昨天跑完最 naive 的 ReAct baseline,今天就來實作一個更進階版本 —— 加上 Reflection State。
這個版本我暫時稱作 ReFAct(硬塞F)
ref: reflextion https://arxiv.org/pdf/2303.11366
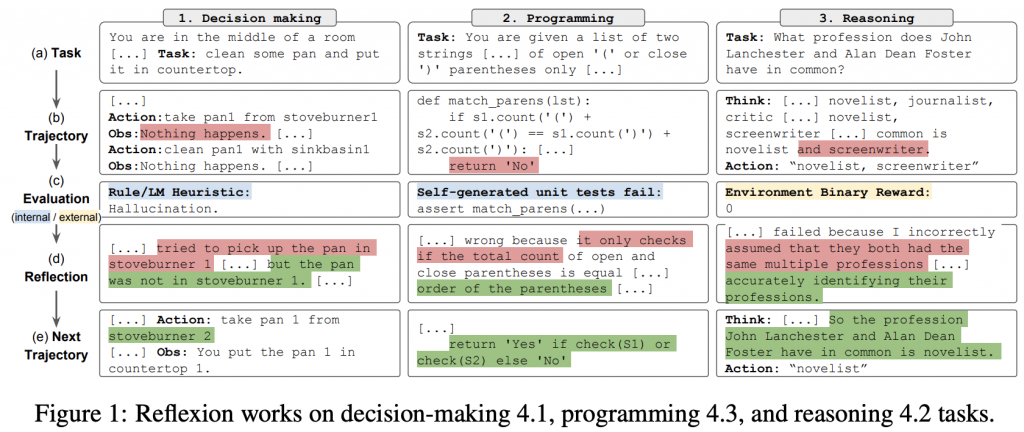
做法如上,就是請 LLM 根據 evaluation result,進行反思
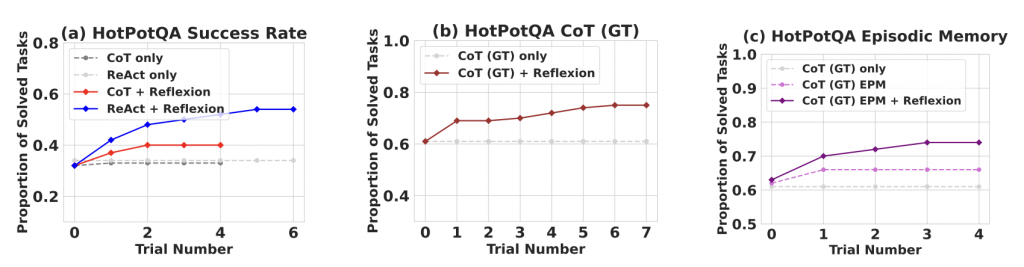
論文中的實驗數據也明確表示了差異
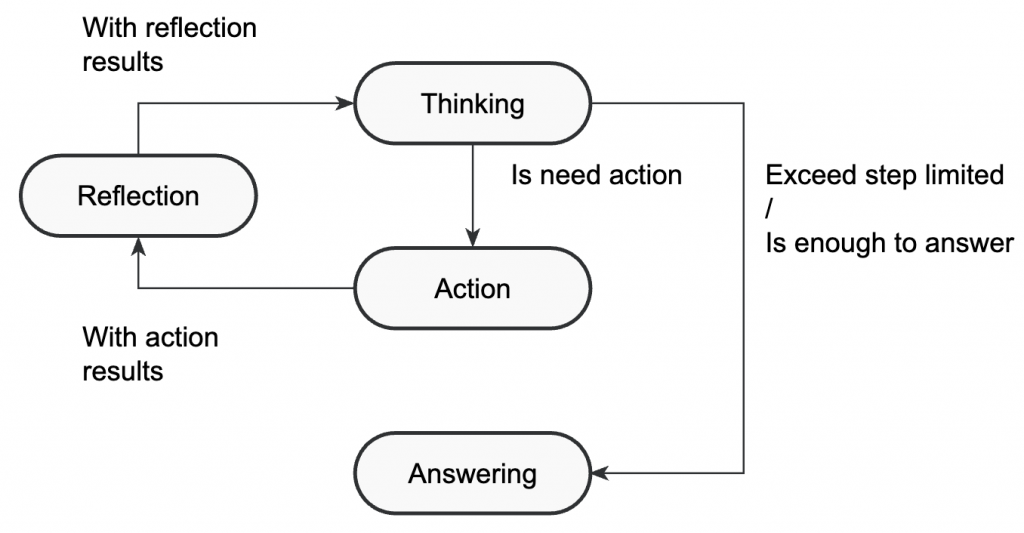
由於整個系統是採用 State Pattern 設計,要加入一個新的狀態其實非常簡單。
class ReflectionState(State):
async def run(self, memory: "Memory") -> AsyncIterator[str]:
messages = await get_messages(memory)
content, _ = await get_response(model_name=REFLECTION_MODEL, messages=messages)
if content:
for chunk in content:
yield chunk
await memory.update(
[Message(role=Role.ASSISTANT, content=f"<reflection>{content}</reflection>")]
)
async def next_state(self, memory: "Memory") -> Enum:
return ReFact.REASONING
