
這一波人工智慧(Articial Intelligence,AI)風潮方興未艾,產學研界發表不少的具體研發成果,例如AlphaGo、機器人、無人駕駛自動車、ChatBot、人臉辨識、語音辨識...等,加上各種媒體新聞不斷吹捧,搞的好像不懂AI的資訊人,就快要失業了,於是,狂買了近二十本的相關書籍,準備好好的努力一下,一窺 AI 奧秘,剛好藉由鐵人賽督促自己,記錄過程並將心得與同好分享,也希望能獲得各位先進的指教。
人工智慧其實已經歷了三波熱潮,如下圖,前兩波都功敗垂成,只留下一些美麗的願景。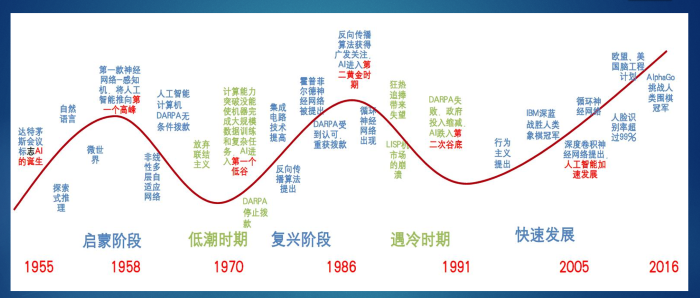
圖. AI 的三波熱潮, 資料來源:http://www.testleo.com/blog/archives/6121 。
為什麼這一波會成功? 主要有幾個動力:
種種的因素擘劃出美麗的未來願景,還是海市蜃樓? 且看未來發展。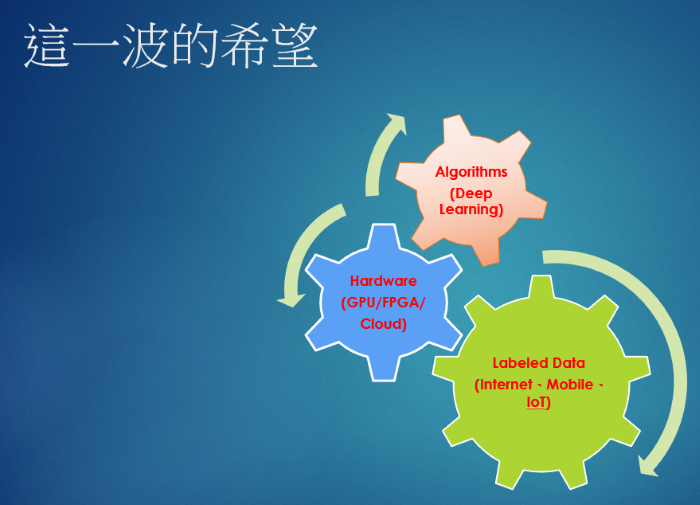
圖. 第三波AI的動能,資料來源: 人工智能,請準備迎接冬天
這一波AI的主軸就是『機器學習』(Machine Learning),強調讓『機器自我學習』,藉由資訊的蒐集與演算法的改進,讓機器可以吸收知識,自我學習,並根據學習的成果(即預測的準確性)修正與反饋,不斷提升機器的智慧。這種解決問題的方法與傳統的系統開發想法有所不同,Machine Learning 不只靠演算法解決問題,也靠不斷累積的資料,將之轉化為『知識』,深植於模型內,請參考下圖說明: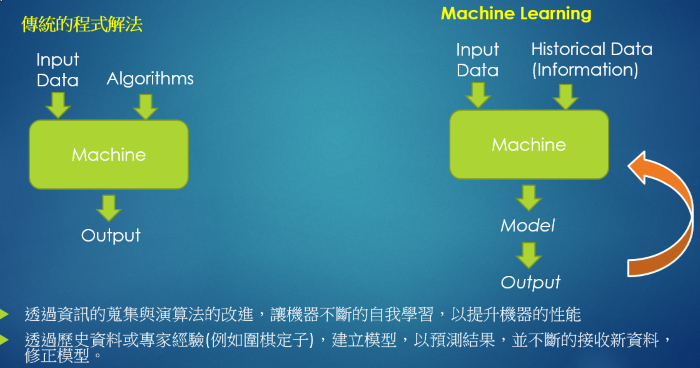
圖. 傳統程式開發方式 vs. Machine Learning 解決問題方式
Machine Learning 目前偏向大量使用統計理論作為建立模型的基礎,尤其是 Data Mining 方法,包括『決策樹』(Decision Tree)、迴歸分析(Regression)、支援向量機(SVM)、聚類分析(Clustering)、單純貝氏分類法(Naive Bayes classifier)...等,但目前最夯的是『神經網路』(Neural Network),它主要是模仿生物的神經系統,透過層層連接的『神經元』(Neuron),建立傳導的模型,以推論輸入(Input)到輸出(Output)的過程。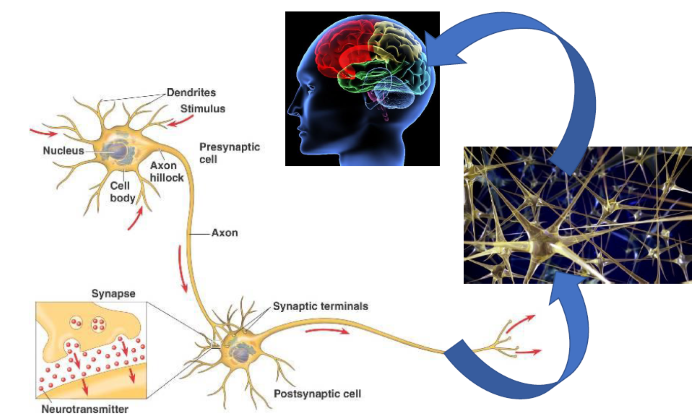
