
# 單純的呈現方式:Instance-based Representation
Instance-based representation 其實滿原始的,這個方式說穿了只是單純的「記憶」,把機器要學習的資料都存起來,如果遇到新的資料時,就比對新資料和舊資料的相似程度,來決定新資料屬於什麼分類。為什麼說原始呢,因為這個做法也滿接近人類的直觀思考的,只是去比比看兩個東西有沒有一樣或類似,而不是去找出他背後隱含的規則。
事實上 instance-based learning 在實作的時候,真正工作的時間都是花在比較新資料和現有的資料上面,這是跟其他學習法不太一樣的地方 XD
要比較兩個資料的相似度,這邊的做法是去比較他們的 distance,找到彼此之間距離最短的就是了,稱為 nearest-neighbor classification method。而還有一種跟這個方法很像的是,比較新資料落點附近的資料,拿它附近最多且最接近的 k 個資料作為分類的依據,稱為 k-nearest-neighbor classification。
那麼,要怎麼樣計算 "distance" 呢?
如果給你 sunny, overcast, rainy 這樣的屬性值,他們之間的距離究竟要怎麼算?
最簡單的方法是比較相等不相等,如果相等,距離=0,不相等,距離=1。
當然這個方法是很粗糙的,如果想要更精確地計算 distance ,就得研究看看有沒有辦法把這些 nominal 的資料轉換成 numeric 的。
另外屬性通常都會有比較重要、比較相關的,這時我們可以透過 weight 權重的方式來調整不同屬性的重要性。
如果今天有一百萬個 instances ,全部都存到系統中除了會浪費很多空間,加上 instance-based learning 的做法是去一一比較資料之間的距離,如果資料量太多會造成執行的效率低落,因此使用 instance-based representation 時要去考慮哪些資料要存,哪些資料不用存。
在規劃要丟掉哪些資料時,一個很重要的概念是,留下來的資料要能夠清楚(explicitly)分割不同 class 的 instances 之間的界線。
一個比較好懂的方法(我覺得啦)是用矩形來劃分,可以稱為 rectangular generalization,見下圖:
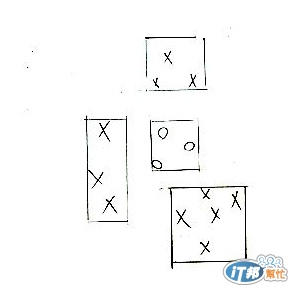
如果說新的資料落在矩形內,資料就屬於那個類別,如果落在任何矩形的外面,也可以用上面說的 nearest-neighbor method ,透過計算距離來決定新資料屬於什麼類別。
最後還有一個很重要的,雖然說 instance-based representation 可以應用在 nominal 的資料,但其實像 rectangular generalization 這樣的方法還是比較適合用在 numeric 資料上的。
就跟他的名字一樣,clusters 其實就是資料群,把相同或相似的資料給圈成一個叢集。
叢集有很多種形式,一種是單純的把資料分群,把相同叢集的資料標上相同的記號。
某些算法會讓一個資料能夠同時屬於多個 clusters ,這時便可以用文氏圖(Venn diagram)來呈現該叢集結果。
另外有一種有階層概念的叢集,在上方的叢集可以分割成小的叢集。
[1] http://www.tutorialspoint.com/data_mining/dm_cluster_analysis.htm