在這裡,Reflection 的輸出會直接包在 <reflection></reflection> 標籤中附加進記憶體。
下次進入 Reasoning state 時,模型就能看到自己的反思內容,並根據它修正策略。
只要把 Action 的下一步改成 Reflection 即可:
class ActionState(State):
async def run(self, memory: "Memory") -> AsyncIterator[str]:
...
async def next_state(self, memory: "Memory") -> Enum:
return ReFact.REFLECTION
最後在 net map 中註冊這個新狀態:
def create_net() -> dict[Enum, State]:
from .action import ActionState
from .answer import AnswerState
from .reasoning import ReasoningState
from .reflection import ReflectionState
return {
ReFact.REFLECTION: ReflectionState(),
ReFact.REASONING: ReasoningState(),
ReFact.ACTION: ActionState(),
ReFact.ANSWER: AnswerState(),
}
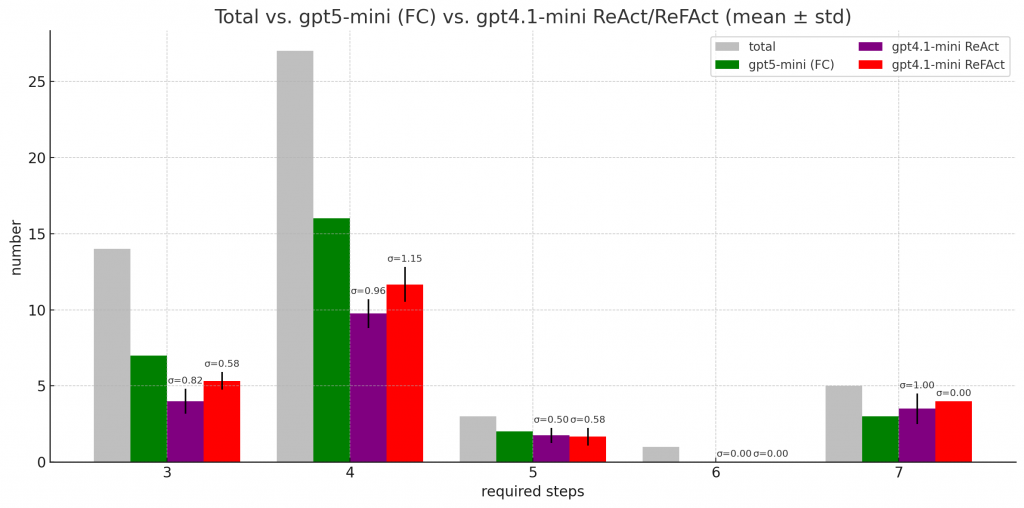
初步結果算是有趣。
很明顯看到比純 ReAct 好了一點
目前的 memory structure 還是單純一直 append message
明天來看一下 context engineering 相關的東西好了

