
我的公司是一個電商平台,電商平台會有一些大流量的場景,像是平常有什麼搶購活動,或是有任何已知大型活動我們會需要預先加開機器,背後都會有大量的 Pod 需要起來
任何只要發生了「大量 Pod 需要創建起來」、「或是大量的 Node 建立」都會發現 Pod 要等一個 IP 等好久…
背後的問題我們已經定位到了,今天就來分享一下這個問題
EKS Version: 1.32
Cilium Version: 1.17+
Routing mode: Native
IPAM Mode: AWS ENI
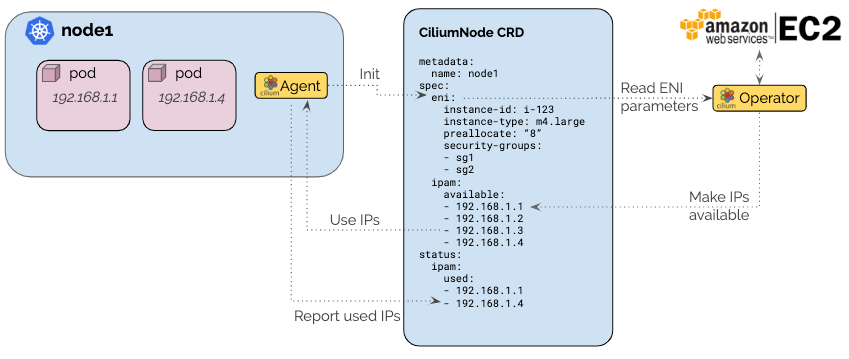
圖片取自:https://docs.cilium.io/en/stable/network/concepts/ipam/eni/#ipam-eni
正如我文章引言所述,實際對應的情境和症狀是這樣:
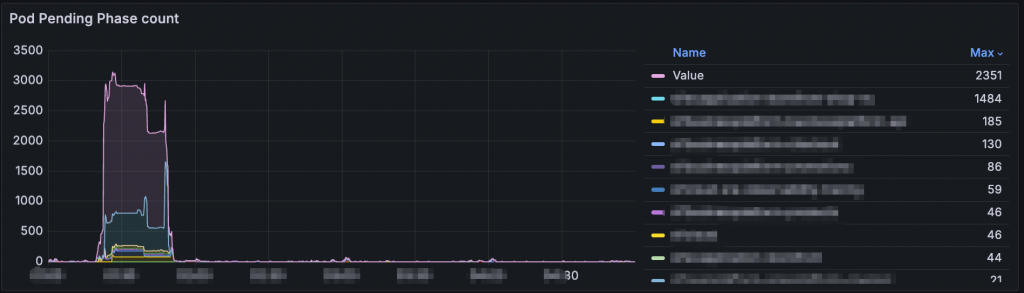
可以看一下這張圖,我們 Pod Pending 數量高達 2351
接著是這裡,這是 Pod 從被創建變成 Running 經過的時間,P50 竟然是 26.9 mins
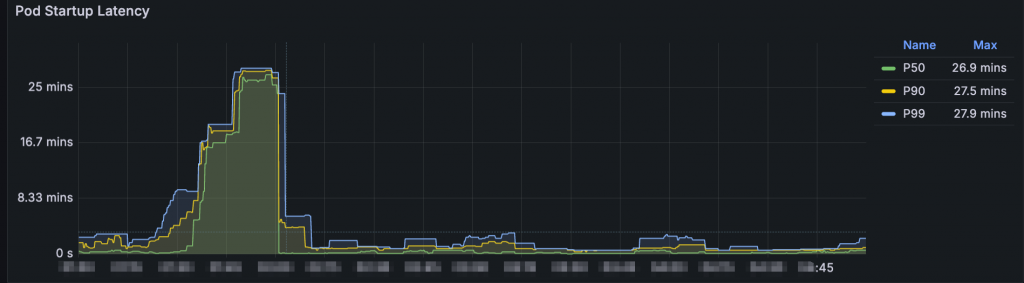
這對我們造成頗大的影響,如果今天有搶購活動,突然一個 traffic spike 衝進來我們系統,為了承擔這些流量自然會引起 Scale out,但是要等 Pod Ready 要很久 (例如:25 mins),結果流量已經消化的差不多了,搶購的東西也搶完了,於是流量掉下來,我們 Pod 這時候才 Running → Ready,結果就是:
所以為什麼 Pod 要等那麼久才 Ready?我們調查了 Karpenter、調查了 EC2,確定沒有問題,Node 起來的速度很快,隨叫隨到,速速 Ready
我們團隊其實調查很久,另外團隊還有觀察到:
Discovered new CiliumNode custom resource
Attached ENI to instance
•AssignPrivateIpAddresses`所以這邊疑問就變成:「為什麼 Karpenter 啟動一台機器後,要等那麼久才會創建 CiliumNode?為什麼創建 CiliumNode 之後,又要等那麼久 Cilium Operator 才幫我 Attach ENI?」
隨後我們有以下猜測:
排查過程其實比想像中漫長,但是可以確定以下事情
👉 Pod 從被建立起來一直到 Ready 的這段時間,其實都是被「等待 CiliumNode 被建立」和「 等待 Attach ENI」 佔用,只要 Attached ENI 並且該 ENI 被 Assign IP 後,Pod 很快就會 Ready
