在深度學習模型的發展當中, Transformer 是一個劃時代的模型。
在 Transformer 出現之前,RNN 等神經網路模型和 Encoder–Decoder 架構是處理序列資料的主流方法,但它們在文本內長距離關係與計算效率上都有明顯的限制。
Transformer 的誕生,重新定義了建立序列的方式,也成為了後來眾多大型語言模型(如 BERT、GPT)的基礎。
今天就要來看看 Transformer 究竟是什麼樣的一個模型~~
Transformer 採用的是 Encoder 跟 Decoder 的架構
🌟 不同於傳統的 recurrent 結構,Transformer 在這個架構中使用 stacked self-attention 和 全連接層(feedforward layers) 來建立模型。
以下是Transformer的模型架構圖: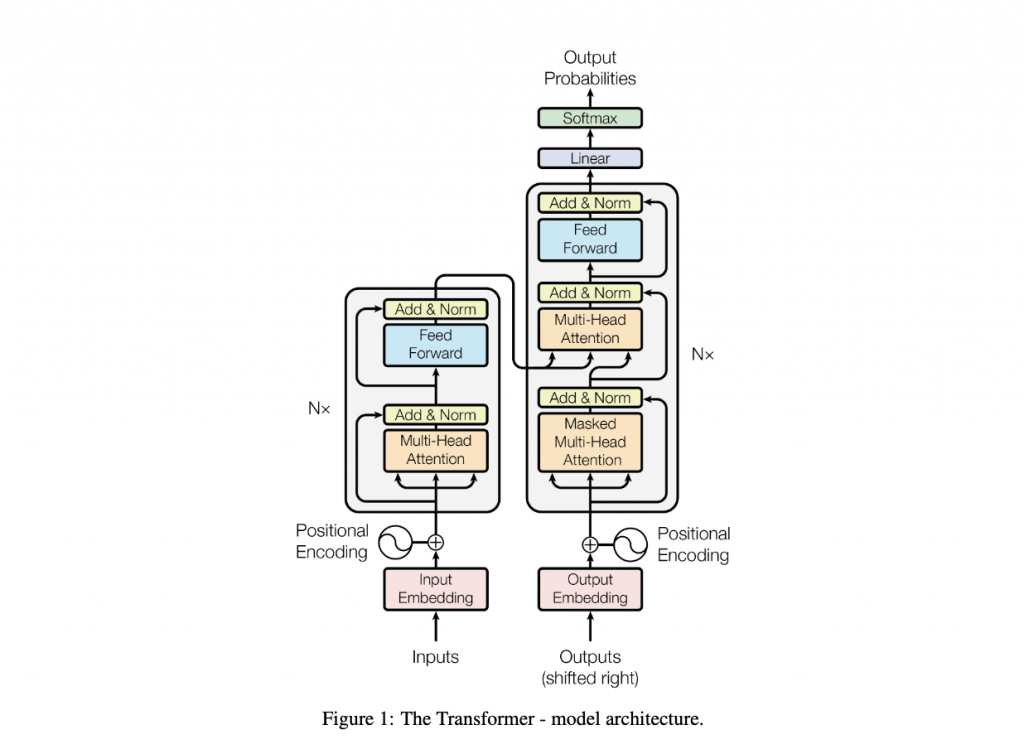
image source
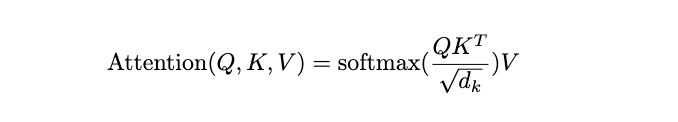
Reference:Attention Is All You Need


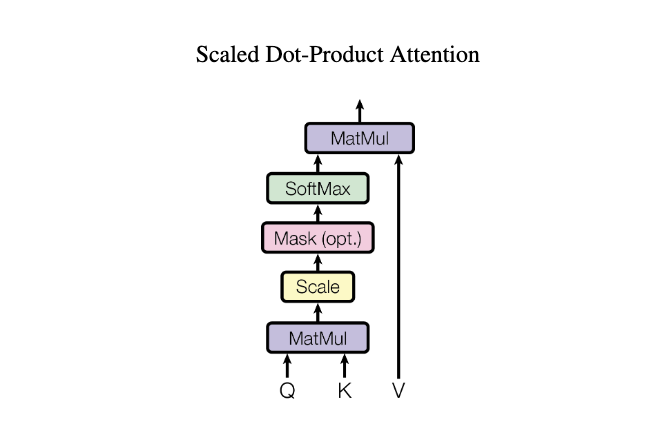
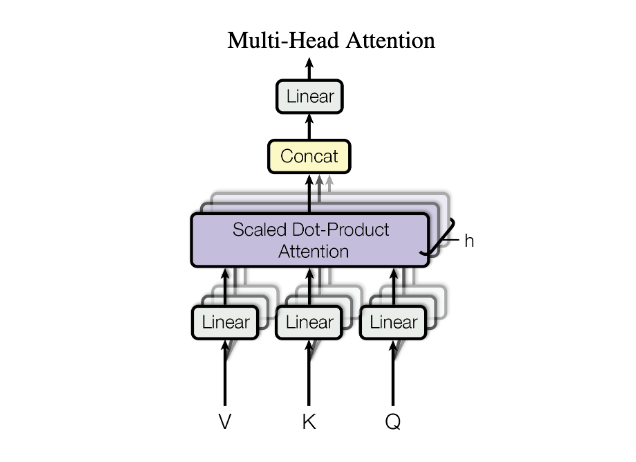
 iThome鐵人賽
iThome鐵人賽