在 Day25,我們成功啟動了 Qdrant,並能建立與刪除 Collection。
今天,我們要讓這個資料庫「學會記住文字」。我們將整合 Ollama + Spring AI + Qdrant (gRPC),
實作一個能將使用者輸入轉成向量,並存入資料庫的流程。
Ollama Embedding
↓
Qdrant 向量資料庫
↓
語意搜尋(相似度比對)
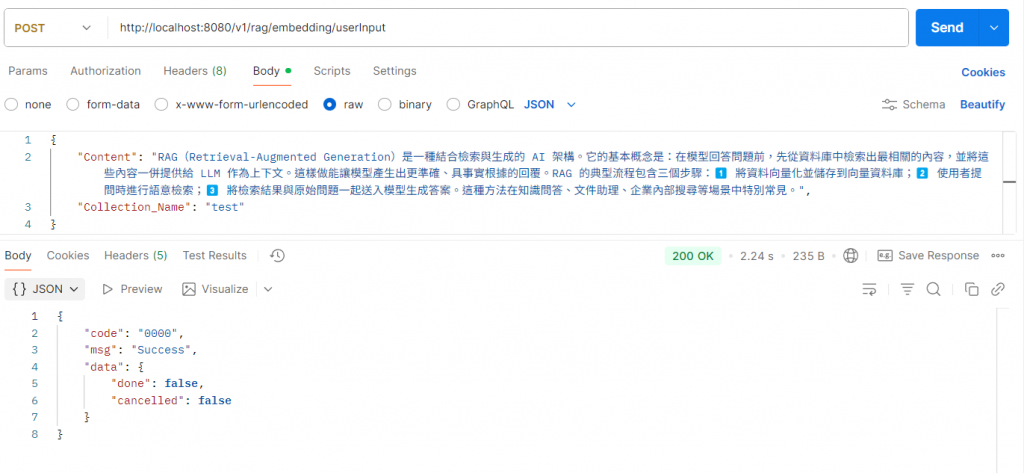
今天的重點是 第一段:Embedding → 存進 Qdrant,
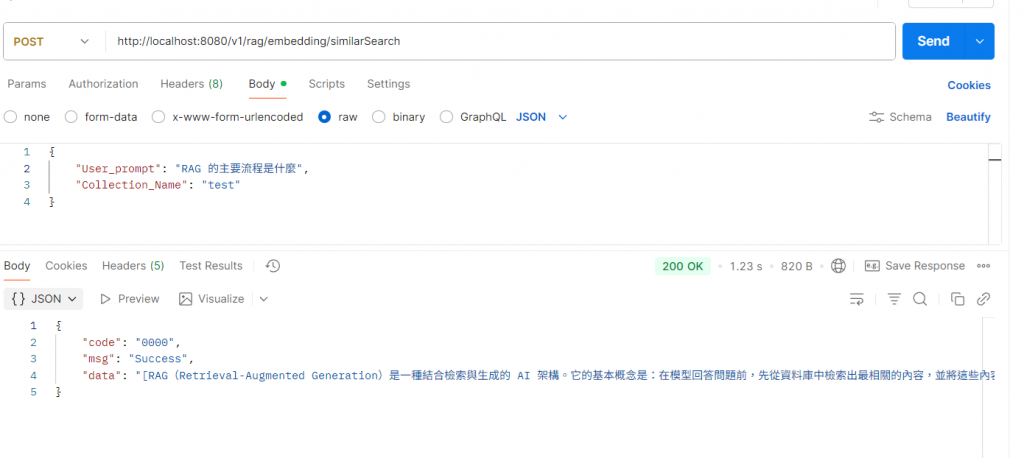
下一篇(Day27)我們會處理「檢索與回答」。
請確認兩個服務都在運行:
# 啟動 Qdrant
docker run -p 6333:6333 -p 6334:6334 qdrant/qdrant
# 啟動 Ollama
ollama serve
ollama pull "{詞遷入模型}"
這個模型會負責將文字轉換成語意向量。
pom.xml)<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring AI - Ollama 支援 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama</artifactId>
</dependency>
<!-- Spring AI - Qdrant 支援 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-qdrant</artifactId>
</dependency>
</dependencies>
這樣 Spring AI 就能自動幫我們建立好 Ollama 與 Qdrant 的連線。
我們設計一個簡單的 REST API,
讓前端可以送文字給後端進行 Embedding + 儲存。
@RestController
@RequiredArgsConstructor
@RequestMapping("/v1/rag/embedding")
@Slf4j
public class EmbeddingController {
private final EmbeddingService embeddingService;
/**
* 文字 embedding
* */
@PostMapping("/userInput")
public ResponseEntity<BaseResponse> userInputEmbedding(@RequestBody UserInputEmbeddingRequest request) {
return ResponseEntity.ok(embeddingService.userInputEmbedding(request));
}
/**
* 相似搜尋
* */
@PostMapping("/similarSearch")
public ResponseEntity<BaseResponse> similarSearch(@RequestBody SimilarSearchRequest request) {
return ResponseEntity.ok(embeddingService.similarSearch(request));
}
}
@Slf4j
@Service
@RequiredArgsConstructor
public class EmbeddingImpl implements EmbeddingService {
private final QdrantClient qdrantClient;
private final OllamaEmbeddingModel ollamaEmbeddingModel;
private final TokenTextSplitter tokenTextSplitter;
/**
* UserInputEmbedding 方法
*/
@Override
public BaseResponse userInputEmbedding(UserInputEmbeddingRequest request) {
// 做 Embedding
List<float[]> embeddingData = embeddingMethod(request.getContent());
// 將 embedding 組裝成 PointStruct
List<PointStruct> points = new ArrayList<>();
for (float[] embedding: embeddingData) {
PointStruct point = PointStruct.newBuilder()
.setVectors(vectors(embedding))
.putPayload("document", value(request.getContent()))
.setId(Points.PointId.newBuilder().setUuid(UUID.randomUUID().toString()).build())
.build();
points.add(point);
}
// 將 embedding 文本存入 Qdrant
try {
Future<UpdateResult> future = qdrantClient.upsertAsync(request.getCollectionName(), points);
return BaseResponse.builder().code("0000").msg("Success").data(future).build();
} catch (Exception e) {
