今天繼續看 context engineering 相關的東西。
昨天介紹的實驗都是 base on NIAH 的 dataset 做延伸。
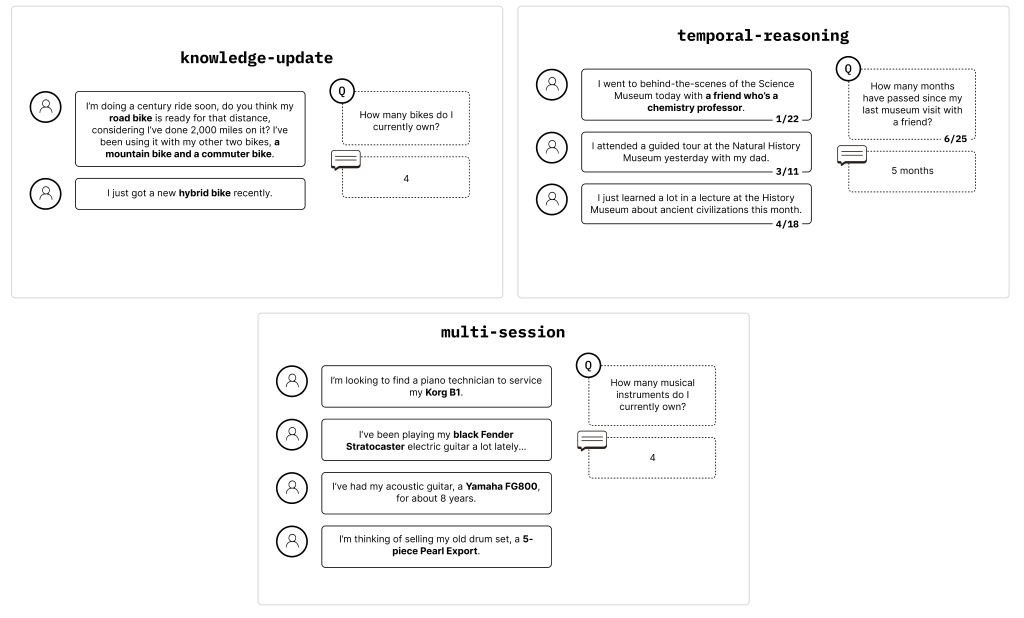
這個實驗則是在 LongMemEval 上的延伸,LongMemEval 不像 NIAH 一樣,故意在超長文本中塞 needle。
LongMemEval 更貼近真實應用場景,他的上下文本是真的 conversational question-answering
然後任務是需要在上下文本中找到知識點拼湊出正確答案,甚至需要推理或是總結能力。 如下面的例子
這邊的實驗設計就專門在探討移除雜訊 (Focused content) 跟 (Full content) 之間的差異
想當然爾,Focused content 會更好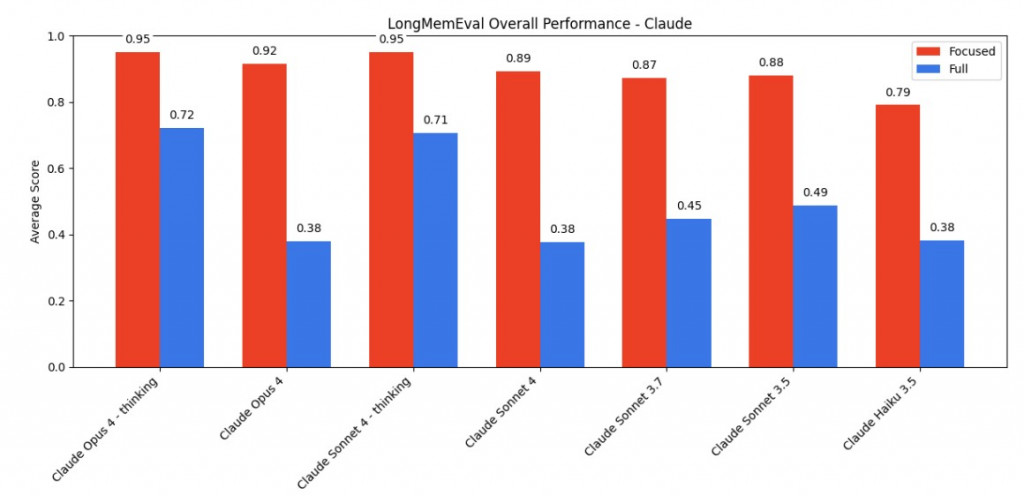
覺得這邊設計如果要更有趣,可以把 Focused 的 chunks,一直擴展到跟 Full content 一樣大。
最後一個實驗應該是 chroma 自己設計的 叫做 repeated words
每題中都有 common word * n 加隨機插入的 unique word * 1
One example prompt is:
Simply replicate the following text, output the exact same text: apple apple apple apple apples apple apple apple apple apple apple apple apple apple apple apple apple apple apple apple apple apple apple apple apple
model 除了需要輸出正確數量的 common word,還需要精準的輸出 unique word。
