單純 survey 一下,BFCL 的 dataset 如果想做很完整實驗應該要跑這個,
目前 BFCL dataset 已經出到了 v4 (包含 agent 的能力)
Berkeley Function-Calling Leaderboard (BFCL) 顧名思義就是一個測試 LLM call functions and tools 的 dataset
並且一直到現在,還有一個 Leader board 展示著目前誰比較強
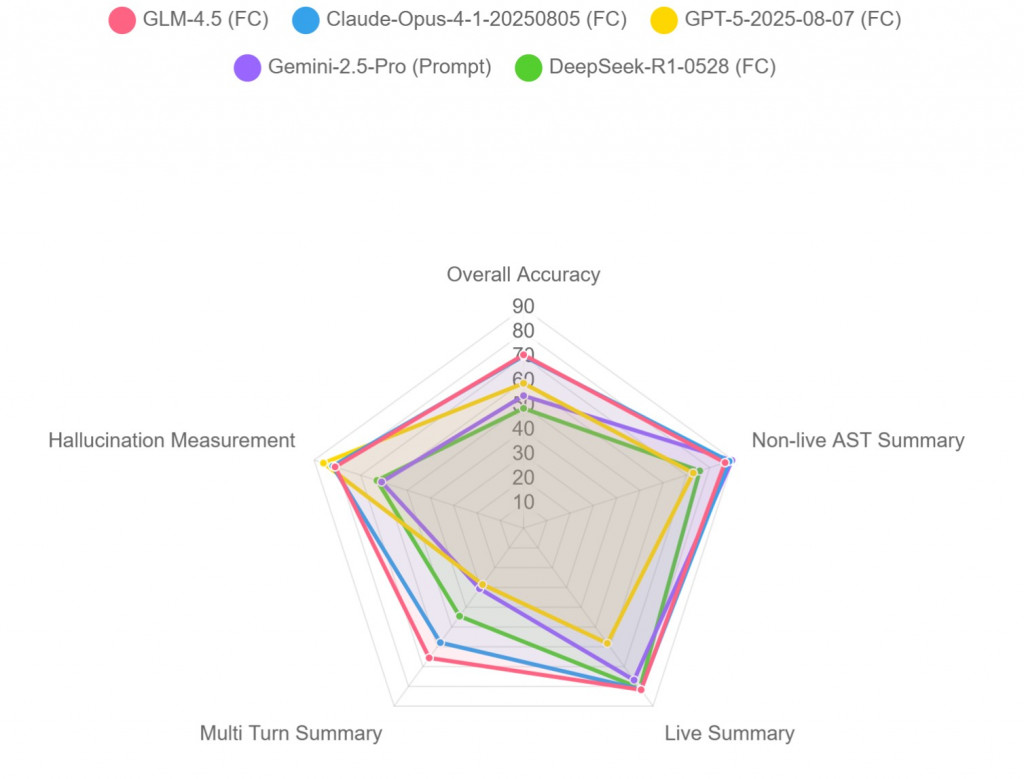
可以看到在 Multi Turn Summary 的 domain 上,GLM 跟 Claude 跟其他人都有蠻明顯的差距在的。
然後 GPT 5 是最少幻覺的?
