最簡單的理解方式就是舉例,我們就拿電影來作為例子,簡單解釋一下什麼是分類問題。其中最能夠直接想像的大約就是區分電影的類別,愛情片、文藝片、動作片或是愛情動作片。不過如果你認真想想,可能你不只要區分這種形式的類別,在實際應用上,你可能要區分這部電影是保護及、限制級、或是普遍級。再往下想細一點,你可能會慢慢發覺到,期時尚業用途上,電影公司關心的可能不是他的分類或分級,他關心的是這部電影會不會紅,所以你亦可以用分類演算法計算出,這部電影屬於「會紅」或「不會紅」。接著你可能會開始思考推薦問題,架設某使用者喜歡A電影,那麼你要怎麼樣計算出其他電影與A電影是「相似」或「不相似」。
以上的種種,從我們最一班可以想像到的類別到分級,在道上業運用中的篩選與推薦都屬於分類問題的範疇中,因此大家也可以發現,其商業價值並不低。不過說實話,他也有個瓶頸,就是絕大多數的分類演算法無法解決連續變數的問題。舉例來說,經濟成長率會是多少?商品價格是多少?或是這個員工的薪資是多少?如果真的要用分類演算法來解決這類問題,那就必須先經過切分,而犧牲一些原有資料的特性,也會增加更多不準確的因素在其中。
接著,就讓我們實際進到分類演算法的講解吧。分類演算法這個領域其實是一個已經發展很久的領域,演算法種類繁多,無法將所有演算法都一一講解,不過慶幸的是,如果各位學完一些演算法的基礎,往後大家在理解其他有用的演算法的時候,其實都只是這接基礎的結合與變形,因此,今天將選三個演算法來跟各位介紹: K Nearest Neighbor(KNN), Logistic Regression, Decision Tree。以下也將進一步介紹為甚麼選擇這四個演算法來跟各位介紹。
import matplotlib.pyplot as plt
from planar_utils import plot_decision_boundary, sigmoid, load_planar_dataset, load_extra_datasets
import numpy as np
import pandas as pd
import os
from sklearn.neighbors import KNeighborsClassifier ## KNN
from sklearn.linear_model import LogisticRegressionCV ## logistic regression
from sklearn.tree import DecisionTreeClassifier ## decision tree
from sklearn.svm import SVC ## SVM
# visualization
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn.decomposition import PCA
# First Dataset
datas = []
X, Y = load_planar_dataset()
name = 'flower'
X = X.T
Y = Y[0]
datas.append((name, X, Y))
# Second Dataset
noisy_circles, noisy_moons, blobs, gaussian_quantiles, no_structure = load_extra_datasets()
datas.append(("noisy_moons", noisy_moons[0], noisy_moons[1]))
KNN顧名思義就是找K個最近的點,然後讓他們投票,如果與你最近的五個資料點當中,有3個是第一類,那麼這個測試點就是第一類。這個做法非常簡單、暴力,因此也常常被當作baseline基準(也就是最陽春的做法,其他作法一定要比這樣的做法又更好的表現才有意義)。
