在 agent-brain 中 memory 代表著儲存記憶與提取記憶的地方
又 in each state 其實絕大多數都是靠 LLM 自己做 reflection / reasoning / answer
那 LLM 做這些 response 的 input 又來自 memory,所以可以知道 memory 是一個超級重要的 component
自認在這塊還沒有非常深入的理解
所以在切入實作 memory architecture 之前,我想先 survey 這邊相關的東西
what's the difference between context / prompt engineering
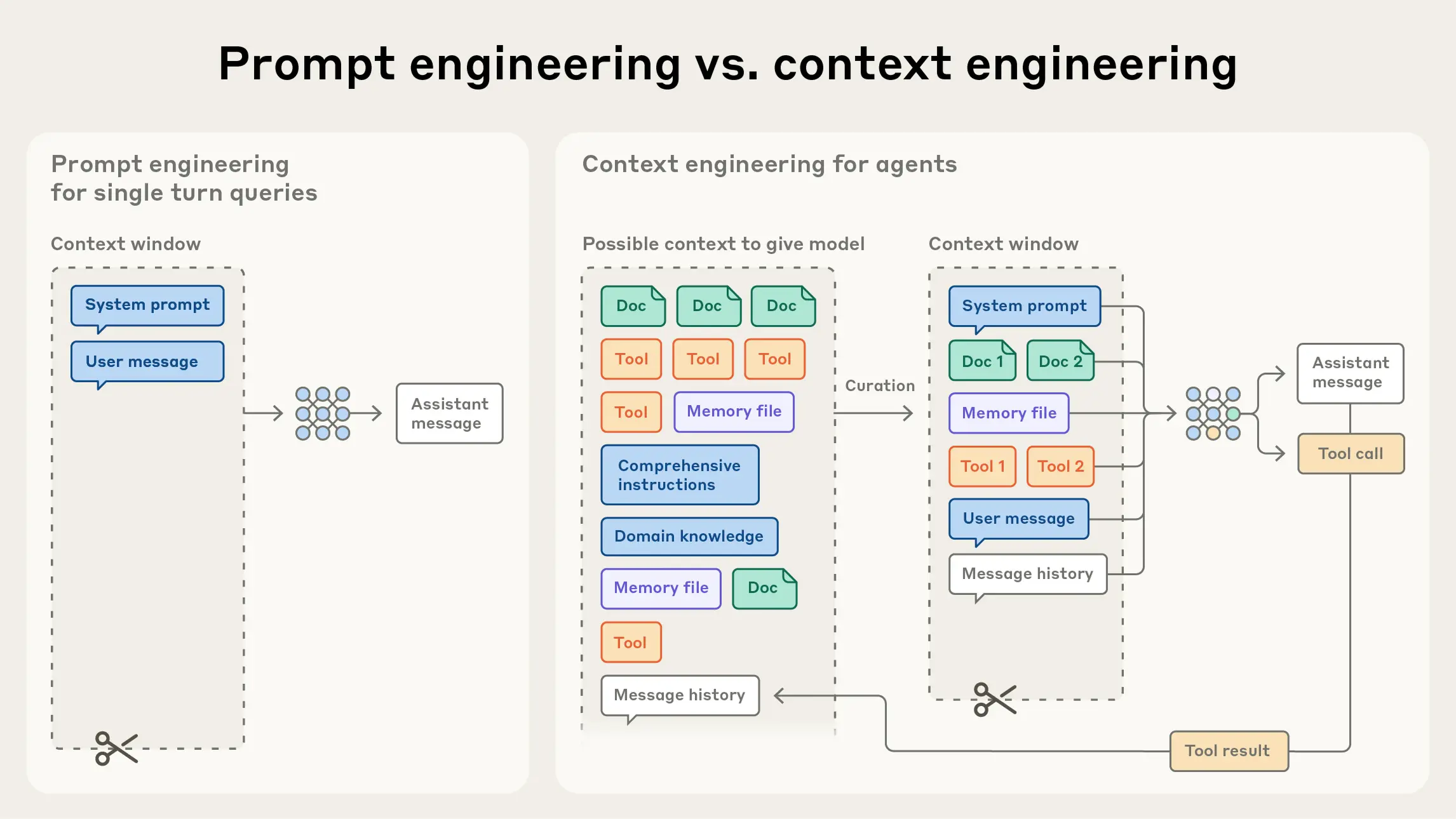
Prompt engineering 會比較 focus 在 single turn 的 LLM 上,像是調整 System prompt,給 few show examples,寫一些明確的規則讓 llm 表現得更好
Context engineering 則是想要探討 multi turn 的 LLM 中,由於可能整個過程經過了多個 state 可能包含了 tool results / instructurn / error message / history message / task, sub-task 等等,當這一堆都跑進來的時候,該怎麼 "捨棄" 不重要的資訊,進而提升我們 LLM 的 performance
這邊主要看了兩個 reference [Context-Rot] & [NoLiMa]
那文章是如何量化 context engineering 這點很重要的呢?
