
昨天(Day 27)提到的案例是「DNS 封包原來都沒進去 NodeLocalDNS Cache?」
今天要來分享的實戰案例也是很有趣,是我在監控 per instance DNS Query 發現的!其症狀就是「有些 DNS Query 的流量沒被收進去 metric hubble_dns_queries_total、有些卻有」
神奇吧!今天就來揭曉是什麼小地方的配置將大大影響 metric hubble_dns_queries_total 會不會計入 DNS Query 流量
我們公司其實一直都有在導入 NetworkPolicy,期望越來越多 K8s Components 都能被套上 NetworPolicy,能夠基於最小權限原則只能碰他該碰的
DNS 這東西很重要,一爆就是出大事
如果發生某個 Pod 暴力的發 DNS Query,這個 Pod 便會形成這台 Node 的「惡鄰居」他會把 NodeLocalDNS 打爆,造成其他 Pod 如果要進行 DNS Query 可能也會失敗。
也因此,我便產生一個需求:「監控每台 Node 的 DNS Query per second」,如果某個 instance 的 DNS Query 量異常高,這絕對就要進去看!
結果我在某天因為想要知道 NodeLocalDNS Cache 的極限值在哪,才可以知道 Threshold 大概是多少,奇怪的事就發生了… 我超暴力的打 DNS 查詢封包,為什麼 hubble metric 沒有彈起來?
我以為 hubble 是不是壞掉了,可是我很確定「沒有壞掉」,因為某些 instance 的 DNS Query Total Metric 還是有正常收到。
於是便展開了調查:「我暴力打出去的 DNS Query 封包,為什麼沒讓 Metric 彈起來?難道是封包沒送進去 NodeLocalDNS Cache 嗎?還是有其他什麼奧秘?」
這中間我已經驗證了 NodeLocalDNS Cache 運作正常,所有 DNS Query 也確實都有打到 Node 上的 NodeLocalDNS Cache,我當下很匪夷所思到底發生什麼事了…
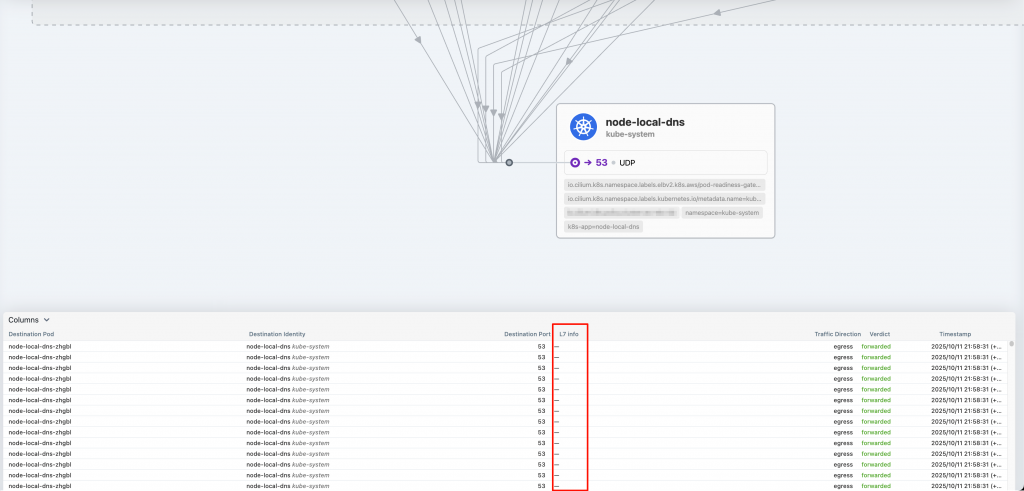
