想像你走進一個大型超市要買新鮮的番茄 🍅。菜架上擺滿了上百種蔬果,如果你用 RNN 或是 LSTM 那樣的序列模型的方法找,你就會是一層一層貨架這樣依序慢慢找。這樣應該會花很多時間才會找到你要的東西。
但是呢,在 Transformer 中有一功能叫 注意力機制(Attention Mechanism),它就像給你裝上了一雙「雷達眼」,讓你能直接鎖定番茄所在的位置,不必逐一檢查每個貨架。
Transformer 就是把這種「抓重點、知道該注意誰」的能力搬進模型裡,讓它能一次抓住長長的文本中的重要資訊,而不是慢慢累積記憶。
今天我們就來更詳細的認識這個架構吧!

(不是這個)
Transformer 是為了做 Seq2Seq(Sequence to sequence) 任務而設計的,也就是「輸入一段序列 → 輸出另一段序列」,像翻譯或摘要這類的任務。
不像傳統的 RNN/LSTM 是逐步處理序列去累積記憶,Transformer 的作法一次把整個序列丟進去,然後靠 注意力機制 去找出輸入中對生成輸出最重要的部分。
原始的 Transformer 架構是 Encoder-Decoder 的形式:Encoder 負責讀懂整個輸入序列,Decoder 根據 Encoder 的訊息一步步生成輸出序列。
在接下來的內容,我們先了解注意力機制,再介紹 Encoder-Decoder 的概念~
Attention Mechanism 的概念是要動態地依據每個詞的不同,去關注其他詞。
就好比你要做一道「番茄義大利麵」。
這個「根據當下關注的詞,去注意到其他詞的重要性」的過程,就是 注意力機制。
在 Transformer 裡,這件事在數學上化成了 Q、K、V:
也可以想像成我現在在圖書館,Q 是我要找的資訊,K 是書的目錄,V 是書的內容。
那有了這三個元素要如何進行計算呢?
![]()
圖片來源:https://kangshitao.github.io/2020/11/15/transformer/
Attention 計算流程是:
舉個例子,當模型在翻譯英文句子「I love pizza」時:
前面提到 Seq2Seq(Sequence to sequence)任務,是「輸入一段序列,再輸出一段序列」的過程。在這個架構中,處理輸入與輸出的部分,分別是由 Encoder(編碼器) 和 Decoder(解碼器) 負責。
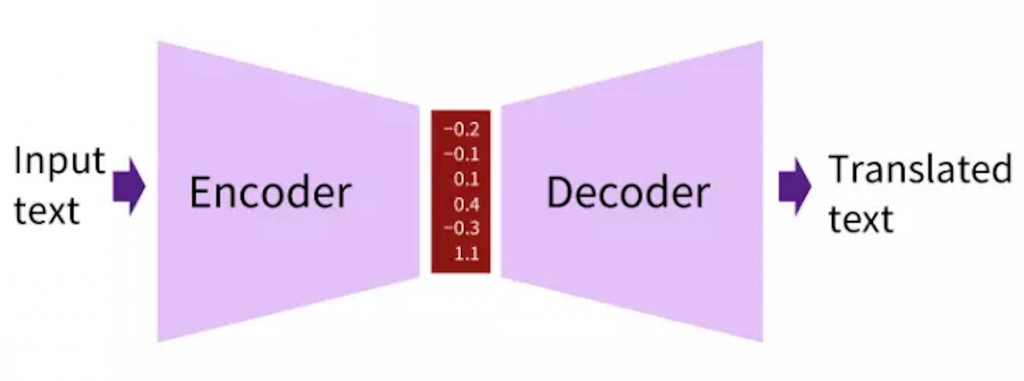
圖片來源:https://ithelp.ithome.com.tw/m/articles/10261889
今天我們認識了 Transformer 背後的兩大核心:一是讓模型能「抓重點」的 注意力機制(Attention),二是組合整個流程的 Encoder-Decoder 架構。
Encoder 負責理解輸入內容,Decoder 負責生成輸出,而 Attention 則是兩者之間的重要橋樑。這樣的設計讓 Transformer 能同時兼顧語意理解與文字生成,也成為後續很多模型的基礎~
像是後來有許多模型其實都是在 Transformer 的基礎上發展出不同方向:
明天開始,我們會進入 生成式大型語言模型(Generative Large Language Models) 的世界,看看我們熟悉的好朋友 ChatGPT 背後到底是什麼神秘力量,讓它可以生成出自然又有邏輯的文字!

