當 ChatGPT 剛問世時,大家是不是都被它震驚到了?
電腦居然能生成這麼自然、這麼像人講的文字!而且隨著 OpenAI 推出越來越多升級版,它似乎也變得越來越「聰明」🤓
相信很多人都會把一堆日常小事交給它做吧XDD 不管是寫信、總結文件,還是讓它幫你腦力激盪靈感,ChatGPT 幾乎樣樣都行!

圖片來源:https://www.pinterest.com/pin/pin-en--743164376036918316/
但你有沒有想過,ChatGPT 真的會「思考」嗎?
它真的「理解」我們在說什麼嗎?
今天我們就要來揭開這個秘密:GPT 背後到底是怎麼一步步生成文字的 🔮
讓我們直接開門見山 ⛰️ GPT 生成文字的過程,其實並不是真的「理解」語言。它在做的事情,比較像是玩一場「文字接龍遊戲」。
我們接下來要看看它是怎麼被訓練的、用什麼樣的模型架構,還有它在生成文字時又採用了哪些策略~~
生成式大型語言模型的訓練本質上是 監督式學習。
它是透過大量的文字資料來學習一個任務,就是預測 「下一個最有可能出現的字」(next-token prediction)。
舉例來說,在一句話 「我今天心情很好」 中,模型看到 「我今天心情」 時,它要學會預測下一個字是 「很好」。
所以這大量的文字資料本身就提供了訓練用的標籤:每個詞的「下一個詞」就是答案。
靠著「讀」海量的文字,模型可以逐漸學會語言的結構、語意、邏輯與常見表達,累積出對語言規律的十分驚人的掌握力。所以才會有覺得 「GPT 都懂我們在說什麼」的想法,其實可能是它在訓練時已經讀過啦~~~
在前一篇 Transformer 中有提到,像是 GPT 這種生成模型就是採用 Decoder(解碼器) 的部分。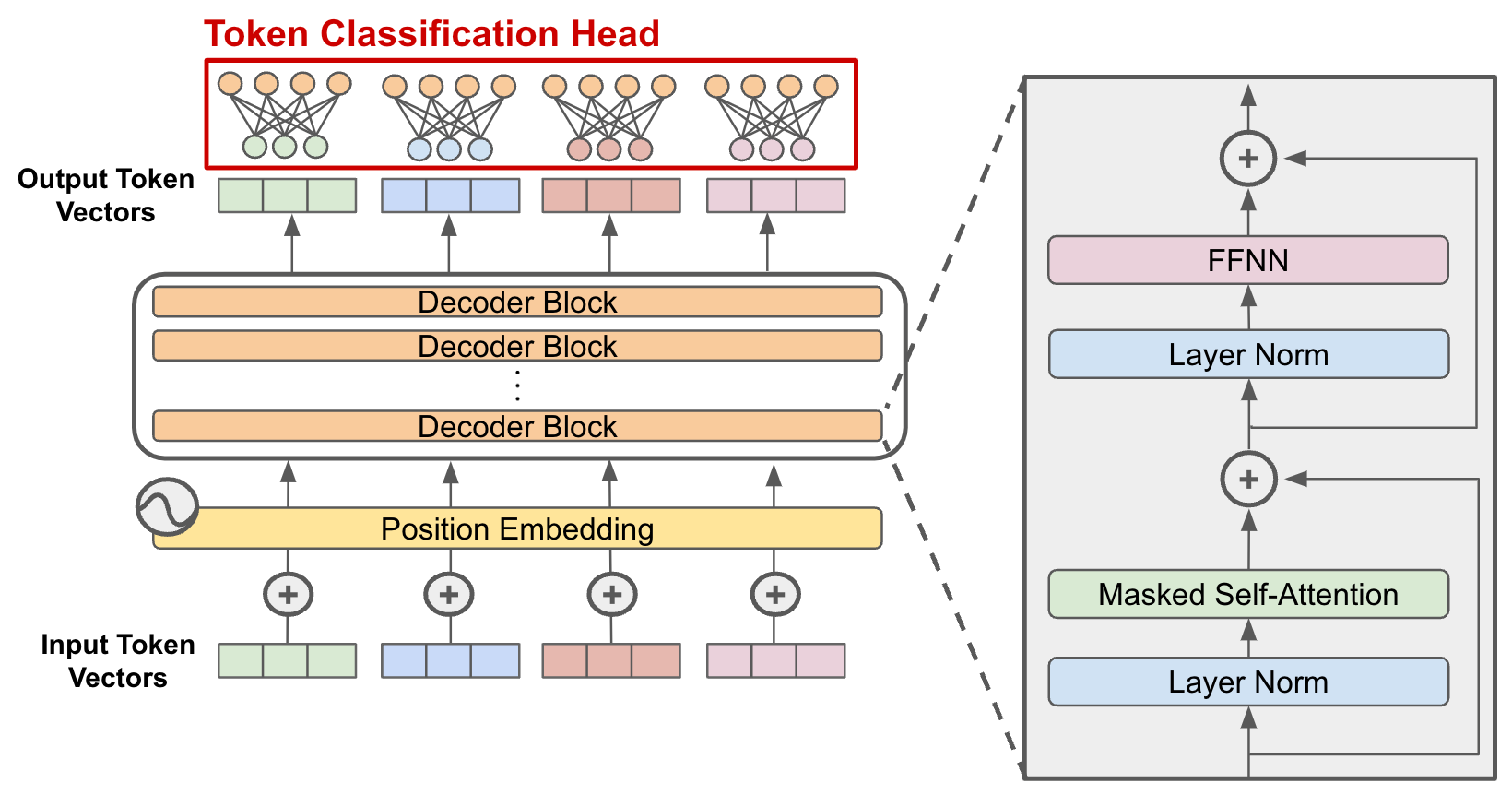
圖片來源:https://cameronrwolfe.substack.com/p/decoder-only-transformers-the-workhorse
