這個專案是我去新竹黑客松比賽時,拿到第二名的作品,這個作品主要是將新竹市政府社會處的常見問答集爬下來,希望可以建置一個聊天機器人幫助市民快速取得問題的答案。
這個作品主要分成四個部分:
其他比較精彩的介紹可以參考我的gitub
# 基礎
import pandas as pd
import numpy as np
import math
import json
import os
import jieba ## 斷字
jieba.set_dictionary('dict.txt.big')
stopwords = [ line.rstrip() for line in open('stop_words.txt' , encoding='utf8') ] ## 這個中文停用字典可以自己找
# 視覺化
import matplotlib.pyplot as plt ## python最常見的繪圖工具
import matplotlib
zhfont1 = matplotlib.font_manager.FontProperties(fname='simsun.ttf') ## plt中文字
from mpl_toolkits.mplot3d import Axes3D
from sklearn.decomposition import PCA ## 降維視覺化常用工具
from pylab import rcParams ## 調整畫布比例
# 訓練模型
from sklearn.model_selection import train_test_split ## 切分鍊與測試資料集
from sklearn.neighbors import KNeighborsClassifier ## KNN
from sklearn.svm import SVC ## SVM
from xgboost import XGBClassifier ## xgboost
import xgboost
# 從新竹社會局常見問答集爬取
def getdata():
with open('RawData.json', 'r', encoding='utf8') as f:
data = json.load(f)
df = pd.DataFrame(data)
return df
這是預先爬下的資料,爬蟲我們就先省略了,大家記得要先去github clone資料下來。
df_train = getdata()
print("Rows=", len(df_train))
df_train.head()
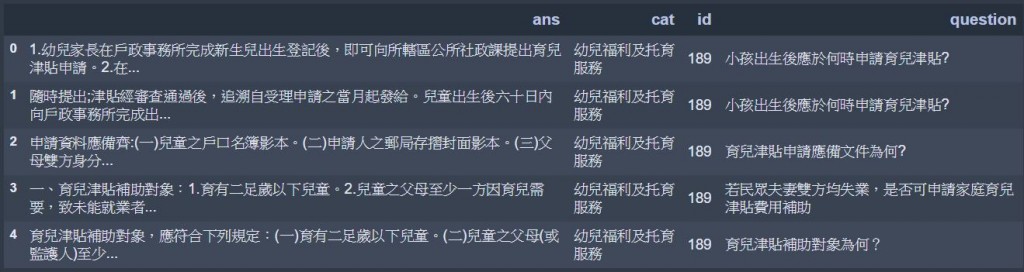
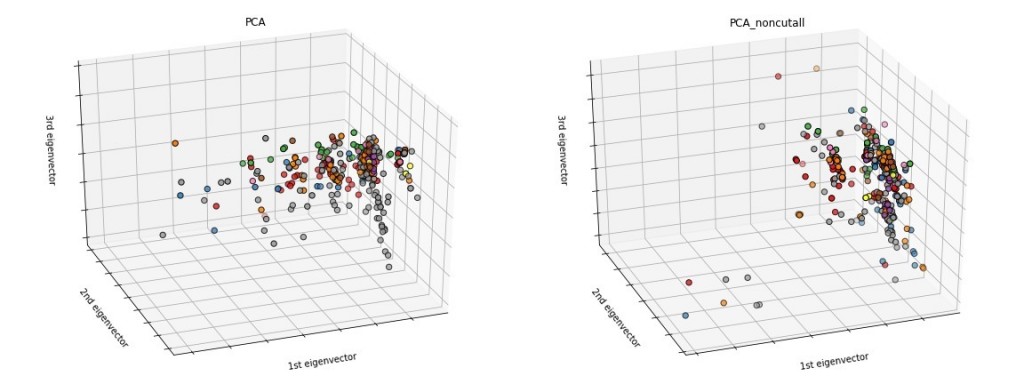
這個地方斷字模式的選擇非常重要,因為中文斷字採用精準模式可以方便人們閱讀,但是如果要讓機器去認識相關性,最好可以讓句子當中所有可能的資訊都被包含進去,而採用全斷詞模式可以得到所有的斷字可能,如此一來,便能增加斷詞後句子的資訊含量。這部分之所以會檢查出來之後,下面的PCA圖(比較下面)也可以明顯看出,每個句字的資訊含量增多了之後,有平滑資料的功能。
# 斷字
def preprocess(question):
# words = list(jieba.cut(question)) ## 精準模式
words = list(jieba.cut(question, cut_all=True)) ## 全斷詞模式
return words
df_train['words'] = df_train['question'].apply(preprocess)
df_train.head()
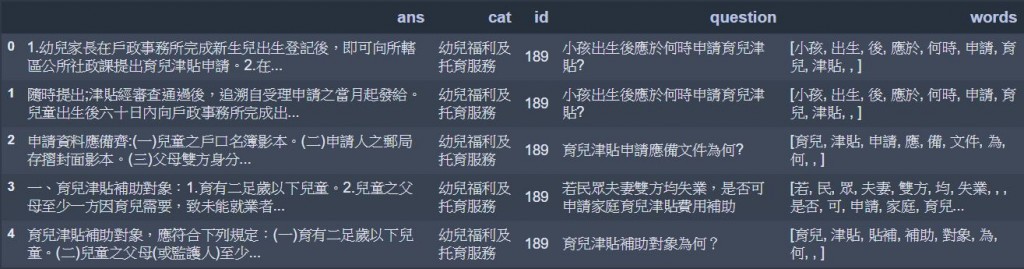
# 為了訓練需要,將類別轉化為數字類別(1~11類)
cat_mapping = {}
for num, cat in enumerate(list(set(df_train['cat']))):
cat_mapping[cat] = num
# 預測時,要將預測出的結果翻譯為原先的類別所使用
inversed_cat_mapping = {}
for cat, idx in cat_mapping.items():
