整理一下昨天遇到的 Error 訊息
雖然 Day 23 看起來一切順利,但實際上在程式碼的測試過程中,還是有發生幾個小錯誤。
感覺應該是蠻常發生的問題,就特別記錄下來。
session = boto3.Session(profile_name="dev-call-bedrock")
client = session.client("bedrock", region_name="ap-northeast-1")
prompt = f"""
請根據抽到的塔羅牌,解讀近三個月的財務運勢。
{cards}
"""
body = {
"system": system_role,
"anthropic_version": "bedrock-2023-05-31",
"messages": [
{"role": "user", "content": [{"type": "text", "text": prompt}]}
],
"max_tokens": 2000,
"temperature": 0.7
}
response = client.invoke_model(
modelId="anthropic.claude-3-7-sonnet-20250219-v1:0",
body=json.dumps(body)
)
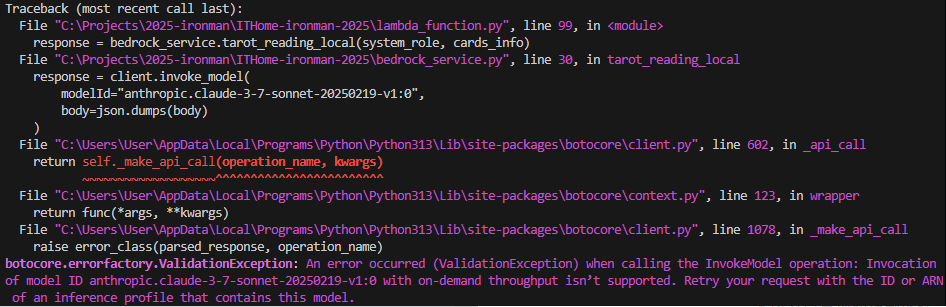
錯誤訊息出現在:invoke_model
錯誤原:調用了錯誤的 API
AWS Bedrock 有兩個主要 API:bedrock 和 bedrock-runtime
| Client 名稱 | 用途 |
|---|---|
| bedrock | 模型管理(列出模型、設定權限) |
| bedrock-runtime | 模型推論(呼叫基礎模型,如 Claude、Titan) |
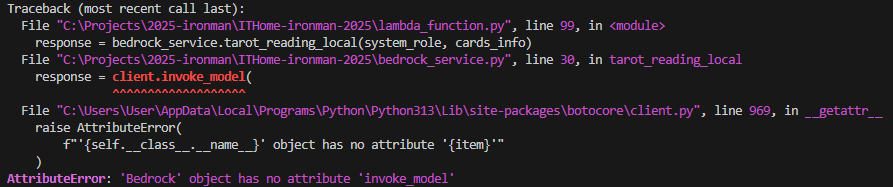
session = boto3.Session(profile_name="dev-call-bedrock")
- client = session.client("bedrock", region_name="ap-northeast-1")
+ client = session.client("bedrock-runtime", region_name="ap-northeast-1")
看起來很像,使用方式也很像,但在定義上卻完全不一樣。
An error occurred (ValidationException) when calling the InvokeModel operation: Invocation of model ID anthropic.claude-3-7-sonnet-20250219-v1:0 with on-demand throughput isn’t supported. Retry your request with the ID or ARN of an inference profile that contains this model.
本以為只是換個模型名稱,結果沒想到牽扯到 Bedrock 的另一套運作邏輯。