我們查了 Cilium 官方文件,但沒看到什麼實質有用的東西,所以我的排查方向變成去看 Cilium 原始碼,目標是想理解 IPAM AWS ENI 背後 Assign IP 的過程,於是便有了新發現!原來 Cilium 針對 EC2 API 有在內部實現 Rate limiter:
原始碼連結點我
// pkg/aws/ec2/ec2.go
// NewClient returns a new EC2 client
func NewClient(ec2Client *ec2.Client, ..., rateLimit float64, burst int) *Client {
// ... 略
return &Client{
ec2Client: ec2Client,
metricsAPI: metrics,
limiter: helpers.NewAPILimiter(metrics, rateLimit, burst), // 這裡有 APILimiter,就是實作速率控制的
subnetsFilters: subnetsFilters,
instancesFilters: instancesFilters,
eniTagSpecification: eniTagSpecification,
usePrimary: usePrimary,
}
}
隨後我便開始找這個 rateLimit 及 burst 具體值是怎麼被配置的?所以我去找看看在哪裡會去呼叫 NewClient
原始碼連結點我
// pkg/ipam/allocator/aws/aws.go
import (
ec2shim "github.com/cilium/cilium/pkg/aws/ec2"
)
// Init sets up ENI limits based on given options
func (a *AllocatorAWS) Init(ctx context.Context) error {
var aMetrics ec2shim.MetricsAPI
// 這裡傳了 Config.IPAMAPIQPSLimit 和 Config.IPAMAPIBurst
a.client = ec2shim.NewClient(ec2.NewFromConfig(cfg), operatorOption.Config.IPAMAPIQPSLimit, operatorOption.Config.IPAMAPIBurst, ...)
