要取得html檔,我們首先就必須了解,前端(瀏覽器)是如何跟每個網站的伺服器要資料,以下詳細說明。
從RestfulApi的理論來說,目前一般網頁除了透過URL(網址)去取得網頁之外,都還會配上一個HTTP動詞,增加前端介面跟資料庫互動的彈性,大家有興趣可以看一下WIKI。
一般在瀏覽器上輸入URL進入網頁都是預設為GET動詞,就是純粹從資料庫中取出資料。
POST動詞則是送出一筆表單資料,比較常見的出現地點是各位在申請帳號,輸入完資料之後按下提交那一刻,瀏覽器除了會自動重新轉向新的URL外,還會配上POST的動詞,如此則會回傳一筆表單資料伺服器,然後再進一步導向「申請成功」的介面。而這兩個動詞也是爬蟲領域當中比較常用到的,其他動詞若各位對架設API有興趣,可以自己再去學習。
需要特別提醒的是,因為POST是送出一筆表單資料,所以下面「用法」環節,也要傳送一筆python中dict型別的資料給伺服器,才能得到POST方法配上URL回傳回來的資料。
至於如何進一步去查看,目前的網頁是透過GET或是POST而回傳的結果,則可以按下F12,點到Application(如果是空的,可以按一下F5重新整理),並透過每一份文件中的Preview進一步確定回傳的文件中哪一份是你要的,然後再點回Header去看,Request Method後面是GET或是POST。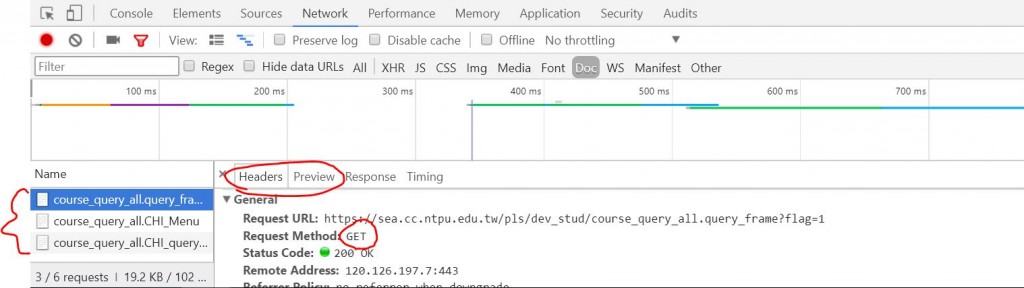
import requests # 使用requsts套件
# GET
# 上圖(Http Verb)中的Request URL
url = "https://sea.cc.ntpu.edu.tw/pls/dev_stud/course_query_all.CHI_query_common"
re = requests.get(url)
re.encoding='big5'
# re.encoding='cp950'
# re.encoding='utf8'
print(re.text)
# POST
url = "https://sea.cc.ntpu.edu.tw/pls/dev_stud/course_query_all.queryByAllConditions"
data ={
"qCollege":"法律學院".encode('big5'), #用big5編碼後傳輸
"qdept":"LU31",
"qYear":105,
"qTerm":2,
"seq1":"A",
"seq2":"M"
}
re = requests.post(url,data=data)
re.encoding='big5'
# re.encoding='cp950'
# re.encoding='utf8'
print(re.text)
如果發現爬下來的的頁面無法解析的話,大部分時候是編碼的問題,編碼一般都是用utf8,這個包含的字量比較多,例如「喆」在其他編碼中一班會用「吉吉」儲存,不過比較老舊的非英文網站,或是政府官方網站,如果是中文的話很可能會使用cp950或是big5,這個編碼一般都是從html文件中(所有的html文件都有head跟body兩個部分)的head部分找得到,按下F12找到Elements。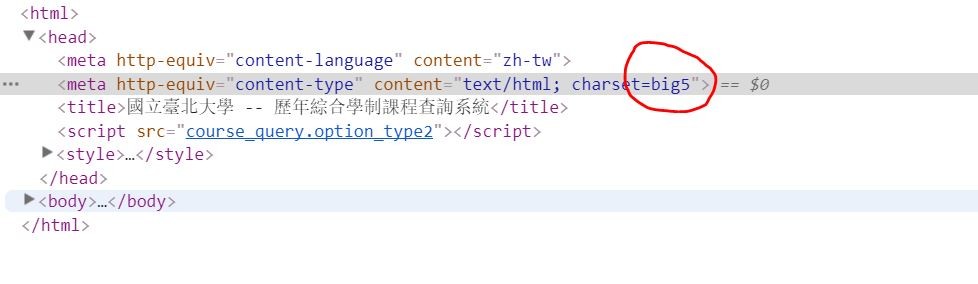