這邊來看一下他們設計的精巧的 dataset - extend NIAH
NIAH 是 Needle in a Haystack 的縮寫,顧名思義就是 大海撈針,他是一個測試 LLM 是否能在長上下文(Haystack)中找出正解(needle)的資料集,下面是一個例子
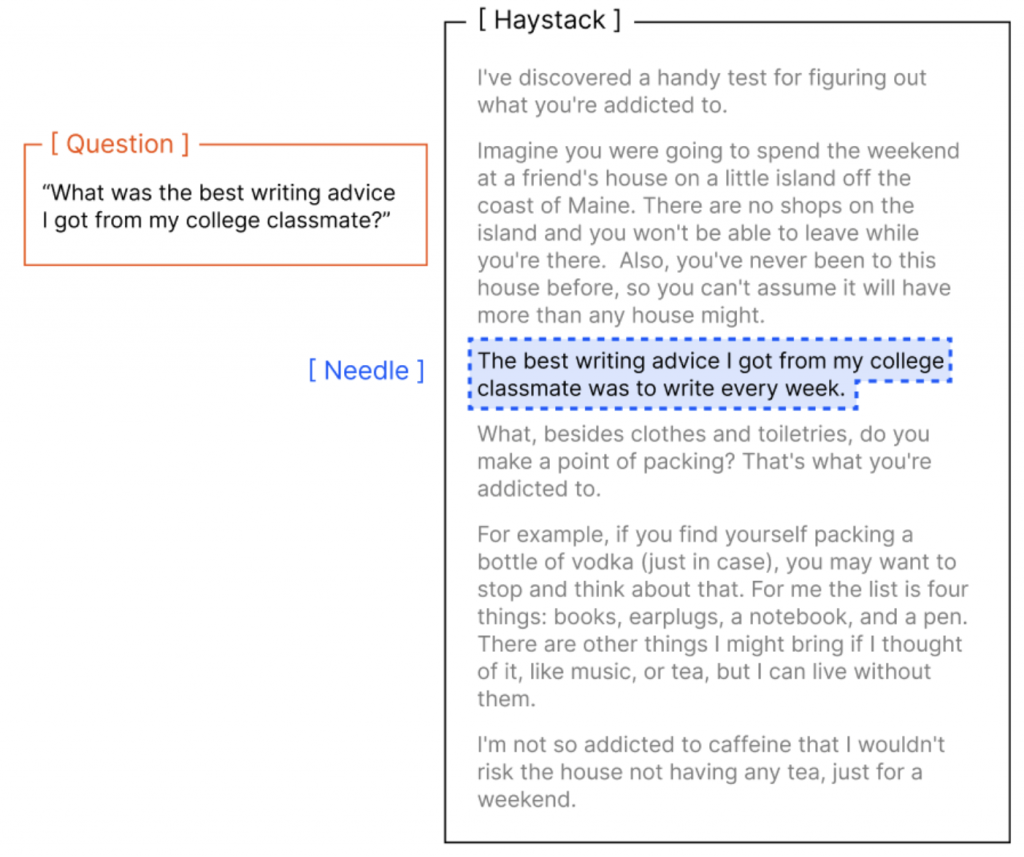
他會把答案塞在某個片段中。
但可以看到 question 與 needle 之間有非常強烈的關聯,可能就直接包含與問題一樣的 term,並且上下文本可能是與這個 needle 不太相干的東西。這就好比在一群狗之中找出威利,是有一點那麼突兀。
有另一個 dataset 為了要解決這個問題 [NoLiMa] 所以他除了把 needle 藏在很長的上下文之外,這個 needle 還做了特化處理。
需要 model 有 prior knowledge 才能回答出來,此時 model 在這種情況下會比原本很 explicitly 的 needle 表現得還不好。
e.g., needle 是 整個大台北地區在 2025-10-06 的天氣超好,然後 question 是: 2025 中秋節松山的天氣如何?