return BaseResponse.builder().code("1111").msg("Fail").data(e.getMessage()).build();
} }
/**
* SimilarSearch 方法
*/
@Override
public BaseResponse similarSearch(SimilarSearchRequest request) {
// 做 Embedding
List<float[]> embeddingData = embeddingMethod(request.getUserPrompt());
List<Float> embeddingFloatList = new ArrayList<>();
// 遍歷 embeddingData
for (float[] vectorArray : embeddingData) {
for (float value : vectorArray) {
embeddingFloatList.add(value);
}
}
try {
ListenableFuture<List<Points.ScoredPoint>> future = qdrantClient.searchAsync( Points.SearchPoints.newBuilder()
.setCollectionName(request.getCollectionName())
.addAllVector(embeddingFloatList)
.setWithPayload(Points.WithPayloadSelector.newBuilder().setEnable(true).build())
.setLimit(3)
.build());
List<Points.ScoredPoint> results = future.get();
// 處理搜尋結果
List<String> decodedResults = new ArrayList<>();
for (Points.ScoredPoint point : results) {
// 從 payload 中獲取 "document" 欄位的值
JsonWithInt.Value value = point.getPayloadMap().get("document");
if (value != null && value.hasStringValue()) {
// 直接獲取字串值
String decodedString = value.getStringValue();
decodedResults.add(decodedString);
}
}
return BaseResponse.builder().code("0000").msg("Success").data(decodedResults.toString()).build();
} catch (Exception e) {
return BaseResponse.builder().code("9999").msg("Failed").data(e.getMessage()).build();
}
}
/**
* Embedding 方法
*/
private List<float[]> embeddingMethod(String content) {
// 轉成 Document
Document document = Document
.builder()
.withContent(content)
.build();
// 切分文本
List<Document> chunks = tokenTextSplitter.split(document);
BatchingStrategy batchingStrategy = new BatchingStrategy() {
@Override
public List<List<Document>> batch(List<Document> documents) {
// 將所有文檔作為單一批次返回
return List.of(documents);
}
};
// Embedding
return ollamaEmbeddingModel.embed(
chunks,
null,
batchingStrategy
);
}
}
@Data
public class SimilarSearchRequest {
@JsonProperty("User_prompt")
@NotNull
private String userPrompt;
@JsonProperty("Collection_Name")
@NotNull
private String collectionName;
}
@Data
public class UserInputEmbeddingRequest {
@JsonProperty("Content")
@NotNull
private String content;
@JsonProperty("Collection_Name")
@NotNull
private String collectionName;
}
這裡我加入一段 RAG 的流程介紹
| 步驟 | 處理項目 | 使用元件 |
|---|---|---|
| 1️⃣ 轉成文字文件 | Document |
Spring AI Core |
| 2️⃣ 切分長文本 | TokenTextSplitter |
Spring AI Text 工具 |
| 3️⃣ 生成向量 | OllamaEmbeddingModel |
本地嵌入模型 |
| 4️⃣ 寫入資料庫 | QdrantClient.upsertAsync() |
gRPC Qdrant 連線 |
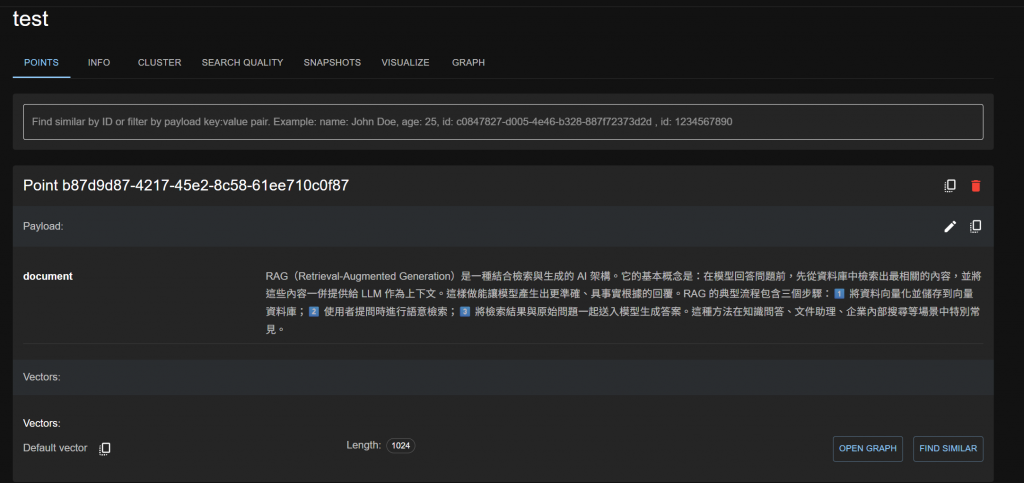
我們已成功完成:
接下來,我們要讓這些向量「被搜尋、被理解」。


 iThome鐵人賽
iThome鐵人賽