前幾天我們拆解了卷積運算 Filter 如何擷取特徵。真正實戰時,還需要兩個關鍵輔助層來「整理」與「交接」:Max Pooling 負責資訊濃縮,Flatten 負責把特徵轉場到分類器。以下用精準圖解與數學觀念把兩者一次講清楚。
一、Max Pooling:資訊濃縮的藝術
降維 Dimensionality Reduction: 縮小特徵圖尺寸,大幅減少後續計算量與參數量,加速訓練。
提升平移不變性 Translation Invariance: 只保留區域內的最強訊號,對小幅度位移更有韌性。
非可學習層(無權重),但 梯度路由很關鍵:
前向被選為最大值的位置,獨享梯度;其他位置梯度為 0。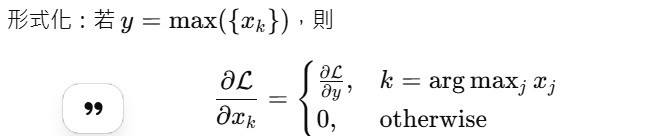
好處:把學習重點集中在最具辨識力的局部特徵上,提高有效學習密度。
二、Flatten:從特徵到決策的橋樑
卷積/池化輸出是 3D 張量:W×H×C(空間結構)。
全連接層 FC 需要 1D 向量(決策結構)。
Flatten 的任務:把最終特徵圖 攤平成向量,無縫銜接到分類頭。
*例:特徵圖 4×4×3⇒48 個數值 → 攤平成 48 維向量。
核心解答: Flatten 之前,卷積層已「萃取」與「壓縮」了空間關係與局部結構;若一開始就攤平,這些關鍵的鄰近關係會被打散,讓模型更難學到邊緣、紋理、形狀等特徵。因此在最後階段才 Flatten,將已被 CNN 整理好的特徵交給分類器做最終決策。
三、速查表:Max Pooling 與 Flatten
| 元件 | 作用主軸 | 對模型的直接影響 | 反向傳播特性 |
|---|---|---|---|
| Max Pooling | 降維 + 平移不變性 | 減計算量、抑制過擬合、保最強局部訊號 | 梯度僅回傳至「最大值」的位置 |
| Flatten | 結構轉場(3D → 1D 向量) | 將特徵輸入至全連接分類器 | 無權重、梯度僅做形狀展開傳遞 |