Anyway,Context Rot 則是朝更細緻的方向去設計
這個實驗中,藍線 跟 紅線 分別代表 question-needle pair 的 similarity 很高 or 很低
然後每個小框框的縱軸代表 accuracy 橫軸代表 context 的長度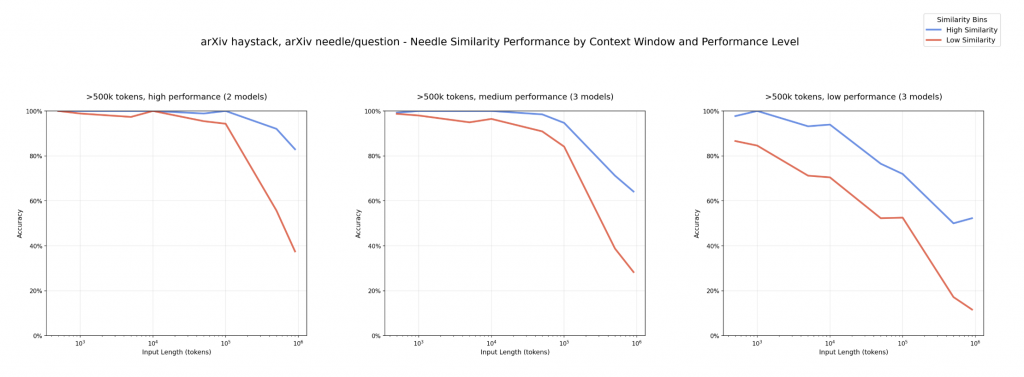
這個實驗則是加入了 distractors。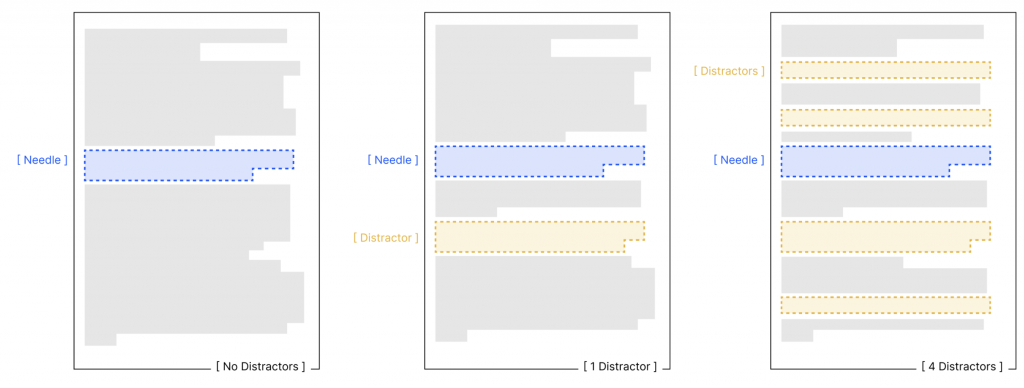
Distractor 的定義是與 question 相關,但是不是正解的 needle,那這種東西跟現實生活中的使用情境又會更相近了。我們沒辦法保證對應於每個 question 的 "needle" 在整個上下文中是非常與眾不同的存在。
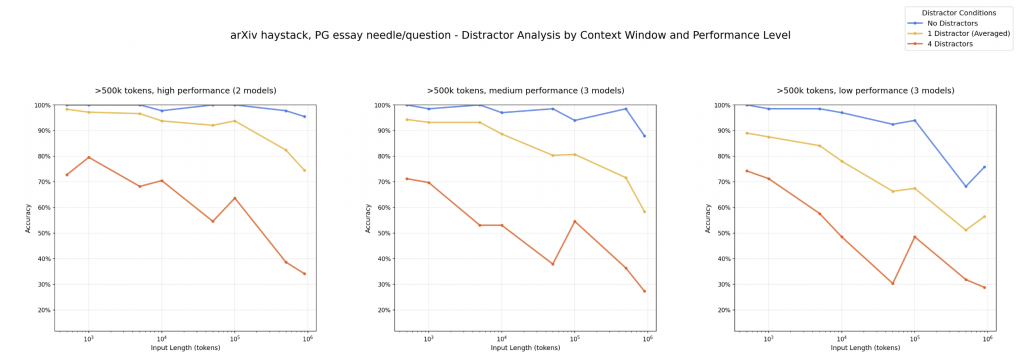
那實驗結果也表明,當出現 distractor 時,整個 performance 又更慘了,並且在上下文長度相對較短的情況下 (10^3 tokens) 就表現得沒有很好。
這個實驗則是將原本的 HayStack 分類段落類型後去做 shuffle,如下
那為何要這樣做呢?我的超譯是 當我們在跑 multi-step agent 時候,其實整個上下文也充斥著不同的段落類型,e.g., 有 tool response / reflection response / answering response