Decoder 的特點就是能根據過去的內容,不斷「往後生成」新的字。
但在訓練時,為了避免模型「偷看未來答案」,GPT 在注意力機制中使用了 遮罩(mask),是為了確保每次預測時只能看到前面的詞,這樣才能模擬出「逐字生成」的過程。
自回歸(Autoregressive) 的意思是它在生成文字時,一次只生成一個 token,而且會把剛生成的結果再餵回模型中,作為下一步的輸入。
舉例來說:
假設我們輸入 「我今天」,模型會先根據這些內容預測下一個最可能出現的詞,可能是 「心情」。
接著它會把 「我今天心情」 整句再丟回模型,繼續預測下一個詞,可能就會輸出 「很好」。
於是重複這樣的步驟,將句子一步步地延長,直到模型判斷句子結束或達到最大長度。
這種逐步生成的方式讓文字能保持上下文連貫。而從數學角度來看,GPT 並不是單純在找「下一個字的最大機率」,而是在最大化整句話的機率!
這也是讓模型能生成語法自然、語意連貫的文字的關鍵!
那麼,既然 GPT 是根據機率挑選下一個字,那不就每次都會生成一模一樣的答案嗎?
其實不一定。
GPT 每次都會計算出所有字的機率分布,但不一定非得選擇機率最高的那一個,而是根據不同的「生成策略」來決定要不要多一點創意或隨機性。
常見的生成策略包括:
假設 p 值設 0.9
前五個是「很好」機率 0.6、「愉快」0.2、「開心」0.1、「不錯」0.05、「還行」0.05
那只會從前面三個加起來達 0.9 的這些「核心」選項裡挑
這些策略會影響 GPT 的「個性」,讓它的回答是比較嚴謹的,還是比較靈活的~
雖然 GPT 看起來像是在「理解語言」,但其實它只是個玩文字接龍的高手。它能生成連貫又自然的句子,但可不保證所有內容都是正確的哦!
今天我們了解了 GPT 生成文字的功力從何而來,但要讓它生成真正符合你需求的文字,又是另一門學問。
明天,我們會進一步討論 上下文學習與 Prompt 設計。也就是說,今天我們學到的是「它怎麼生成」,明天要學的則是「怎麼告訴它你想要什麼」!!