inversed_cat_mapping[idx] = cat
print(cat_mapping)
print(inversed_cat_mapping)
# {'國民年金': 1, '社區發展服務': 2, '社工專業服務': 11, '兒童少年及家庭福利': 3, '身心障礙者福利': 4, '家庭暴力及性侵害防治服務': 8, '婦女福利': 6, '幼兒福利及托育服務': 7, '人民團體及合作社場服務': 9, '社會救助': 5, '老人福利': 10, '志願服務': 0}
# {0: '志願服務', 1: '國民年金', 2: '社區發展服務', 3: '兒童少年及家庭福利', 4: '身心障礙者福利', 5: '社會救助', 6: '婦女福利', 7: '幼兒福利及托育服務', 8: '家庭暴力及性侵害防治服務', 9: '人民團體及合作社場服務', 10: '老人福利', 11: '社工專業服務'}
我後來在測試預測能力時,發現如果使用者只透過幾個簡單的字詢問,將有可能導致預測失準,因為從社會處爬下來的每個問題都是完整的問句,因此增加這樣的資料,將有助於使用者使用簡短的特定議題標題,作為詢問問題。
print('Preprocess Length = ', len(df_train))
addedrow = []
for key, value in cat_mapping.items():
row = {}
words = list(jieba.cut(key, cut_all=False))
row['words'] = words
row = {'ans': None,
'cat': key,
'cat_num': value,
'id': None,
'question': key,
'words':words
}
addedrow.append(row)
addeddf = pd.DataFrame(addedrow)
df_train = pd.concat([df_train, addeddf])
print('Processed Length = ', len(df_train))
# Preprocess Length = 327
# Processed Length = 339
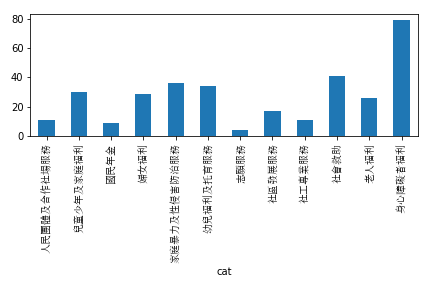
這個部分很重要,因為訓練出來的類別分配比例,與訓練資料集內部的類別分配比例會相同,因此如果未來使用者詢問的問題的比例與這個比例不同,將很有可能導致預測的失準,因此這部分要特別注意。如果知道真實的使用者詢問比例,可以複製特定比例的資料以平衡比例。
main_series = df_train.groupby('cat').count()['ans']
main_series.plot(kind='bar', use_index=False)
plt.savefig(os.path.join('pic', 'nums_of_queries_each_cat'))
plt.show()
for i in range(len(list(main_series.index))):
label = 'ABCDEFGHIJKLMNOPQRSTU'
print(label[i], main_series.index[i], list(main_series)[i])
df_train['question'].apply(len).plot(kind='hist', bins=30)
plt.savefig(os.path.join('pic', 'length_of_queries'))
plt.show()
這個步驟可以看出,每個類別比較常用的一些字,如果可以很明顯區辨,那麼訓練起來也就會比較容易,我剛開始拿到這個資料集準備要訓練時,看到這麼鮮明的類別詞彙,我就有滿高的把握,可以訓練起來的。
# 每個類別常出現的字
from wordcloud import WordCloud
from collections import Counter
freqs = []
for cat in list(set(df_train['cat'])):