錯誤原因出在:on-demand throughput isn’t supported
看到 on-demand,立刻聯想起 Day 20. 沒踩點坑怎麼算是技術文章 學到的 跨區域推論
AWS Bedrock 的 AI Model 有兩種模式(inference):
| 項目 | 說明 |
|---|---|
| 特性 | 無需預先保留運算資源價格依照輸入與輸出 token 數計費(pay-per-token) |
| 適合場景 | 測試、開發階段不需長時間穩定負載 |
| 限制 | 不是所有模型都支援 |
使用方式:
直接使用模型 ID(modelId)就能呼叫,ID 可從 Amazon Bedrock > 模型目錄 查詢。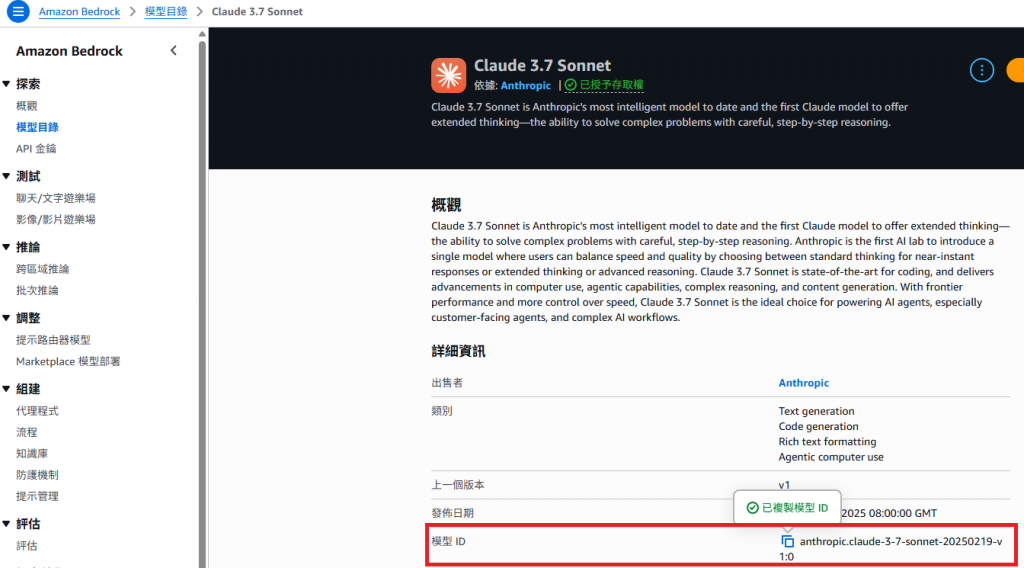
⚠️ 高流量應用若大量同時請求,可能會遇到限流(ThrottlingException)。
AWS 在 2024 年底推出的新特性,用來解決「模型只在特定 Region 可用」的問題
| 項目 | 說明 |
|---|---|
| 特性 | 允許從任意 Region 呼叫模型,即使模型不在當地也能使用。 |
| 適合場景 | 模型僅在特定 Region 提供時(例如 Claude 3.7 Sonnet 僅在 us-east-1),但應用程式部署在其他地區。 |
| 限制 | 並非所有模型都支援,且跨區會有少量傳輸費用。 |
使用方式:
需透過 推論設定檔(Inference Profile) 進行呼叫: 可從 Amazon Bedrock > Cross-region inference 查詢到模型的 ARN。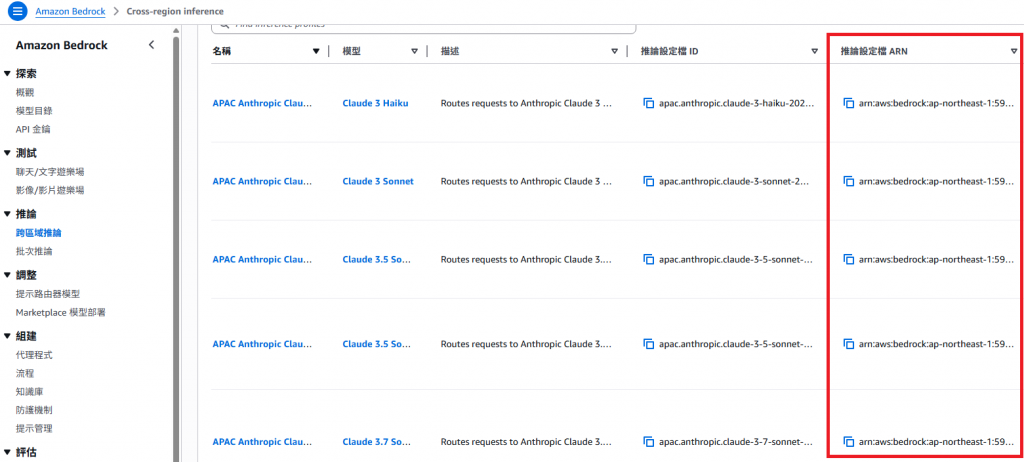
推論設定檔(Inference Profile)
AWS 會將特定模型的運算資源包裝成「推論設定檔」,提供一個 ARN 讓開發者在程式中指定呼叫模型。像 Claude 3.7 Sonnet 這類大型模型,就必須透過 inference profile 呼叫,而不能直接使用 Model ID。
response = client.invoke_model(
- modelId="anthropic.claude-3-7-sonnet-20250219-v1:0",
+ modelId="arn:aws:bedrock:ap-northeast-1:590184072539:inference-profile/apac.anthropic.claude-3-7-sonnet-20250219-v1:0",
body=json.dumps(body)
)
其實在最一開始,使用的測試模型是 claude-3-haiku-20240307-v1:0,支援 on-demand 模式,所以直接使用 Model ID 做呼叫。
本以為換成 Claude 3.7 Sonnet 不過是換個 Model ID,能有什麼問題?
沒想到......
就當作複習 AI Model 在 AWS 中的兩種使用模式吧!
這次碰到的錯誤其實剛好可以學習到 AWS 在模型調用上的設計:
雖然過程不算順利,但這次的錯誤作為補充基礎知識的契機,也更加釐清了 Bedrock 背後的運作方式。