從上面的原始碼,便發現具體值是傳入:
operatorOption.Config.IPAMAPIQPSLimit
operatorOption.Config.IPAMAPIBurst
那這個 Config 在哪裡?從名稱就可以知道是 Cilium Operator 的 Config,具體原始碼如下:
原始碼連結點我
// /operator/option/config.go
// IPAMAPIBurst is the burst value allowed when accessing external IPAM APIs
IPAMAPIBurst = "limit-ipam-api-burst"
// IPAMAPIQPSLimit is the queries per second limit when accessing external IPAM APIs
IPAMAPIQPSLimit = "limit-ipam-api-qps"
注意到原始碼提供註解,就可以得知這兩個參數 IPAM API 的速率和 Burst
接著我再回去翻官方文件看要怎麼傳入對應的參數,以 helm 為例,我們可以這樣寫 values.yaml :
operator:
extraArgs:
- --limit-ipam-api-burst=50 # IPAMAPIBurst
- --limit-ipam-api-qps=10 # IPAMAPIQPSLimit
最後我也回去看一下 AttachNetworkInterface 的 function,確認他真的有實作 rateLimit:
// pkg/aws/ec2/ec2.go
// AttachNetworkInterface attaches a previously created ENI to an instance
func (c *Client) AttachNetworkInterface(ctx context.Context, index int32, instanceID, eniID string) (string, error) {
input := &ec2.AttachNetworkInterfaceInput{
DeviceIndex: aws.Int32(index),
InstanceId: aws.String(instanceID),
NetworkInterfaceId: aws.String(eniID),
}
c.limiter.Limit(ctx, AttachNetworkInterface) // 這裡進行 rate limiting
sinceStart := spanstat.Start()
output, err := c.ec2Client.AttachNetworkInterface(ctx, input)
c.metricsAPI.ObserveAPICall(AttachNetworkInterface, deriveStatus(err), sinceStart.Seconds())
if err != nil {
return "", err
}
return *output.AttachmentId, nil
}
從上方 c.limiter.Limit(ctx, AttachNetworkInterface) 就可以確定,真的有在內部實現 Rate Limiting
好,上面我講那麼多,讀者們可能會說:「你只是告訴我你發現 Cilium 內部有針對 AWS EC2 API call 做速率控制,你要怎麼證明真的被 Cilium 內部限流了?」
👉 可以觀察 cilium_operator_ec2_api_rate_limit_xxx 系列的 Metric 來查看是否被限流
以下是一個被限流的範例,只要彈起來就是被限流:
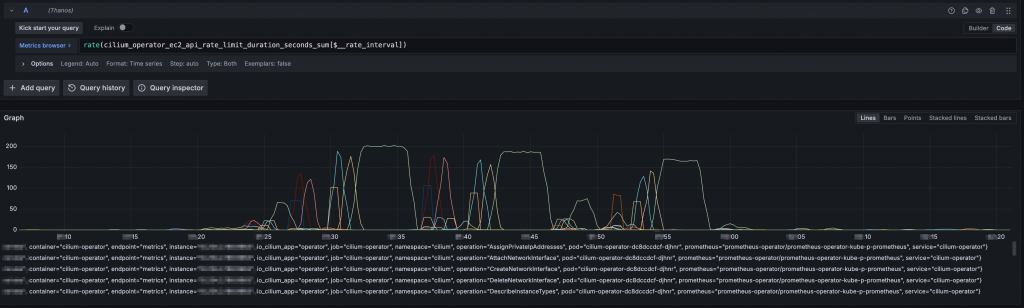
這也解釋了「為什麼我們去翻 AWS CloudTrail Logs 都翻不到 AWS API 被限流的紀錄,因為早在 Cilium 內部就已經先進行限流了」
而到這邊,我們已經可以說「Pod 等不到 IP 是因為 Cilium 內部限流,所以根本無法 Assign IP」
實際上 Pod 等不到 IP 是算是很後期的現象了,我講這句話你可能難以理解我這句話想表達什麼意思。
👉 簡單來說,直到現在我們只解釋了 Pod 被調度到某個節點上後等 IP 等很久是因為 Cilium 內部限流,但是還有其他 issue 發生在 Pod 被調度到節點之前
我持續追溯到源頭,其實還發現一個問題是「Cilium 過很久才 Ready」
為什麼我會發現?總有什麼事情發生才讓我有動機需要去查吧?
沒錯,動機是出自於我們有監控 Daemonset Unavailable percentage ,當高過某個閥值就會有 Alert 響,「只要有大量 Node 重新建立,這 Alert 都會響」
Daemonset Unavailable percentage 只代表 Cilium DamonSet 的 Unavailable percentage ,實際是監控了所有 DaemonSet,然後我們看到各種 DaemonSet 的 Unavailable percentage 都飆高如果 Cilium Pod 進不去 Ready 狀態會怎樣?