words_Li = list(df_train[df_train['cat'] == cat]['words'])
total_words_in_cat = []
for words in words_Li:
total_words_in_cat.extend(words)
freq = Counter(total_words_in_cat)
print(cat)
wordcloud = WordCloud(font_path="simsun.ttf")
wordcloud.generate_from_frequencies(frequencies=freq)
plt.figure()
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.title(cat, fontproperties=zhfont1)
plt.savefig(os.path.join('pic', 'wordcloud_' + cat), bbox_inches='tight', pad_inches=0)
plt.show()

這個步驟首先要先建立一個一致的詞彙索引list,如此將可以讓每一個問題,在同樣的向量下,增加出現的字所在的索引值的維度的值,以向量化所有問題。
# 準備排序的文字list(keywordindex)
total_li = []
for li in list(df_train['words']):
total_li += li
vectorterms = list(set(total_li))
## 轉化每個問題變成向量
def vectorize(words):
self_main_list = [0] * len(vectorterms)
for term in words:
if term in vectorterms: ## 測試資料集當中的字不一訂有出現在訓練資料集中
idx = vectorterms.index(term)
self_main_list[idx] += 1
return np.array(self_main_list)
X = np.concatenate(df_train['words'].apply(vectorize).values).reshape(-1, len(vectorterms))
Y = df_train['cat'].apply(cat_mapping.get)
print(X.shape)
print(Y.shape)
# (339, 1017)
# (339,)
這個步驟很重要,我原本在jeiba斷字的階段,開的是精準模式,而不是全斷字模式,那麼會得到右邊的結果,而這樣資料的極端分布,將會導致不好的訓練效果,因此這個步驟還是很必要的。一旦發現資料的分佈有問題,可能要平滑處理一下特定的欄位,或是思考一下其他處理方式。
fig = plt.figure(1, figsize=(8, 6))
ax = Axes3D(fig, elev=-150, azim=110)
X_reduced = PCA(n_components=3).fit_transform(X)
ax.scatter(X_reduced[:, 0], X_reduced[:, 1], X_reduced[:, 2], c=Y,
cmap=plt.cm.Set1, edgecolor='k', s=40)
ax.set_title("PCA_cutall")
ax.set_xlabel("1st eigenvector")
ax.w_xaxis.set_ticklabels([])
ax.set_ylabel("2nd eigenvector")
ax.w_yaxis.set_ticklabels([])
ax.set_zlabel("3rd eigenvector")
ax.w_zaxis.set_ticklabels([])
plt.savefig(os.path.join('pic', 'PCA_cutall'))
plt.show()
為了避免overfitting,因此最好只拿一部分資料進去訓練模型,另一部分拿來驗證模型。