另外,如果大家有看前面的文章的話,必須要跟K-means做區辨,K-means是分群演算法,先初始化K個重心,然後找每個點最近的重心,然後重新找重心,並不斷的重複。
for name, X, Y in datas:
clf = KNeighborsClassifier(n_neighbors=3) ## 設定用最近的3個鄰居投票
clf.fit(X, Y) ## 訓練模型
y_pred = clf.predict(X) ## 預測模型
print('Accuracy', str((Y == y_pred).sum()/ X.shape[0]*100)+"%") ## 計算精準度
plot_decision_boundary(lambda x: clf.predict(x), X.T, Y) ## 視覺化分類器的分類結果
plt.savefig(os.path.join('pic', name+'_knn')) ## 儲存圖片
plt.show()
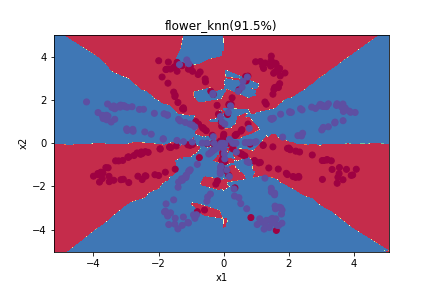
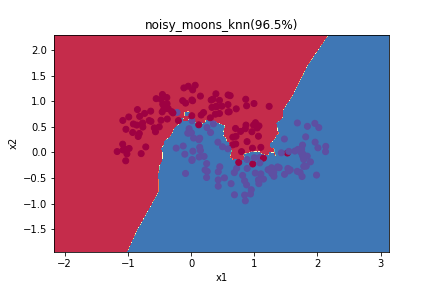
圖上的數字指的是精準度(Accuracy),也就是幾%的資料點是分類正確的。這邊大家會發現,因為k開得比較小,雖然訓練資料的準確率比較高,但是他會過度的適應(overfitting)這樣的資料(training data),而沒又辦法推廣到其他資料集上(testing data),所以建議還是要獨立出testing data做測試,找到比較適當的k的大小。
這是一個回歸式,一般的回歸式可以用來解決連續變數的預測問題,自然也可以有辦法解決類別變數的分類問題。因此這一支派的研究者就發展出了這樣的回歸式。而說到回歸式的運作邏輯,當然就是最小化Mean Square Error(MSE),所謂MSE也就是下圖(取自wikipedia)中的每一個點(y_true)到線上的垂直距離(residual),平方、加總、開根號、取平均。而一旦找到最小值的MSE,我們也就可以拿來預測了。
這邊必須注意的是,一般透過回歸模型進行建模的時候,不會用那麼簡單的數學式,以會考慮平方項與交乘項等,因此以下的效果其實如果模型設計得好的話,也會有機會變得更好。不過因為變數調整的模型設計,一方面比較強調係數的解釋,而非預測,因此這邊就不多談了。
for name, X, Y in datas:
clf = LogisticRegressionCV()
clf.fit(X, Y)
y_pred = clf.predict(X)
print('Accuracy', str((Y == y_pred).sum()/ X.shape[0]*100)+"%")
plot_decision_boundary(lambda x: clf.predict(x), X.T, Y)
plt.title(name+'_logistic(' + str((Y == y_pred).sum()/ X.shape[0]*100)+"%)")
plt.savefig(os.path.join('pic', name+'_logistic'))
plt.show()
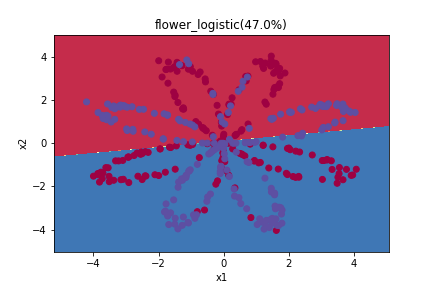
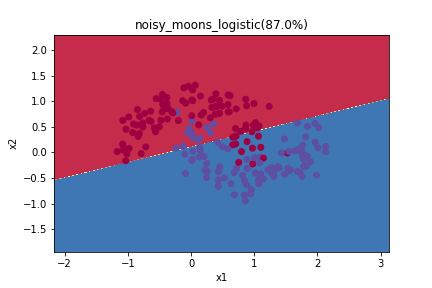
這邊可以注意,因為logistic試算出一個函數式還做預測,所以切分的方式是一個線性的函數。
指所以會選擇這個演算法的原因是這個演算法,在經過不斷改良與改進之後,目前為止算是兩個最常被使用的分類器之一,不過sklean中的Decision Tree本身非常原始,經過改良的各式決策樹效果才會好,這邊先介紹基礎款給大家,讓大家先認識一下這個演算法的運作原理。