Cilium 一定要先 Ready 其他 Pod 才可以住上去,否則 Cilium 沒 Ready 誰來分配 IP 和配置 BPF Datapath?
所以 Karpenter 的部分,我們有配置 starup taint node.cilium.io/agent-not-ready,這就是 Taint 就是想避免 Node 剛啟動後 Cilium 還沒 Ready 而其他 Pod 就比 Cilium 早先住上來,需要等詳細內容請參考 Karpenter 官方文件
所以 starup taint 需要有人負責移除,在 Cilium 的世界裡,是 Cilium Operator 負責移除
Cilium Operator 要拔除 starup taints 會確保 Cilium Agent 已經 Ready 才會拔掉 startup taint,具體是這樣拔的:
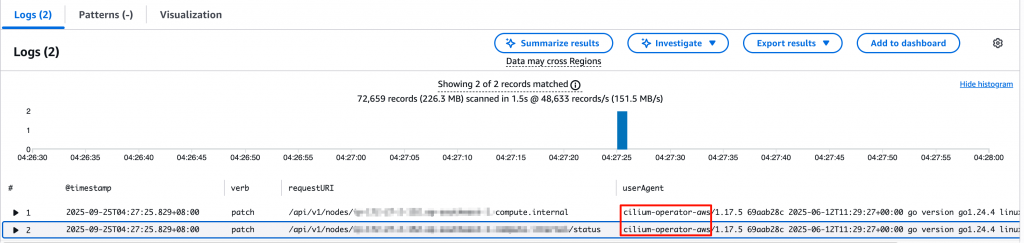
status.conditions 裡面其中一個欄位 NetworkUnavailable=false (如上圖)👉 所以 Cilium Pod 進不去 Ready 狀態,starup taint 就拔不掉,新的 Pod 就會沒有合適節點可調度
👉 等 startup taint 拔掉之後,Pod 被調度到節點,結果住上去還是要等,因為 Cilium 內部限流所以沒辦法跟 AWS 拿到 IP
以下展示一個簡單的範例,線長度可以代表該 Node 身上擁有 node.cilium.io/agent-not-ready taint 的時長:
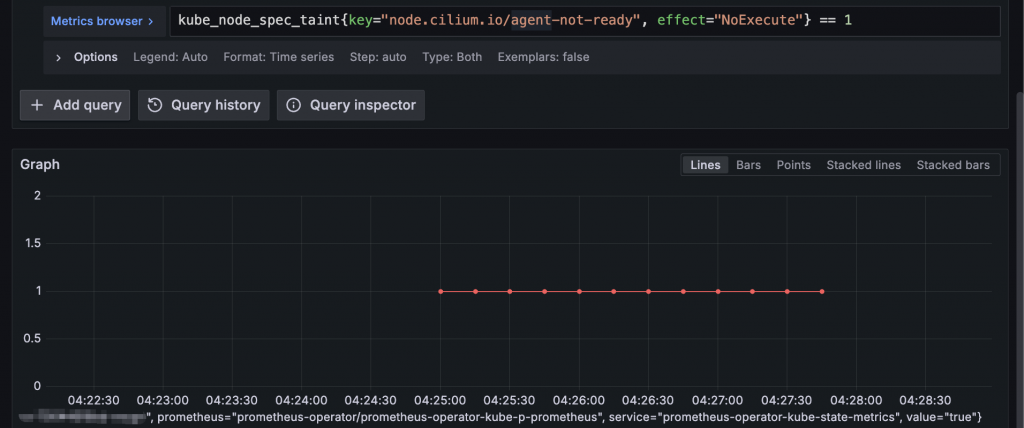
我們接著來調查 Cilium 為什麼過很久才 Ready,要回答這題,其實就是「K8s Readiness Probe 要過」,因為「Readiness Probe 是決定 Pod Ready 的關鍵」
Readness Probe 的運作邏輯大概是這樣:
readinessProbe 的設定開始定期檢查容器實際來看 Cilium Pod 的 redinessProbe 配置:
readinessProbe:
failureThreshold: 3
httpGet:
host: 127.0.0.1
httpHeaders:
- name: brief
value: "true"
path: /healthz
port: 9879
scheme: HTTP
periodSeconds: 30
successThreshold: 1
timeoutSeconds: 5
從上面設定可以知道:kubelet 每 30 秒對容器內的 127.0.0.1:9879/healthz 發 HTTP GET,
若連續 3 次(5 秒內無回應或非 2xx/3xx)失敗,就會標記 Pod 為 NotReady
成功一次就恢復 Ready
所以我們就要理解 Cilium 是如何處理 GET /healthz 請求,從原始碼就可以看到這端點會檢查非常多東西(可以連線進去 cilium agent 然後執行 cilium-dbg status 就可以知道有檢查哪些東西),於是我們發現 GET /healthz 背後的其中一個項目是會檢查 IPAM 狀態:
原始碼連結點我,注意這裡是 v1.17.5,在 v1.18+ 以下程式碼被移到 /pkg/status/status_collector.go