# Finally, we split some of the data off for validation
X_train, X_valid, Y_train, Y_valid = train_test_split(X, Y, test_size=0.2, random_state=123)
print(X_train.shape)
print(X_valid.shape)
print(Y_train.shape)
print(Y_valid.shape)
先用幾個簡單的分類模型試試,其中你會發現,KNN在這種文字次數累積的稀疏矩陣(有很多零的向量)效果其實已經還不錯;在SVM上因為rbf的函數無法有效解釋這些類別的差異,linear的效果則特別好;另外XGB上的效果也不錯,主要原因是XGB是非常暴力的工具,某種曾度上撇除了參數調整的因素,不管怎麼用效果都特別好。不過因為訓練資料量其實不大,因此有可能各位執行的時候,結果跟我並不太一樣。
# 定義函式,輸入分類器,輸出準確率
def get_accuracy(clf, *args):
if args:
clf = clf(kernel=args[0]) ## SVM在這邊用Llinear比較準
else:
clf = clf()
clf = clf.fit(X_train, Y_train)
y_pred = clf.predict(X_valid)
return (str(sum(Y_valid == y_pred)/Y_valid.shape[0]))
print('KNN: ', get_accuracy(KNeighborsClassifier))
print('SVM_rbf: ', get_accuracy(SVC))
print('SVM_linear: ', get_accuracy(SVC, 'linear'))
print('XGB: ', get_accuracy(XGBClassifier))
# KNN: 0.602941176471
# SVM_rbf: 0.220588235294
# SVM_linear: 0.838235294118
# XGB: 0.897058823529
最後,我最喜歡使用的分類王者XGB+CV,由於可以自動開啟訓練的過程,使用上整個非常方便,也得到了最好的效果。
params = {}
params['objective'] = 'multi:softmax' ## 因為是多個類別,這邊跟前面兩個類別的使用不太一樣
params['eta'] = 0.1
params['max_depth'] = 3
params['silent'] = 1
params['nthread'] = 4
params['num_class'] = len(set(Y)) ## 多個類別,記得要告訴她有幾個類別
d_train = xgboost.DMatrix(X_train, label=Y_train)
d_valid = xgboost.DMatrix(X_valid, label=Y_valid)
watchlist = [(d_train, 'train'), (d_valid, 'valid')]
bst = xgboost.train(params, d_train, 1000, watchlist, early_stopping_rounds=100, verbose_eval=10)
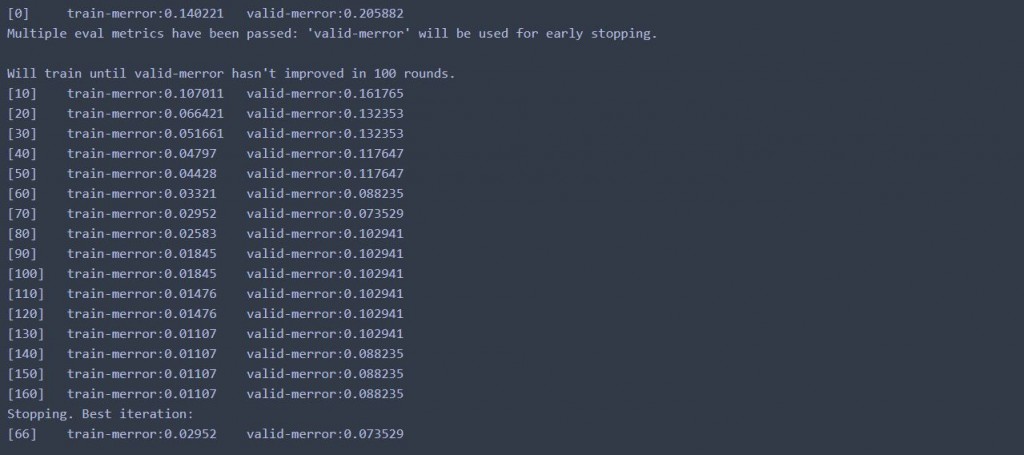
從結果上來看,測試資料可以達到91%的準確率,整個資料集來看,可以達到97%的準確率,效果還不錯。
y_pred = bst.predict(xgboost.DMatrix(X_valid))
print("Accuracy_valid: ", str(sum(Y_valid == y_pred)/Y_valid.shape[0]))
y_pred = bst.predict(xgboost.DMatrix(X))
print("Accuracy_all: ", str(sum(Y == y_pred)/Y.shape[0]))
# Accuracy_valid: 0.911764705882
# Accuracy_all: 0.976401179941
這邊其實也可以看一下,他的樹狀圖是怎麼畫的,不過沒什麼特別的意義就是了。喔對了,要使用這功能要先安裝graphviz,要下載有點久,大家斟酌使用。
