2025 iThome 鐵人賽
分享至
昨天我們提到 Transformer 是基於 Attention 的架構,沒有像 RNN 那樣逐步處理字串。
這時候就會有一個問題,如果它不是按照順序讀句子,那它是怎麼知道哪個字在前、哪個字在後呢?
因此, Transformer 需要額外提供「位置資訊」,這就是 Positional Encoding(位置編碼)的作用。
今天就要來談談 Positional Encoding 是在做什麼的~~
Reference 1Reference 2Reference 3Reference 4
IT邦幫忙
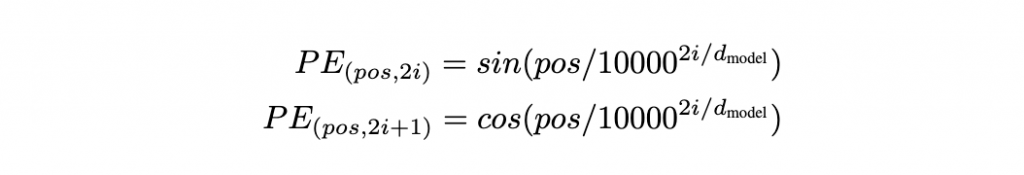


 iThome鐵人賽
iThome鐵人賽