// daemon/cmd/status.go
{
Name: "ipam",
Probe: func(ctx context.Context) (interface{}, error) {
return d.DumpIPAM(), nil // 調用 IPAM.Dump()
},
OnStatusUpdate: func(status status.Status) {
d.statusCollectMutex.Lock()
defer d.statusCollectMutex.Unlock()
if status.Err == nil {
if s, ok := status.Data.(*models.IPAMStatus); ok {
d.statusResponse.Ipam = s // 更新到健康檢查 Response
}
}
},
},
讀者們可能會問說:「明明 GET /healthz 的背後會檢查很多東西,會什麼在眾多被檢查的東西裡面你只懷疑 IPAM?
👉 這是因為我們觀察到:「大量 Node 被建立後,前面幾個 Cilium Pod 都很快就 Ready,直到我們看見 cilium_operator_ec2_api_rate_limit_xxx 系列的 metric 彈起來,Cilium Pod 就會開始過很久才 Ready,這意味著 Cilium Agent 在啟動時,一定有什麼東西依賴著 AWS EC2 API,所以 AWS EC2 API 被限流後就會導致 Cilium 很久才 Ready」
我仔細看到 IPAM 裡面的邏輯,就有依賴到 EC2 API (相關程式碼連點點我,這裡不展開講解),所以會導致 IPAM status not Ready → 於是 Cilium Agent 也就跟著 Not Ready
解決方法如下,我分成兩個派系,你可以依照你的需求選擇你的派系:
--limit-ipam-api-burst 和 --limit-ipam-api-qps ,嘗試調高來避免 Cilium 內部限流,但也要盡可能不要撞到 AWS 那邊的限流改用其他 IPAM ,例如改用 Cluster Scope,以減少對 AWS API 的依賴,否則就一定會面臨 Rate limiting 的問題,事實上 Cilium 官方文件有提醒此事情

圖片取自:https://docs.cilium.io/en/stable/network/concepts/routing/#aws-eni
這次的問題表面上看起來是「Pod 起不來、卡在 Pending 等 IP」,但實際根因卻更深:
我們的 **Cilium Operator 在內部對 EC2 API 實作了 rate limit 機制,**這代表:
當大量 Node 被啟動、或在高流量事件中有大量 Pod 同時需要分配 IP 時,Cilium 的內部限流讓 ENI 建立與 IP 分配速度變很慢,進而導致:
我們從原始碼追蹤到具體的參數:
-limit-ipam-api-qps
-limit-ipam-api-burst
也透過 metrics (cilium_operator_ec2_api_rate_limit_*) 驗證確實有發生限流事件。
一句話總結:
👉 若系統需要很快的 Scale out 速度,請務必檢視 Cilium 的 IPAM 模式與 rate limit 設定,否則限流會成為你擴容速度的隱形天花板

 iThome鐵人賽
iThome鐵人賽