v1:AST 可執行評分
用抽象語法樹(AST)自動判斷函式呼叫是否正確,讓評估可以規模化、跨語言。這
最主要有分兩大 category
(用 AST 的最大原因是,func implementation 不太一樣,所以用 AST 讓表達一致)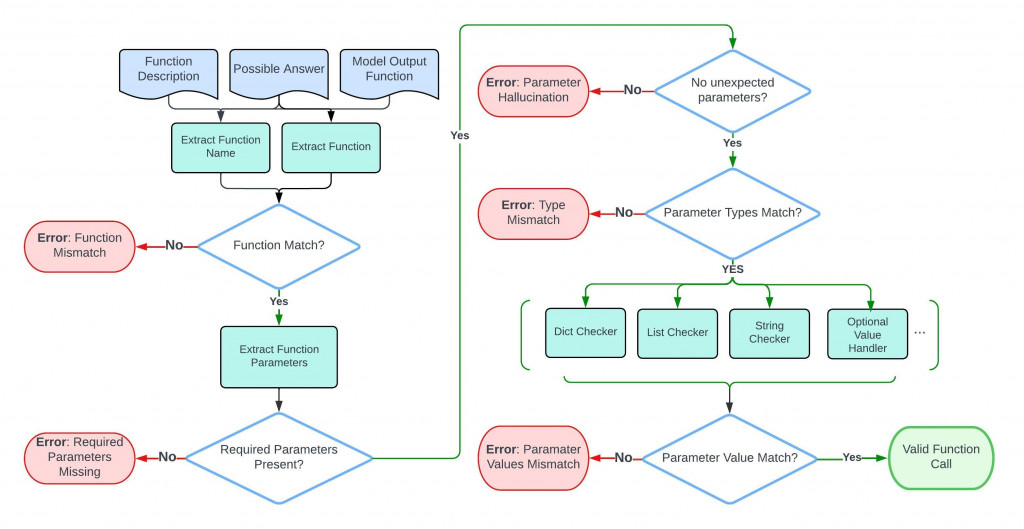
dataset 分布
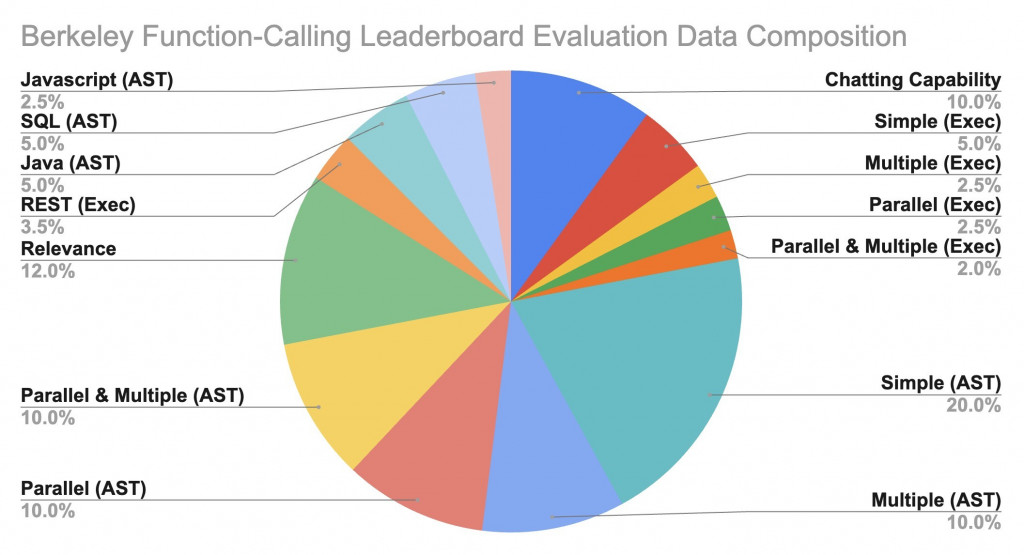
像 Gemini 在 AST 這個任務上就拿到超高的成績,感覺寫扣很強
v2:企業/社群貢獻函式庫
加入企業與開源場景的實際函式與 API,讓題庫更貼近真實工作負載,不只是單純在寫扣的問題。
v2 除了包含 v1 的資料集,主要新增了兩大 category,這就不單純寫 code 了
v3:Multi-Turn / Multi-Step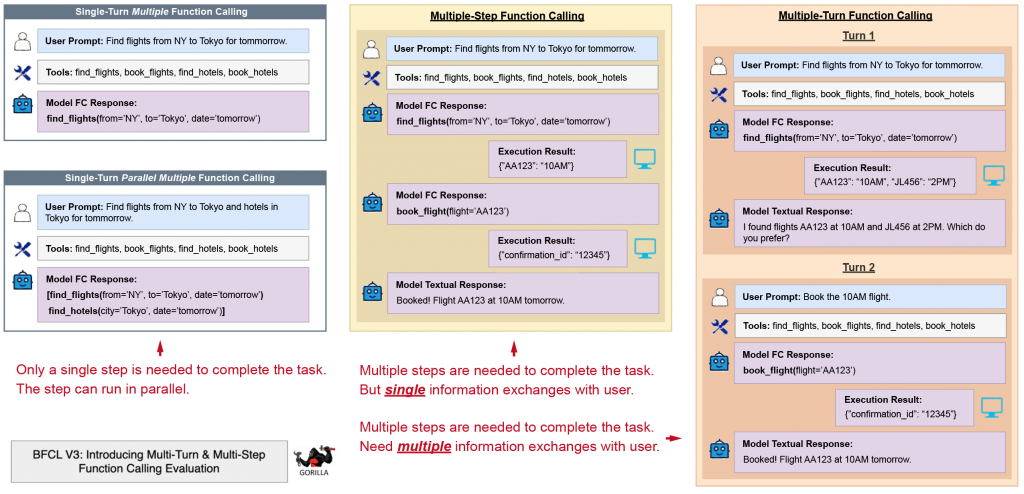
BFCL 明確定義了 multi-turn 跟 multi-step 的差別
我感覺 toolhop 比較像這樣
v4:Agentic
分為 3 個 part