這個演算法主要是希望,可以把所有的決策過程,變成一個束狀的決策過程。舉例來說,我有以下資料,我希望可以預測出一個客戶「會」或是「不會」買電腦。
| age | income | student | credit_rating | buys_computer |
|---|---|---|---|---|
| <=30 | high | no | fair | no |
| <=30 | high | no | excellent | no |
| 30…40 | high | no | fair | yes |
| >40 | medium | no | fair | yes |
| >40 | low | yes | fair | yes |
| >40 | low | yes | excellent | no |
| 31…40 | low | yes | excellent | yes |
| <=30 | medium | no | fair | no |
| <=30 | low | yes | fair | yes |
| >40 | medium | yes | fair | yes |
| <=30 | medium | yes | excellent | yes |
| 31…40 | medium | no | excellent | yes |
| 31…40 | high | yes | fair | yes |
| >40 | medium | no | excellent | no |
那麼變成一個完整個完整的分類規則如下(取自Tutorial Point)。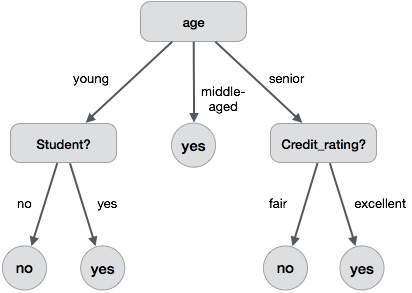
至於哪一個屬性應該放上面做為比較前段的分類標準則是這個演算法中的核心,主要是透過計算不同屬性分類前後資訊亂度來決定,分類前後資訊亂度的差異(information gain)越大者(分完之後資訊越乾淨者),將優先被拿來作為分類標準,如下圖最左邊者因為每一個類別的數量各一半,所以資訊的亂度最大,而最右邊的圖最乾淨、只有一個類別。所以如果有一個屬性可以把越多的分類完的群組變得越乾淨,那麼就會被優先拿來作為分類標準。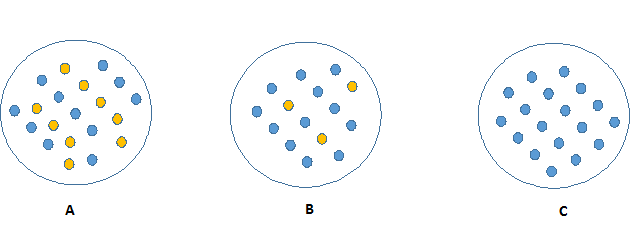
至於計算亂度的數學方法稱為entropy,因為篇幅因素就不多說明了,有興趣可以參考我的python教材。不過如果你對資料科學真的有興趣、想要認真學習,很建議你一定要完整的了解entropy的運算方式。
for name, X, Y in datas:
clf = DecisionTreeClassifier()
clf.fit(X, Y)
y_pred = clf.predict(X)
print('Accuracy', str((Y == y_pred).sum()/ X.shape[0]*100)+"%")
plot_decision_boundary(lambda x: clf.predict(x), X.T, Y)
plt.title(name+'_tree(' + str((Y == y_pred).sum()/ X.shape[0]*100)+"%)")
plt.savefig(os.path.join('pic', name+'_tree'))
plt.show()
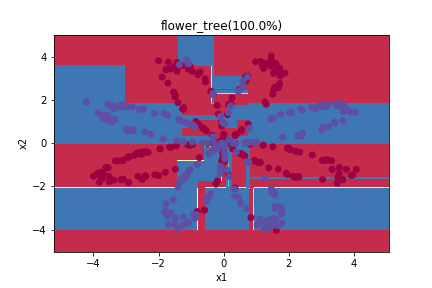
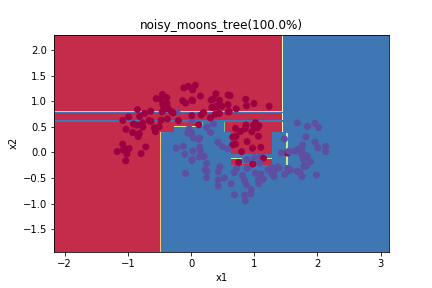
這邊大家可以注意到,因於決策樹把分類問題轉換成一個個的切分好的rule,所以你可以發現圖上的切分方式非常不平滑且很多稜角。
code在這裡