rcParams['figure.figsize'] = 10, 20
xgboost.plot_tree(bst, num_trees=2)
plt.savefig(os.path.join('pic', 'tree'))
plt.show()
為了讓預測可以被檢驗,我們爬下台北市政府社會處的常見問答集來做測試。
# This is crawled from 台北社會局常見問答集
with open('Taipei_Society_Affiar_QA', 'r', encoding='utf8') as f:
testing_questions = eval(f.read())
testing_questions = np.random.choice(testing_questions, size=len(testing_questions))
df_test = pd.DataFrame(testing_questions, columns=['question'])
df_test.head()
def predict(question): ## 定義預測函數
words = preprocess(question)
vector = vectorize(words)
cat_num = bst.predict(xgboost.DMatrix(vector.reshape(1, -1)))
return inversed_cat_mapping.get(cat_num[0])
df_test['cat_pred'] = df_test['question'].apply(predict)
df_test[['question', 'cat_pred']]
| id | question | cat_pred |
|---|---|---|
| 0 | 我最近看到臺北扶老.軟硬兼施廣告,請問那是什麼服務?怎樣的對象可以申請? | 身心障礙者福利 |
| 1 | 請問二代健保上路後會影響我的老人健保自付額補助資格嗎? | 老人福利 |
| 2 | 敬老、愛心悠遊卡可以借人使用嗎? | 婦女福利 |
| 3 | 從哪裡可以得到老人福利服務資訊? | 老人福利 |
| 4 | 敬老、愛心及愛心陪伴悠遊卡,故障應備何文件重新辦理? | 老人福利 |
| 5 | 身心障礙者專用停車位識別證新制申請應備文件。 | 身心障礙者福利 |
| 6 | 「馬上關懷急難救助」經申請(或通報)後,何時可獲得協助? | 社會救助 |
| 7 | 長者預防走失手鍊是否有GPS功能? | 身心障礙者福利 |
| 8 | 「馬上關懷急難救助」向居住所在地或戶籍所在地申請? | 社會救助 |
| 9 | 申請失能者生活輔助器具及居家無障礙環境改善補助應備文件為何? | 身心障礙者福利 |
| 10 | 敬老、愛心及愛心陪伴悠遊卡,故障應備何文件重新辦理? | 老人福利 |
| 11 | 我是離婚單親,與前配偶共同監護1名4歲小孩,可否申請特殊境遇家庭扶助? | 婦女福利 |
| 12 | 「行動不便身心障礙者」判定、評估結果及異議處理方式為何? | 身心障礙者福利 |
| 13 | 辦理身心障礙者承租停車位租金補助的車輛種類? | 身心障礙者福利 |
| 14 | 101年7月11日起身心障礙者專用停車位識別證新制上路!請說明新制的轉變。 | 身心障礙者福利 |
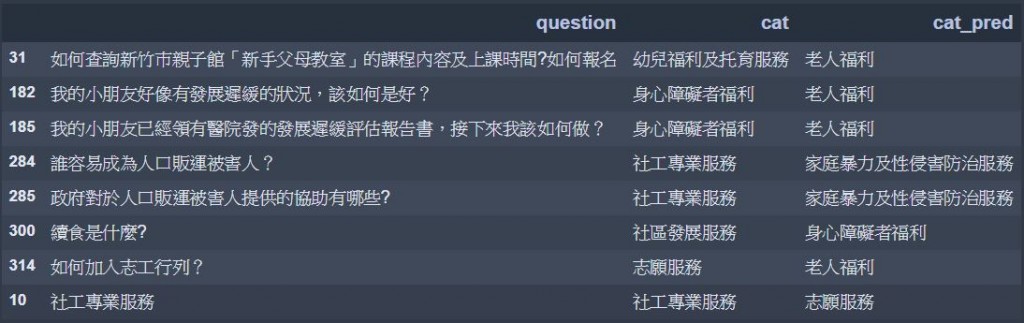
df_train_error = df_train[['question', 'cat']]
df_train_error['cat_pred'] = df_train_error['question'].apply(predict)
df_train_error.loc[df_train_error['cat'] != df_train_error['cat_pred'], ['question', 'cat', 'cat_pred']]
query = input("請輸入你的問題?\n")
predict(query)
code在這裡