狀況一-爬下來的html檔是亂碼: 這種狀況可直接設定requests類別實體下的encoding屬性為相對應的編碼,上面「使用方法」中已經有使用過,就不再贅述。
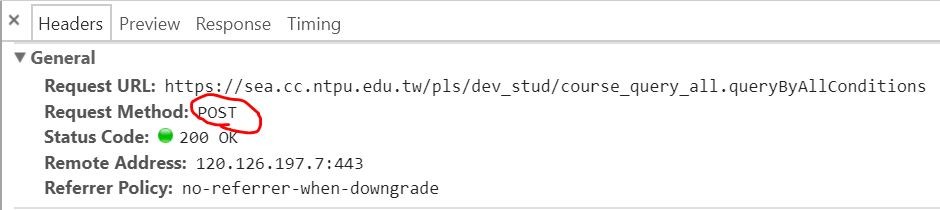
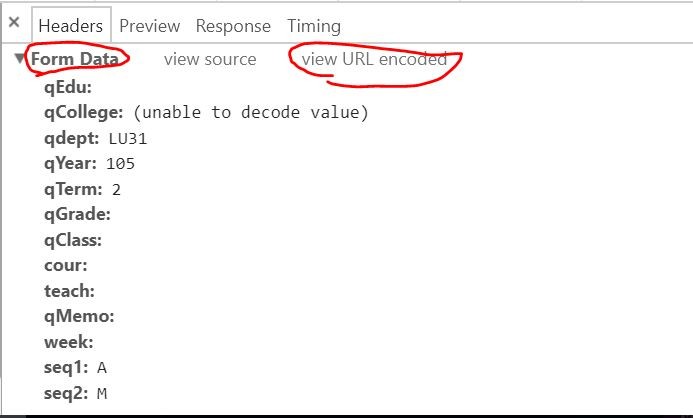
狀況二-POST Data是亂碼: 如上圖(Post Data)中的qCollege欄位的值即是亂碼,此時點擊此途中右上角的view URL encoded,並複製編碼下的字串到webatic去解碼,了解這個編碼背後的意思。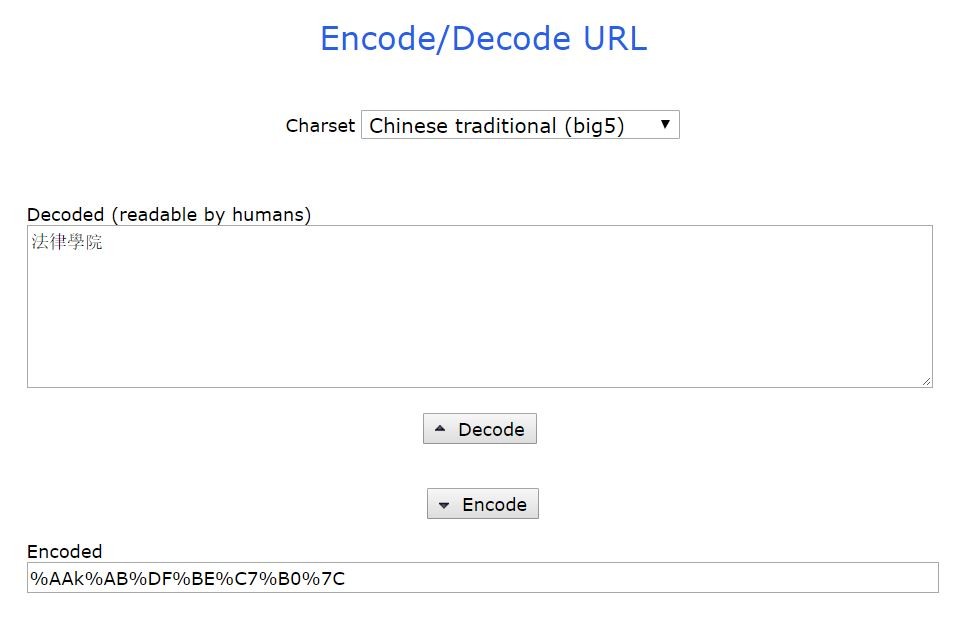
若不先將html存成純文字檔案,有可能會產生兩個大問題。第一、電腦的記憶體有限且相對不穩定,所以如果把每個頁面都用暫存存起來,可能會產生記憶體不足,或是程式執行出錯時暫存全部被洗掉的問題。第二、如果每次測試解析html之前都要上網站去get一次,量大的話很有可能會被鎖定IP。因此,檔案讀寫是爬蟲過程中不可或缺的一項技能。使用的套件是python內建的套件open,我們直接承接上面的re.text字串,進行以下示範。
## Write File
path = "htmlTest" # 你檔案想要存放的檔名,如果沒給路徑、直接寫檔名,將存在與你現在所執行的python檔同一個資料夾中
file = open(path, 'w', encoding='utf8')
# 第一個參數(path): 如果該路徑下,有相同檔名的檔案,將會直接複寫且不可回復。若沒有,系統則會自動幫你開一個新檔案
# 第二個參數('w'): 一般來說,我只用到'w'以及'r',分別是'寫'與'讀'的意思,其他二進位檔案的讀寫方式,各位有興趣可以自行去研究。如果要讀檔案,直接把'w'改成'r'即可。
# 第三個參數(encoding='utf8'): 指的是開啟這個檔案所使用的編碼,因為windows如果是中文版的,預設打開編碼是cp950(滿討厭的),所以在寫入檔案的時候,最好用utf8編碼,裡面的字才不會跑掉。
file.write(re.text)
file.close() # 寫完要關掉檔案,才會成功存檔。
## Read File 如果你已經把上面程式碼成功執行,則可以往下試著把它讀出來
path = "htmlTest"
file = open(path, 'r', encoding='utf8')
# 三種讀取方式,每次打開檔案請擇一使用,若重複使用會出現問題。
# 一、一次全部讀出來
context = file.read()
# 二、一次讀一行出來
file.readline() ##讀第一行
file.readline() ##讀第二行
file.readline() ##讀第三行
# 三、透過迴圈方式一次讀一行出來
for line in file:
print(line)
file.close()
明天將說明如何應付一般網站的防爬蟲機制以及萬惡的javascript,下級待續:))