後來我在使用 Hubble UI 時,比較了那些有成功被收進去 Metric 和沒被收進去 Metric 的 Pod 時,就發現了一個神奇的事情!讀者們可以觀察一下下面兩張圖的 L7 Info 欄位
這是第一張,請注意紅框處:
這是第二張,請注意紅框處:
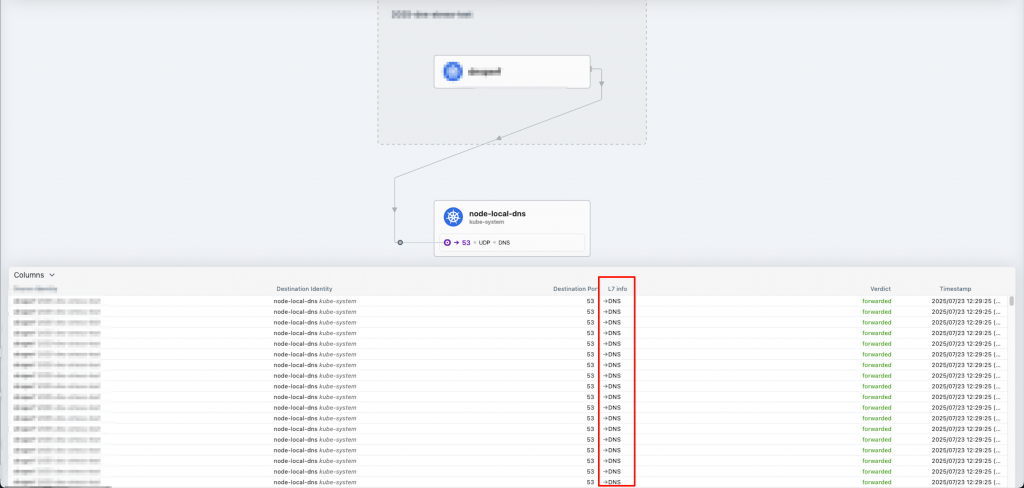
其中一個沒有任何 L7 Info,另一個則有 L7 Info DNS
除了透過 Hubble UI 之外,我們也可以連線進去 Cilium Agent 後,使用 hubble ovserve 去觀察:
hubble observe --protocol dns
hubble observe --protocol udp
此時我的疑問變成:「為什麼同樣打流量給 NodeLocalDNS,某些 Endpoint 的 flow 沒有 L7 info (也就是 --protocol udp )、有些卻有 L7 Info?」
後續我調查了 hubble metric 的原始碼,大概可以推測只要是 flow 沒有 L7 info DNS,就不會被收進去 hubble_dns_queries_total ,這也是為什麼「有些 DNS Query 的流量沒被收進去 metric hubble_dns_queries_total、有些卻有」
原始碼連結點我
// pkg/hubble/metrics/dns/handler.go
func (h *dnsHandler) ProcessFlow(ctx context.Context, flow *flowpb.Flow) error {
if flow.GetL7() == nil {
return nil
}
dns := flow.GetL7().GetDns()
if dns == nil {
return nil
}
總歸一句話
👉 flow 有 L7 info DNS 才會被收進去 hubble_dns_queries_total Metric
根據我們的推測是 flow 有 L7 info DNS 才會被收進去 hubble_dns_queries_total Metric
那我該怎麼讓 DNS Query 都帶有 L7 info? 關鍵是什麼?