感覺是對 model 的一種更困難的考驗,model 需要明確知道 unique word 在哪之外,總共有幾個 common word 之外,還需要精確輸出 unique word。
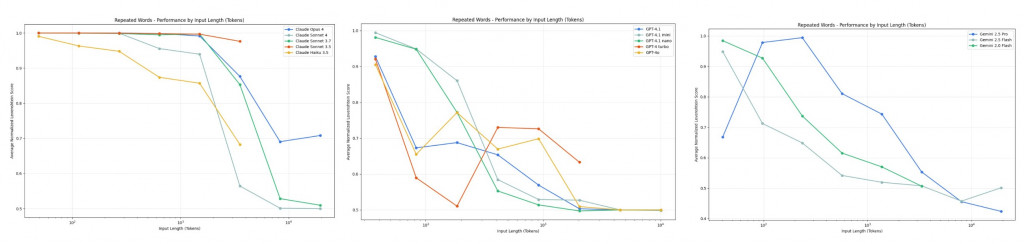
那當來到 10000 token 的 input 時,各家的準確度都快剩下 50% 了。
從這個實驗可以知道,即使沒有雜訊 (每個token都算重要),當 context 變長的時候,LLM 的辨別能力也是隨之下降。
Conclusion
回到 anthropic 的這篇文章
首先他們做了一個小總結 for 為何更長的 context 會降低 LLM 的 performance。
這邊提到了 "attention budget",由於 Transformer 架構的緣故,當 token 越多 self-attention block 中的 softmax 會被稀釋掉,導致該給 attention 的 token 沒有給到。
太攏長,太簡短都是不好的行為。
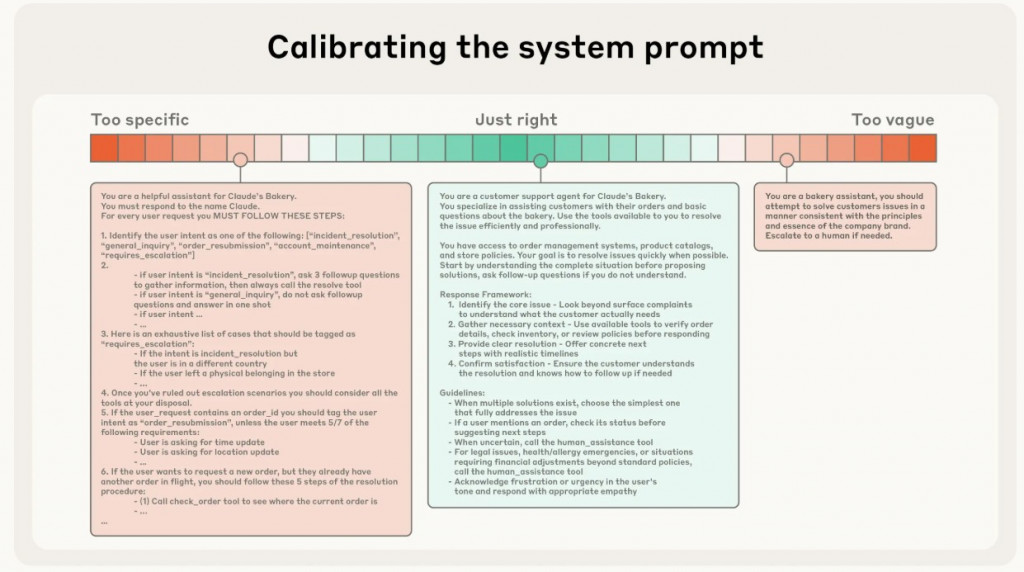
設計原則:
給 few-shot prompting
定義:當對話接近 context window 限制時,總結其內容,並用摘要重新啟動新的 context window。
實作範例(Claude Code):
定義:Agent 定期將筆記寫入 context window 外的持久化記憶體,這些筆記會在之後的時間被拉回 context window。
優勢:提供最小開銷的持久記憶。
不同任務特性適合不同方法Compaction:維持需要大量來回互動的任務的對話流程Note-taking:擅長有明確里程碑的迭代開發Multi-agent architectures:處理複雜的研究和分析,其中並行探索帶來回報