圖. 神經系統,圖片來源:李宏毅 一天搞懂深度學習
現在網路大廠紛紛推出『神經網路』(Neural Network)的框架(Framework),而且大都是Open Source(佛心來也),以支援Python語言為主流,安裝方便,入門的門檻也很低,只要寫個十幾行的程式,就能辨識阿拉伯數字,乍看一下,好像依樣畫葫蘆,就可以寫出個應用系統了,但是每一個演算法都有很多的假設與適用範圍限制,可以直接套用,解決問題的機率其實很低,因此,還是要了解其原理,進而知道其假設、限制及可變通的方式(至少調調參數吧!),才能真正解決問題,若把烏龜辨識為槍枝,那就窘了。
這個系列的發文,會以 Google TensorFlow 的框架為基礎,採用架構在它上面的Keras為程式開發主軸,它同時也支援其他框架,如 CNTK、Theano,這類的程式(Keras、TFLearn) 稱為 Meta Framework,是學習 Neural Network 很好的學習工具。
由於 Machine Learning 技術主要是建構在統計及數學的基礎上,再加上眾多演算法(Algorithms) ,對於從事應用系統開發多年的我而言,要在短時間內打通任督二脈,甚至能動手開發,實在很艱辛,雖然在校學統計6年(從來沒應用過,所以也忘得差不多了),又開發系統多年,在自學過程中,仍然頻頻卡關,腦袋打結,雖然如此,還是在過程中有很大的收穫,因此,為降低讀者的學習障礙,撰文以『輕鬆/快樂學習』為出發點,用圖說故事,希望有助於釐清各個演算法觀念、原理與實作。
系列發文將包括以下內容:
觀念會盡量以圖說明,原理會牽涉統計,但不會有數學推導(因為我也不會),實作會以Python/Keras程式撰寫,讀者可以各取所需,不必吃滿漢全餐。
由於鐵人賽時間緊迫,一邊讀書、一邊看/寫程式、一邊撰文,發文內容如有謬誤,還請各位先進不吝指正,也請各位不要期望過高,畢竟小弟也是剛入門而已。
工商廣告一下,系列文章整合至以下書籍:
PyTorch:
開發者傳授 PyTorch 秘笈
2022/6/20 出版。
TensorFlow:
深度學習 -- 最佳入門邁向 AI 專題實戰。


 iThome鐵人賽
iThome鐵人賽