在 Day26,我們學會了如何將使用者輸入的文字轉成 Embedding 並存入 Qdrant。
今天,我們要讓 RAG 系統更進一步:「讓它自己讀懂文件」。我們將實作一個能夠自動擷取 PDF、圖片文字的功能,
讓使用者只要上傳檔案,系統就能把內容轉成純文字,
準備進入後續的 Embedding 流程。
這一篇的目標是:
1️⃣ 支援 PDF、JPG、PNG 等常見檔案上傳
2️⃣ 將文件轉成純文字
3️⃣ 自動進行 OCR(文字辨識)
4️⃣ 回傳擷取出的內容,準備給 Embedding 使用
整體流程如下:
上傳檔案
↓
PDFBox / Tesseract 擷取文字
↓
回傳純文字內容
↓
丟入 Ollama Embedding → 儲存 Qdrant
pom.xml)<dependencies>
<!-- OCR -->
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>5.4.0</version>
</dependency>
<!-- PDF 解析 -->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.29</version>
</dependency>
</dependencies>
application.yml)file:
spring:
main:
allow-bean-definition-overriding: true
servlet:
multipart:
max-file-size: 50MB
max-request-size: 50MB
server:
port: 8080
file:
upload-dir: /home/ubuntu/SpringAI_RAG/springAI_rag/temp/uploaded_file/source_file
convert-dir: /home/ubuntu/SpringAI_RAG/springAI_rag/temp/uploaded_file/convert_file
@RestController
@RequiredArgsConstructor
@RequestMapping("/v1/rag/file")
@Slf4j
public class FileController {
private final FileProcessService fileProcessService;
/**
* 檔案上傳 + OCR 擷取
*/
@PostMapping("/upload/ocr")
public ResponseEntity<BaseResponse> uploadFile(@RequestParam("file") MultipartFile file) {
return ResponseEntity.ok(fileProcessService.fileOCR(file));
}
}
@Slf4j
@Service
@RequiredArgsConstructor
public class FileProcessImp implements FileProcessService {
private final Tesseract tesseract;
@Value("${file.upload-dir}")
private String uploadDir;
@Value("${file.convert-dir}")
private String convertDir;
@Override
public BaseResponse fileOCR(MultipartFile file) {
try {
// 建立必要目錄
Files.createDirectories(Path.of(uploadDir));
Files.createDirectories(Path.of(convertDir));
// 儲存原始檔案
String originalFilename = file.getOriginalFilename();
if (originalFilename == null || originalFilename.isEmpty()) {
return BaseResponse.builder().code("9999").msg("Failed").data("Uploaded file has no name").build();
}
String filePath = uploadDir + File.separator + originalFilename;
file.transferTo(new File(filePath));
