中文自然語言處理,與英文最大的差別就在斷詞,但是說實話,這個部分至今仍然沒有一個套件可以做好很好。目前而言,繁體中文有兩個套件可以使用,一個是中研院開發的斷詞系統,但是經過多方打聽,使用上並不是特別方便。因此我個人打選擇使用第二套系統jieba,中文叫做結巴,很幸運地這個套件有python的介面,使用上非常容易,只是這是大陸人開發的系統,必須自行輸入繁體字典,這篇文章的繁體字典出處在這邊。順帶一提,這篇文章寫得很好,對於jieba如果有想要有更深的認識,可以好好拜讀。
另外,由於這篇文章有使用到許多外部資源,所以若有需要尋找文章中出現的其他檔案,請參考這個repo
import jieba
jieba.set_dictionary('dict.txt.big') # 如果是使用繁體文字,請記得去下載繁體字典來使用
with open('stops.txt', 'r', encoding='utf8') as f: # 中文的停用字,我也忘記從哪裡拿到的,效果還可以,繁體字的資源真的比較少,大家將就一下吧
stops = f.read().split('\n')
結巴的斷詞分成兩個模式,精準模式只找到系統演算出最精準的斷詞可能,全斷詞模式則是把所有可能的斷詞模式列出來,如果你想要用來做文本分析,句子又沒有很長的的時候,建議你可以使用全斷詞模式,可以增加文跟文章之間的可比性,我曾經因為把斷詞模式改掉,在預測準確率上面就從96%變成99%,大家可以參考一下。
print([t for t in jieba.cut('下雨天留客天留我不留')])
print([t for t in jieba.cut('下雨天留客天留我不留', cut_all=True)])

這個部分跟英文沒什麼差別啦,只是中文的停用字並沒有被內建在nltk當中,要自己找檔案,上面Import是我找到的檔案,大家覺得不夠好也可以自己再去找。不過因為實在太長的,我就不全部列出來了。
雖然jieba也有提供詞性標注功能,不過實在做得還不到能用的程度,實務上我也沒什麼在用,所以大家就先略過這個部分吧。
由於這邊文章實在太短了,又有很大部分與昨天的文章重複,所以我們就拿上面我已經打好的文字來做分析吧。
from collections import Counter
from wordcloud import WordCloud
from matplotlib import pyplot as plt
testStr = """
前言
中文自然語言處理,與英文最大的差別就在斷詞,但是說實話,這個部分至今仍然沒有一個套件可以做好很好。目前而言,繁體中文有兩個套件可以使用,一個是中研院開發的斷詞系統,但是經過多方打聽,使用上並不是特別方便。因此我個人打選擇使用第二套系統jieba,中文叫做結巴,很幸運地這個套件有python的介面,使用上非常容易,只是這是大陸人開發的系統,必須自行輸入繁體字典,這篇文章的繁體字典出處在這邊。順帶一提,這篇文章寫得很好,對於jieba如果有想要有更深的認識,可以好好拜讀。
另外,由於這篇文章有使用到許多外部資源,所以若有需要巡長文章中出現的其他檔案,請參考這個repo
斷詞
結巴的斷詞分成兩個模式,精準模式只找到系統演算出最精準的斷詞可能,全斷詞模式則是把所有可能的斷詞模式列出來,如果你想要用來做文本分析,句子又沒有很長的的時候,建議你可以使用全斷詞模式,可以增加文跟文章之間的可比性,我曾經因為把斷詞模式改掉,在預測準確率上面就從96%變成99%,大家可以參考一下。
去除停用字
這個部分跟英文沒什麼差別啦,只是中文的停用字並沒有被內建在nltk當中,要自己找檔案,上面Import是我找到的檔案,大家覺得不夠好也可以自己再去找。不過因為實在太長的,我就不全部列出來了。
詞性標注
雖然jieba也有提供詞性標注功能,不過實在做得還不到能用的程度,實務上我也沒什麼在用,所以大家就先略過這個部分吧。
其他
由於這邊文章實在太短了,又有很大部分與昨天的文章重複,所以我們就拿上面我已經打好的文字來做分析吧。
"""
stops.append('\n') ## 我發現我的文章中有許多分行符號,這邊加入停用字中,可以把它拿掉
stops.append('\n\n')
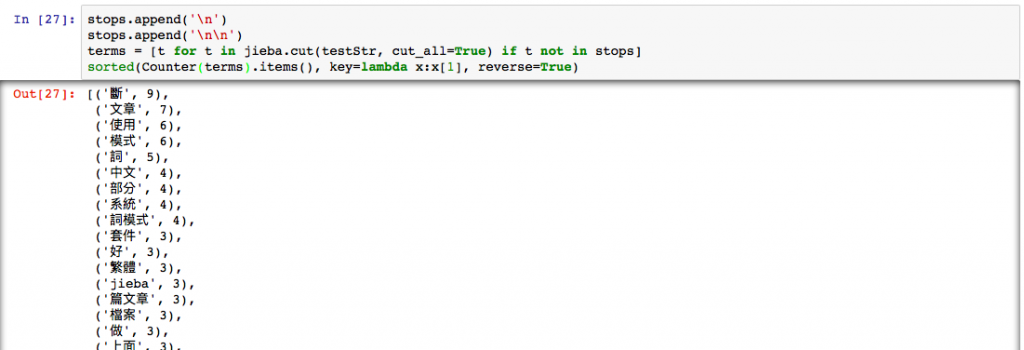
terms = [t for t in jieba.cut(testStr, cut_all=True) if t not in stops]
sorted(Counter(terms).items(), key=lambda x:x[1], reverse=True) ## 這個寫法很常出現在Counter中,他可以排序,list每個item出現的次數。
wordcloud = WordCloud(font_path="simsun.ttf") ##做中文時務必加上字形檔
wordcloud.generate_from_frequencies(frequencies=Counter(terms))
plt.figure(figsize=(15,15))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()

from PIL import Image
alice_mask = np.array(Image.open("cloud_mask7.png")) ## 請更改cloud_mask7.png路徑
wc = WordCloud(background_color="white", max_words=2000, mask=alice_mask, font_path="simsun.ttf")
wc.generate_from_frequencies(Counter(terms)) ## 請更改Counter(terms)
# wc.to_file(path.join(d, "cloud.png")) ##如果要存檔,可以使用
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.figure()
plt.imshow(alice_mask, cmap=plt.cm.gray, interpolation='bilinear')
plt.axis("off")
plt.show()

請問怎麼預測分詞的準確率呢?
除非你有正確答案,不然也無法計算。
好的,謝謝你,所以我必須事先人工分詞,在由分詞結果判斷分詞的正確率?
請問再有正確答案的情況下又要怎麼比對正確率呢?
如果拿文章中的資料做舉例的話。
我其實沒有認真研究過這個議題,不過我覺得還是可以一些傳統的評價方法,像是precision或是recall甚至f-score,以下簡單舉例。(我剛剛問了這領域的專家,說普遍還是用f-score
下雨天留客天
Y_true=[‘下雨天’, ‘留客’ , ‘天’]
Y_pred=[‘下雨’, ‘天留客’, ‘天’]
Precision=(模型找到&正確答案)/模型找到=1/3
Recall= (模型找到&正確答案)/正確答案=1/3
F-score= precision跟recall的調和平均數
Precision=(模型找到&正確答案)/模型找到=1/3
意思是說Y_pred與Y_true的交集除以Y_pred的意思嗎?
如果是這樣的話,我了解你的意思了,非常謝謝!這對我的幫助非常大!太感謝你了!