那如果 needle 在未經整理的狀態下丟在 context 中 vs needle 是一個很突兀的點出現在 context 中 (shuffled)
那效果如何呢?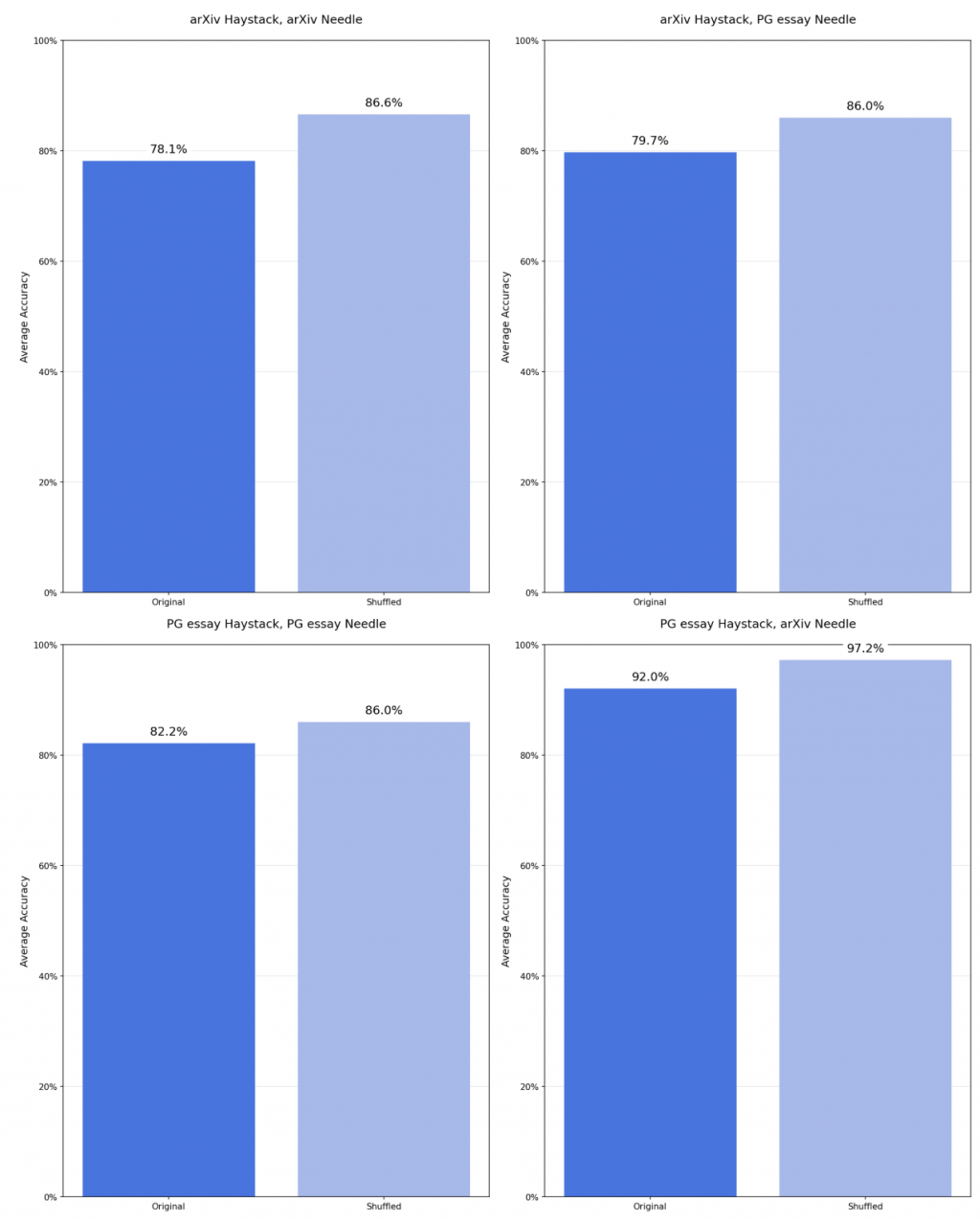
如圖,有 shuffled 過的 context (-> 讓 needle 很突兀),則 llm 的表現也會提高。
which means: 由於我們無法知道 question 會長怎樣,所以如果我們更 originize 的去讓每個 session 之間有明確的劃分,那效果應該不錯? (我自己超譯)
本來要打算講 claude context engineering 那篇的,但認真看了 context rot 之後,真的是一篇實驗非常精實的文章,感謝 Chroma。也讓我體悟到很多實驗背後的意義。
明天再繼續補完 實驗 4 & 5 並且切回 claude context engineering 的介紹。
reference:
Effective context engineering for AI agents
Building effective agents
Context-Rot
NoLiMa: Long-Context Evaluation Beyond Literal Matching
The Magical Mystery Four: How Is Working Memory Capacity Limited, and Why?