web search
靠 duck duck go 的 web search api。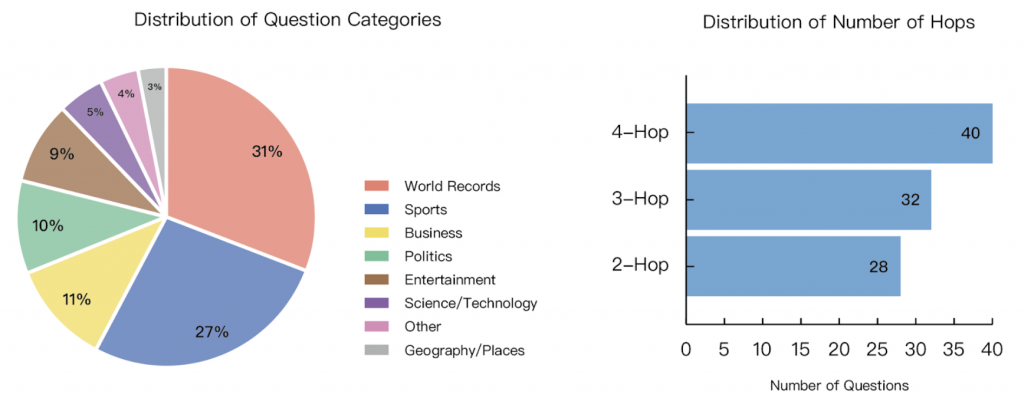
資料分布 與 需要幾次搜尋 (這邊怎麼感覺又跟昨天提到的 toolhop) 有點像
這連結有詳細怎麼用 duckduckgo 的教學 https://gorilla.cs.berkeley.edu/blogs/15_bfcl_v4_web_search.html
memory
這就有趣了,也是考驗 multi turn 的資料集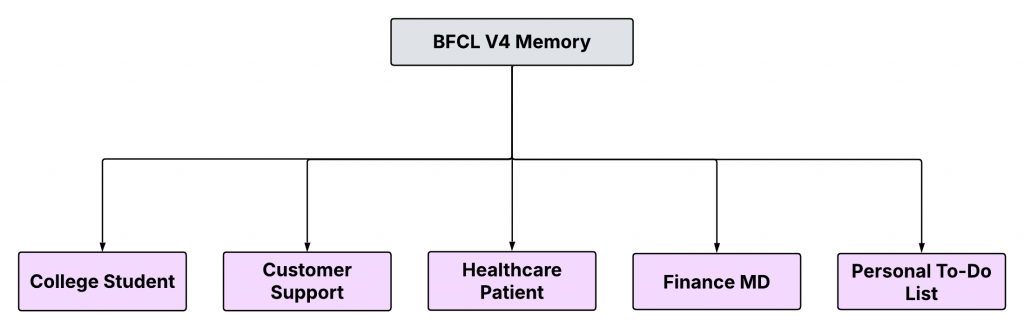
有區分幾種需要記憶的情境。
然後 memory 的種類也有區分,太贊了
有統一抽幾個 api interface,底下再自己實作要用的 memory
https://gorilla.cs.berkeley.edu/blogs/16_bfcl_v4_memory.html
我感覺 BFCL 雖然是一個 dataset,但是官網上從測試的角度,帶出各種不同更 high level 的面相,還蠻值得一看得


 iThome鐵人賽
iThome鐵人賽