👉 我嚴重懷疑是 CiliumNetworkPolicy 的配置影響了 flow 會不會擁有 L7 info!因為我發現有那些有 L7 info 的 flow,其 Endpoint 身上所套用的 Network Policy 都有 DNS 相關的配置
我們直接來看個範例 YAML,注意註解處,就是我所謂的「DNS 相關配置」:
# cnp-dnsperf.yaml
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
name: cnp-dnsperf
namespace: 2025-dns-stress-test
spec:
egress:
- toCIDRSet:
- cidr: 10.1.0.0/16
- toEndpoints:
- matchLabels:
app: api
k8s:io.kubernetes.pod.namespace: stable
- toEndpoints:
- matchLabels:
io.kubernetes.pod.namespace: kube-system
k8s-app: node-local-dns
toPorts:
- ports:
- port: "53"
protocol: UDP
rules:
dns: # 關鍵配置,影響 flow 會不會擁有 L7 info
- matchPattern: '*'
endpointSelector:
matchLabels:
app: dnsperf
現在,我就來驗證看看那個 rules.dns 真的會導致 flow 多了 L7 info,於是我把上面的 CiliumNetworkPolicy (CNP) apply 下去:
$ kubectl apply -f cnp-dnsperf.yaml
ciliumnetworkpolicy.cilium.io/cnp-dnsperf created
產生 DNS 查詢封包,接著去查看 Grafana
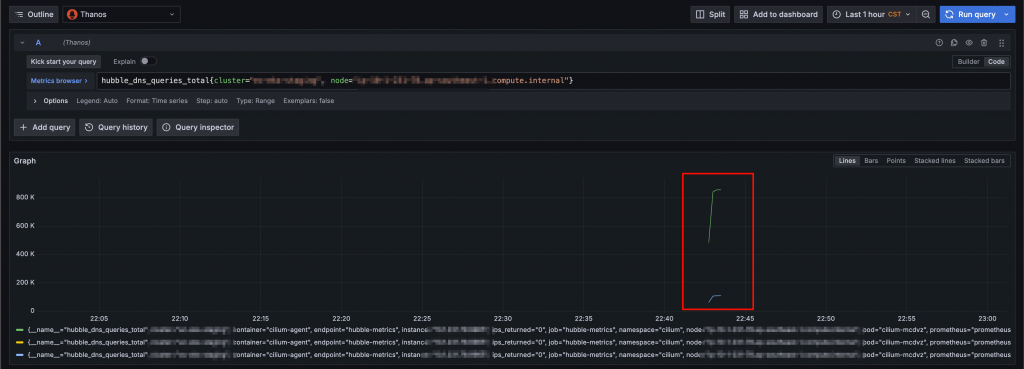
登愣!!!!!出現啦!!!hubble_dns_queries_total 終於把我這些 DNS Query 的流量收進去了
如上圖,我在 NetworkPolicy 加上了 rules.dns 的配置,真的讓成功收到 metric hubble_dns_queries_total
同時也去觀察 Hubble UI,也證實了真的有 L7 info
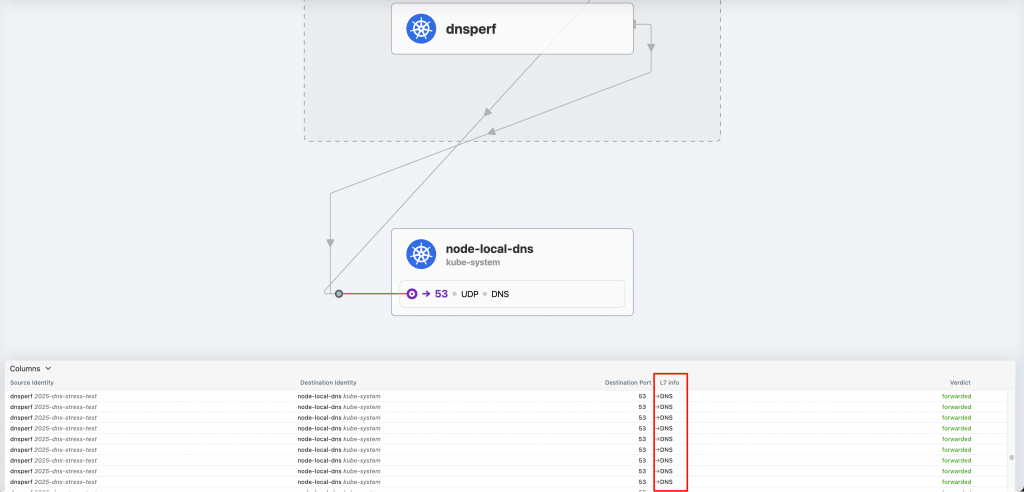
👉 所以我們這裡成功驗證了「CiliumNetworkPolicy 若有 DNS 相關配置,會讓 flow 擁有 L7 info DNS」
我們可以從 Cilium 原始碼看出一些端倪,來得知為什麼配置了 rule.dns 會導致 flow 擁有 L7 info:
原始碼連結點我
// pkg/policy/l4.go
// Determine L7ParserType from rules present. Earlier validation ensures rules
// for multiple protocols are not present here.
