# 如何呈現資料
在先前介紹資料處理的第一步時,有說到我們可以依據不同的需求,進行不同種類的學習模式,來取得我們所需的資訊。
為了能夠精準的表達不同學習模式的結果,我們有許多不同的方法來呈現資料,當我們知道資料該怎麼呈現,在做分析的時候就能夠推敲出分析結果該如何產生,其中在日常生活中比較常見的有決策樹(decision tree)及表格(table),而在機器學習中許多學習方法也使用分類規則(classification rule)的方式來呈現結果。
另外針對跟數量相關的資料(numeric)或者二元分類問題(binary)則可以用線性模型來描述(linear models)。
還有一種比較特殊的,是針對資料(instance)本身而不是資料隱含的規則的呈現方法,稱為 instance-based representation。
未來的幾篇會針對不同的資料呈現方式來做介紹。
最簡單、原始且非常容易理解的呈現方法。我想他要怎麼用應該不用多作說明了吧...
用表格呈現結果時會遇到的最大問題就是該選擇什麼屬性放到表格中,有些屬性如果跟呈現的目的沒有關係時就可以不用放進去。
(#1)
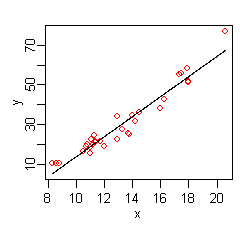
Linear Models 是另一種簡單的呈現方法,主要處理數量(numeric)資料,透過指定 weight 到不同的屬性,最後計算出一個現模型來表達特定變數與我們感興趣的變數之間的關係。
除了針對數量資料的預測外,linear models 還可以使用在二元性(binary)的分類問題上,被稱為 decision boundary。
至於怎麼計算出那條線,以後再說吧...
#1. "Friedmans mars linear model" by Stephen Milborrow - Generated by the author from the "trees" dataset using the "earth" library in the R statistical package. Licensed under Public domain via Wikimedia Commons - http://commons.wikimedia.org/wiki/File:Friedmans_mars_linear_model.png#mediaviewer/File:Friedmans_mars_linear_model.png
[回歸分析](http://zh.wikipedia.org/wiki/%E8%BF%B4%E6%AD%B8%E5%88%86%E6%9E%90)
[decision boundary](http://en.wikipedia.org/wiki/Decision_boundary)


{kind=link}