// 若非 PDF,轉成 PDF
if (!isSupportedFormat(new File(filePath))) {
String[] command = {
"libreoffice", "--headless",
"--convert-to", "pdf",
filePath,
"--outdir", convertDir
};
ProcessBuilder pb = new ProcessBuilder(command);
pb.redirectErrorStream(true);
Process process = pb.start();
process.waitFor();
String fileExtension = originalFilename.substring(originalFilename.lastIndexOf("."));
String pdfFileName = originalFilename.replace(fileExtension, ".pdf");
filePath = convertDir + File.separator + pdfFileName;
}
// 使用 PDFBox 擷取文字
File pdfFile = new File(filePath);
PDDocument document = PDDocument.load(pdfFile);
PDFTextStripper stripper = new PDFTextStripper();
StringBuilder textBuilder = new StringBuilder();
int totalPages = document.getNumberOfPages();
for (int page = 1; page <= totalPages; page++) {
stripper.setStartPage(page);
stripper.setEndPage(page);
String pageText = stripper.getText(document);
textBuilder.append("=== Page ").append(page).append(" ===\n").append(pageText).append("\n\n");
}
document.close();
log.info("Extracted text:\n{}", textBuilder);
return BaseResponse.builder()
.code("0000")
.msg("Success")
.data(textBuilder.toString())
.build();
} catch (IOException | InterruptedException e) {
return BaseResponse.builder()
.code("9999")
.msg("Failed")
.data("Error processing file: " + e.getMessage())
.build();
}
}
/** 檔案格式判斷 */
public static boolean isSupportedFormat(File file) {
String[] supported = {"png", "jpg", "jpeg", "tiff", "bmp", "pdf"};
String name = file.getName().toLowerCase();
for (String ext : supported) {
if (name.endsWith(ext)) return true;
}
return false;
}
}
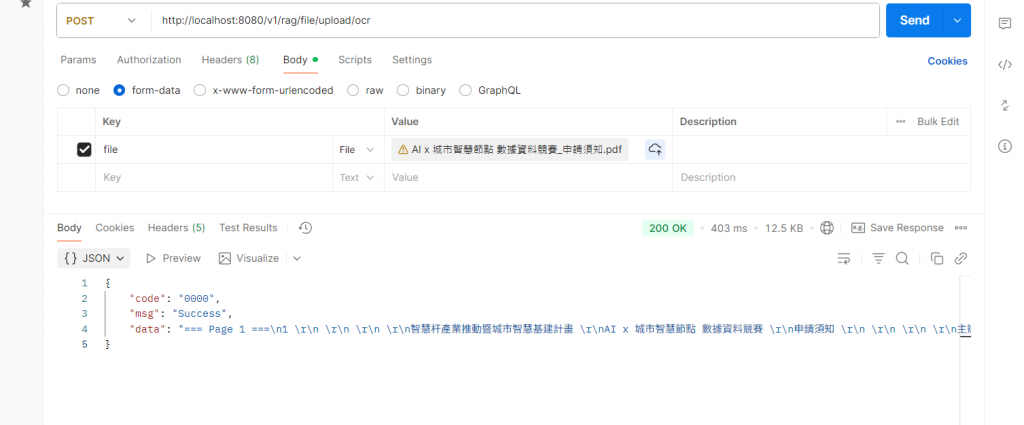
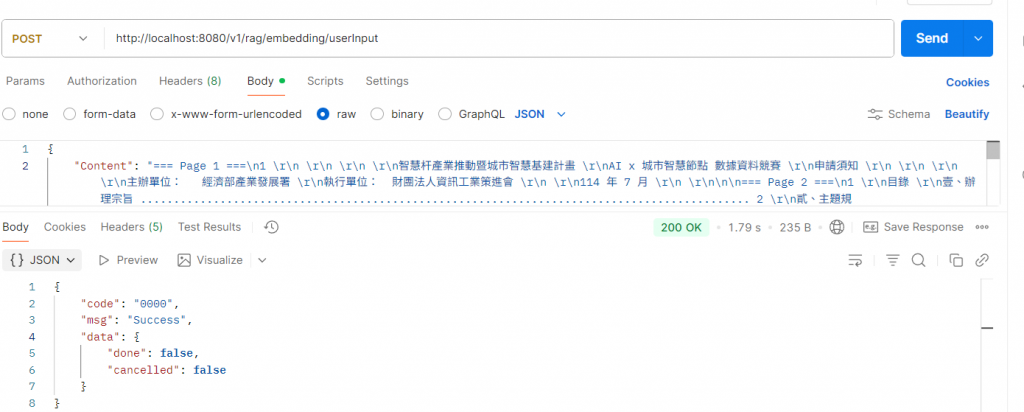
這樣整個流程就串起來了 ,但其實不應該是分開的API應該是轉換完就直接存是比較隊的喔~~
從檔案 → 文字 → 向量 → Qdrant。
| 模組 | 功能 |
|---|---|
| Tess4J | OCR 圖片文字辨識 |
| PDFBox | 解析 PDF 文字內容 |
| Spring Boot | 檔案上傳與 API 控制 |
| Qdrant | 儲存向量資料 |
| Ollama | 本地 Embedding 模型 |
到這裡為止,我們的系統已能「看懂文字」與「記住內容」。
下一篇,我們要讓它「說出答案」。


 iThome鐵人賽
iThome鐵人賽