if rules != nil {
// we need this to redirect DNS UDP (or ANY, which is more useful)
if len(rules.DNS) > 0 {
l7Parser = ParserTypeDNS // 關鍵!只有這裡設定 DNS parser
} else if protocol == api.ProtoTCP { // Other than DNS only support TCP
switch {
case len(rules.HTTP) > 0:
l7Parser = ParserTypeHTTP
case len(rules.Kafka) > 0:
l7Parser = ParserTypeKafka
case rules.L7Proto != "":
l7Parser = (L7ParserType)(rules.L7Proto)
}
}
}
上方的原始碼,你可以觀察到有寫 rules.DNS 才會去做 L7 Parse,這就解釋我們在 NetworkPolicy 配置了 rules.dns 才能看到 L7 info DNS
回到我們最初的需求,我其實最初是想監控每台 Node 的 DNS QPS,結果在 DNS 壓測時意外發現 Metric hubble_dns_queries_total 怎麼沒彈起來?
照今天文章這樣分析,豈不是我所有 CiliumNetworkPolicy 都要加上 rule.dns ? 或是我要寫 CNP 裡面有配置 rule.dns 然後套到所有 Endpoint 身上,想想就覺得太可怕了這維護起來應該很累…
其次是我們注意到,只要配置了rule.dns 將帶來性能損耗:
👉 在 30,000 DNS QPS 的情境下若帶了 rule.dns 其 Queries lost rate 最高可高達 10.46%;相較之下我們沒有配置 rule.dns 其 Queries lost rate 僅 0.01%
背後原因當然可想而知,因為你多了 L7 info 又解析,勢必要送去 DNS Proxy,自然而然就帶來一點性能損耗,只是這些性能損耗是在很高的 DNS QPS 才會有顯著的影響,如果你的流量不高,我想性能損耗都是在可以接受範圍,具體來說還是要看讀者們自己的業務情境,並自己實際去測試看看,我這邊僅單純提供建議
關於 DNS Proxy 如果忘記是什麼,推薦讀者可以回去複習 [Day 18] Cilium Network Policy 為什麼能支援 DNS?DNS Proxy 是什麼?
好,我上面講了很多,看起來我是不會為了監控 DNS QPS 而去讓所有 CNP 都加上 rule.dns 、又或者為所有 Endpoint 都套上有 rule.dns 的 CNP。讀者們應該也會好奇我最終怎滿足自己的需求?
👉 我最終是直接去用 NodeLocalDNS Cache 的 metric coredns_dns_request_count_total 來監控每台 Node 的 DNS QPS
但是我不打算細談這裡的細節,因為這會超出本鐵人賽的範疇,其次是讀者們若跟我一樣有想要監控 DNS QPS 的需求也可以試試看使用 hubble_port_distribution_total{port="53"} 這個 metric
這次的實戰案例,其實揭露了一個很多人沒注意到的細節:
Cilium 的 L7 DNS Metrics hubble_dns_queries_total(還有其他 hubble_dns_xxx 等… 的 metric 原理都一樣)並不是「自動」收集的,而是取決於你的 NetworkPolicy 是否啟用了 DNS L7 Parser
以下是一些關鍵發現,整理如下:
hubble_dns_queries_total 只會統計有 L7 info 的 flow
若封包僅被視為 UDP 流量而沒有 L7 info,Hubble 不會記錄它
**有沒有 L7 info,取決於 CiliumNetworkPolicy 是否配置了 rules.dns ,**一旦你在 policy 中加入:
rules:
dns:
- matchPattern: "*"
Cilium 便會啟用 DNS L7 Parser,進而讓該 flow 產生 L7 info DNS,最終才會被計入 hubble_dns_queries_total
L7 Parser 帶來效能代價: 因為 DNS 需要經由 DNS Proxy 處理與解析,若 QPS 很高,會造成一定程度的封包遺失與延遲
👉 高流量情境下,建議不要為所有 Pod 套上 rules.dns
