接續昨天的文章...
因為網站的防爬蟲機制,一般都是在requests的階段會碰到問題,所以就在這部分講一講,比較常遇到的一些問題,以及他的解決方案。
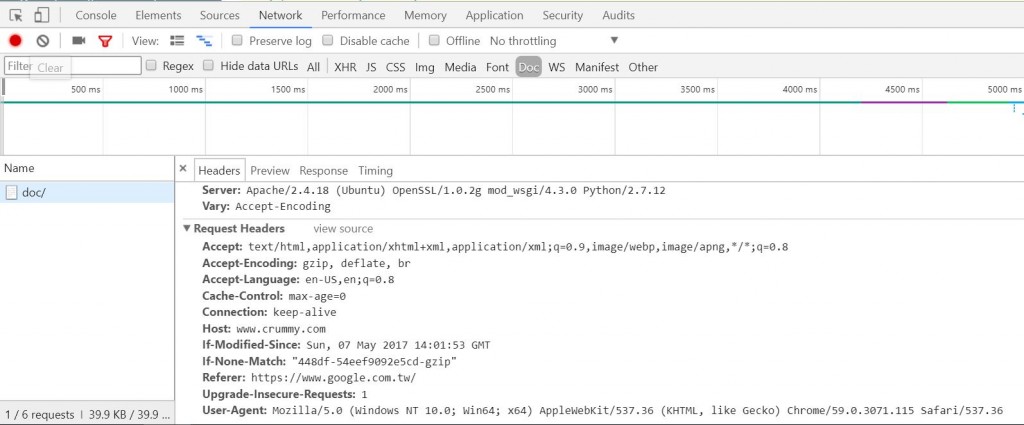
這個header可以透過F12>Network>目標頁面>Requests Headers找到,這個東西如果你是用python的requests套件,伺服器端偵測到的可能就是Python用戶端送出的requests,有些防爬蟲比較高階的網站會檔下這類型的requests,因此如果有遇到這類問題,可以這樣處理。
import requests
## 這是一個很有名的,爬蟲愛好者常去挑戰的一個募資網站
url = "https://www.indiegogo.com/projects/viviva-colorsheets-the-most-portable-watercolors-painting-travel--4#/"
## 使用假header
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'}
re = requests.get(url, headers=headers)
re.encoding = 'utf8'
print(re.text)
如果各位不相信,可以把假header拿掉試試看,然後在回傳的值當中,尋找這個網頁最重要的元素(ctrl+F)$259,123,照理說你透過python得到的網頁,跟直接透過瀏覽器接點進去的就不是同一網頁了,應該會是她特別寫給爬蟲愛好者取得的一個網頁,你也就找不到這個數字了。
import requests
url = "https://www.indiegogo.com/projects/viviva-colorsheets-the-most-portable-watercolors-painting-travel--4#/"
re = requests.get(url)
re.encoding = 'utf8'
print(re.text)
由於大量爬取同一個網域的網站,剛開始我們都會直接透過迴圈處理,但是迴圈一般都會以比你想像中快十倍甚至百倍的速度運行,也就是說,一秒內你可能發超過10個requests給那個網站的伺服器。而恰巧不巧,早期攻擊一個網站最常使用的方式就是大量送出封包癱瘓伺服器,但是現在這部分的攻擊基本上都已經沒有效果,每一種語言的網站架構基本上都會有預設防禦這種類型的攻擊,就算開發人員沒有特別注意,也會預設擋下這類型的requests。所以建議你,如果要大量發出請求,可以使用time這個套件。
import requests
import time
url = "http://cid.acad.ncku.edu.tw/files/14-1056-54086,r677-1.php?Lang=zh-tw"
contextLi = []
i=0
while i < 10:
re = requests.get(url)
re.encoding = 'utf8'
contextLi.append(re.text)
i += 1
print(i , " succeed")
time.sleep(2)
print("this is the first requests----------------------------------\n", contextLi[0])
print("this is the last requests----------------------------------\n",contextLi[-1])
重複向特定網站的伺服器送出過多requests時,網站可能會直接鎖定你現在所使用的IP位置,這個時候也只能想辦法換IP拉,有幾種換IP的方式,因為你的手機一般都是浮動IP,所以如果流量夠的話,可以重新連線一次,一般wifi也是同樣的原理。不過有時候,這樣做如果間隔時間太短,系統還是會使用同一組IP。
這邊介紹一個小工具給大家,原本是我去大陸時,翻牆回來的工具,後來發現爬蟲上使用更是便利,而且如股純粹是爬蟲用途的話,你可以不必使用付費的版本。就是hotspotshield,當然大家如果有習慣使用的VPN工具,那也是可以啦,這個工具的使用上,一但你發現你的IP被封鎖了,直接重新連線hotspotshield,它就會幫你換到其他國家的IP了。
順帶一提發現IP被檔的辦法,我很習慣性的會先把抓下來的html文件存成一個個的純文字檔,在程式在跑的過程中,你可以打開檔案總管到你儲存純文字檔的資料夾中,監視檔案的大小,一旦發現檔案的大小都維持在同一個且很低的水平的時候,大約就代表你被封鎖IP了。當然你也可以透過python去偵測純文字檔儲存下來的大小,如果規模夠大的話,還是很有效益的。
由於現在網頁技術越來越先進,往往很多網頁的內容,並不需要透過獨立的網址才能呈現,在同一個網址下,透過javascript就可以讓html元素做很多變換,在配上ajax甚至可以跟資料庫互動。因此,若你要取得這些,進入網頁與使用者互動之後才會得出的html元素,純粹的requests就無法滿足你的需求了。
也因應這個網頁設計越趨複雜的趨勢,現在網頁測試的領域也越來越興盛,因此selenium這一個網頁自動化測試工具也就誕生了。它實作了非常多的介面,當然其中也包含python。從爬蟲的領域來看,這個東西就是個神器救星,因為所謂網頁測試,也就是要模仿真人操作網頁的行為進行測試網頁是否有bug,
換而言之,真人透過與網頁互動用javascript產生的html元素這時也可以輕易取得了。另一方面,由於不太可能有網站可以區分自動化工具跟真人,一旦它擋下你的自動化測試工具,它擋到真的人的機會也會很高,會很不利它網站的運作。總體而言,這還是一個滿方便的爬蟲工具。
這邊簡單說明一下selenium使用的過程中要注意的問題:
from selenium import webdriver
import time
driver = webdriver.Chrome() # 如果你沒有把webdriver放在同一個資料夾中,必須指定位置給他
driver.get("https://timetable.nctu.edu.tw/")
def tryclick(driver, selector, count=0): ##保護機制,以防無法定味道還沒渲染出來的元素
try:
elem = driver.find_element_by_css_selector(selector)
# elem = driver.find_element_by_xpath(Xpath) # 如果你想透過Xpath定位元素
elem.click() # 點擊定位到的元素
except:
time.sleep(2)
count+=1
if(count <2):
tryclick(driver, selector,count)
else:
print("cannot locate element" + selector)
tryclick(driver, "#flang > option:nth-child(2)") # 設定成中文
tryclick(driver, "#crstime_search") # 點擊「檢索」按鍵
time.sleep(3) # 等待javascript渲染出來,當然這個部分還有更進階的作法,關鍵字是implicit wait, explicit wait,有興趣可以自己去找
html = driver.page_source # 取得html文字
driver.close() # 關掉Driver打開的瀏覽器
print(html)


