗設定有分3大種類
並且可以看到,當時候的 llm (gpt-4o) 有沒有使用 tools 的分數其實差異蠻大的,算是一個蠻有挑戰的資料集
net 跟 memory 的好壞dataset 真的看得眼花撩亂,但是一個 evaluate 最重要的東西,所以值得仔細看一下,明天再繼續介紹另一個由 UC Berkeley 提出來的 dataset BFCL V3,更大更多的資料集


 iThome鐵人賽
iThome鐵人賽