
昨天設計完 Todo List Memory,今天迫不及待地來跑實驗看看效果。
理想很豐滿,現實卻有點骨感。
先上圖:
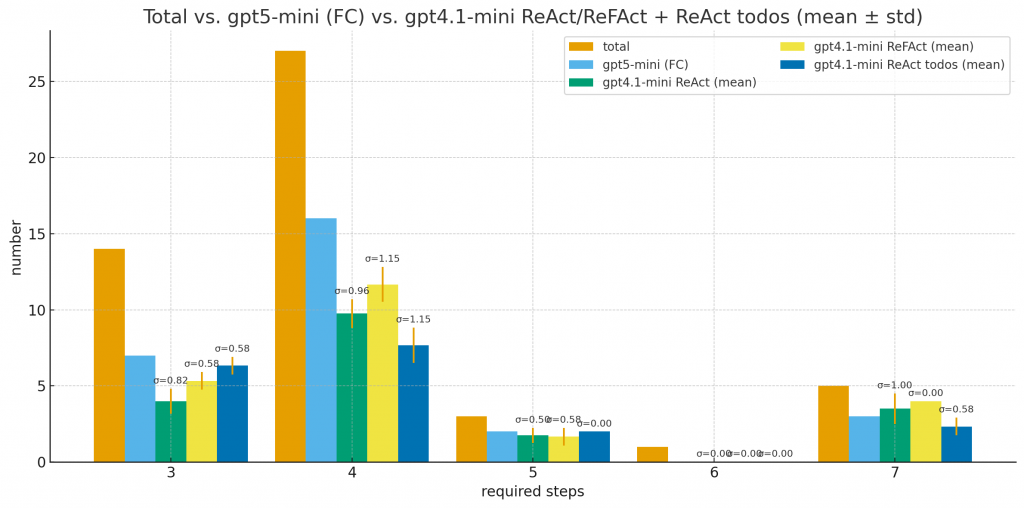
數據顯示:
仔細翻了 log 和中間過程後,發現了幾個關鍵問題:
雖然我在 system prompt 裡寫得很清楚:
[todo]: 任務描述
[done]: 任務描述 → result: 結果
[cancel]: 任務描述 → reason: 原因
但實際上 LLM 的輸出經常「自由發揮」:
→ result:
[done] 寫成 [completed]
這種隨機性導致我的解析邏輯時常出錯,todo list 就亂掉了。
根本原因:純文字格式對 LLM 來說太「自由」了,沒有強約束。
這是最嚴重的問題。
在原本的 messages append 架構下,如果某個 action 失敗了:
user: 搜尋 "Qst magazine publisher"
assistant: [執行 web_search]
tool_result: 沒找到相關資訊
這樣 LLM 能直接看到工具執行的狀態,並據此調整下一步。
但在 todo list 架構下,我只把 todo list 本身存下來,並沒有把「action 的執行狀態」明確記錄在 list 裡。
結果就是:
[done]
感覺很分割,像是左手做的事右手不知道。
我的設計是這樣的:
update()
update()
問題來了:兩個 state 都會改 todo list,但它們的「視角」不同。
Action state 的問題:
[cancel]
Reflection state 的問題:
Rule 太弱了,缺乏更細緻的狀態管理機制。
雖然效果不理想,但我還是想了幾個可能的改善方向:
不要用純文字,改用一個結構化的數據格式,例如:
class TodoItem:
id: str
description: str
status: Literal["todo", "done", "cancel"]
result: Optional[str]
reason: Optional[str]
然後讓 LLM 只能透過特定的「操作指令」來修改:
add_task(description)
complete_task(id, result)
cancel_task(id, reason)
update_task(id, new_description)
這樣就能強制 LLM 遵守格式,避免隨機輸出。
讓 todo list 不只是「待辦清單」,而是包含更多上下文資訊:
[current]: Find the founding year of the publisher of Qst magazine
[status]: Searching... (attempt 1/3)
[last_result]: No results found for "Qst publisher"
---
[todo]: Find the founding year of the publisher of Qst magazine
[todo]: Reverse the founding year number
...
這樣即使 action 失敗了,LLM 在下次更新時也能看到「上次做了什麼、結果如何」,避免狀態割裂。
或許問題不在 todo list 本身,而是更新時機不對。
現在的流程是:
Reasoning → Action → Reflection → Update Todo
但或許應該有一個獨立的 Planner State:
這樣職責更清楚,也能避免多個 state 互相干擾。
坦白說,這次的實驗讓我意識到:
Todo list memory 不是我想的那麼簡單,用一個 text file 就能搞定的東西。
它需要:
這些都需要時間來打磨。
但現在鐵人賽已經接近尾聲,剩下沒幾天了,我不想在這個地方卡太久。
所以決定:
MCP(Model Context Protocol)是一個更實用的方向,能讓 agent 跟外部工具有更好的整合。
之後如果有時間,再回來把 todo list 這塊補完。
