# Trees
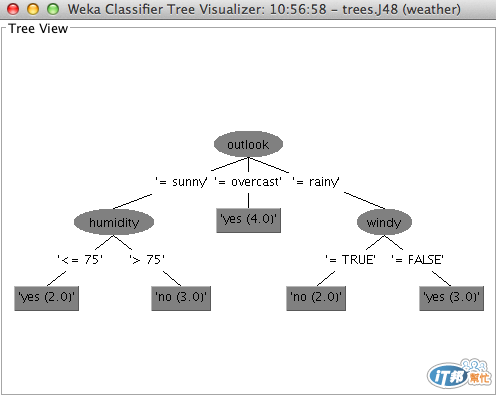
這就是 tree,又稱為 decision tree。
樹幫助我們根據資料的屬性,來表達分類或者決策的結果,樹可以由上到下,很清晰地表達一個分類如何被達成。
Tree 中的每一個節點 node(上圖橢圓形),代表著不同的屬性測試,而最下方的葉 leaf(上圖矩形),則代表分類的結果。
除了容易理解之外,決策樹還有以下優點:
容易產生,不用對資料做太多的前處理就能製作
能夠同時處理 nominal 及 numeric 的資料
然而樹的產生很容易被偏頗的資料所影響(例如某個屬性的資料特別多)。
樹的產生可以透過一個叫做 information entropy 的方法來決定,這個部分在之後的文章會提到。
Rules 被廣為使用來作為 tree 的一種替代方案。主要有兩種 rules,一個是 classification rules,另一個是 association rules。
Rules 長得像這樣,其實就是一段敘述:
If a and b then X
Classification rules 可以很容易地從一個 decision tree 中找出,由上到下,依照樹的 node test 就可以歸納出 rules,而 rules 的結果就是樹的 leaf。雖然 rules 可以作為 decision tree 的一個替代方案,然而直接從 decision tree 中取出的 rules 往往都太過複雜,需要一些修改才能做應用。
Association rules 其實跟 classification rules 沒什麼差別,除了他們的結果,classification rules 推出的結果是資料的分類,而 association rules 推出的結果可以是任何的屬性(文字遊戲嗎...),也因為這樣,association rules 的數量遠遠多於 classification rules。
Rules 的 coverage(又被稱為 support) 指的是 rules 判斷正確的資料數量,而 accuracy (又稱為 confidence) 指的是正確的比例。
在使用 rules 表達分析結果的時候,通常會設定一個最低的 coverage 及 accuracy ,過濾掉一些參考性低的 rules。
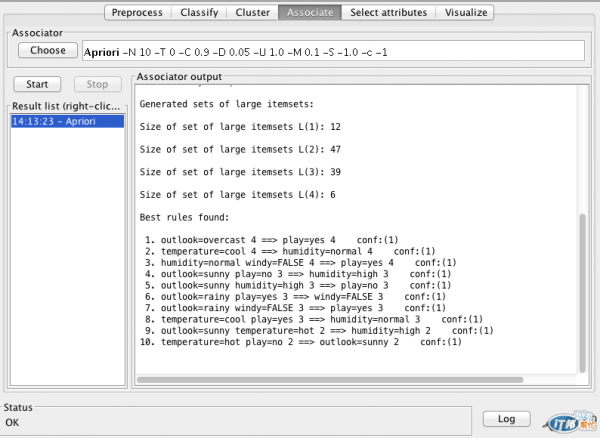
上圖是用 Weka 來產生 rules 的範例。
[1] http://en.wikipedia.org/wiki/Decision_tree
[2] http://faculty.stust.edu.tw/~jehuang/DMCourse/ch5-6.html
[3] http://en.wikipedia.org/wiki/Classification_rule
[4] http://en.wikipedia.org/wiki/Association_rule_learning

