文件檢索英文叫Inofrmation Retrieval,簡稱IR。簡單來說,他想要處理的問題就是:如何在大量的文件中,尋找出使用者需要的那一份文件。
這個技術的難點有二,其一待選文件非常大量,檢索效率常常是關注的焦點,不過隨著大多數檢索引擎都能夠在不到一秒的時間回饋出資訊之後,大家也就把焦點關注到第二點,如何精準的檢索出使用者需要的資訊。
這個領域其實已經發展許久,在深度學習還沒有大紅大紫之前,這個領域就已經發展出一套可以檢索問題的方法(比if else更進階的方法),即便深度學習成為主流後,由於深度學習在自然語言處理上面的門檻及成本太大太高,仍然有許多相關的專案是使用傳統的方法在處理問題。
因此,這篇文章將說明目前最主流的資訊檢索方法:TFIDF + Cosine Similarity,根據維基百科,有83%子文字為基礎的檢索引擎是使用這個方法。至於其他方法,如BM25或是Bayesian雖然有時候表現非常好,因為篇幅因素這裡就不介紹了,有興趣自己可上網survey。
這次把我在新竹黑客松得獎的作品新竹市政府社會處常見問答集LineBot專案的一部份拿出來跟大家分享。這個作品主要是希望做成LineBot背後的檢索引擎,讓使用者的問題可以自動檢索出適當的回覆,這個專案的另一部分是假設無法找到適當的回覆則回覆其聯絡窗口,不過不同的問題會有不同的聯絡窗口,如何分類不同問題到不同聯絡窗口,後面的文章會繼續介紹機器學習中的分類方法。
其實這個技術主要是希望可以讓文章以向量的形式來呈現,一但能夠轉化為向量,電腦才有近一步運算的可能。而這條向量,有以下幾個特性。
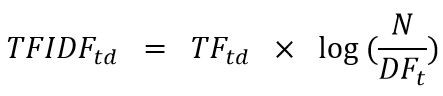
所謂TFIDF應分成兩個部分來理解:TF(Term Frequency)以及IDF(Inverted Document Frequency)。
| number | log(number) |
|---|---|
| 1000 | 6.90775527898 |
| 2000 | 7.60090245954 |
| 4000 | 8.2940496401 |
| 8000 | 8.98719682066 |
| 16000 | 9.68034400122 |
| 32000 | 10.3734911818 |
| 64000 | 11.0666383623 |
| 128000 | 11.7597855429 |
| 256000 | 12.4529327235 |
以下舉個例子,把三個句子轉成向量,大家應該比較可以理解。
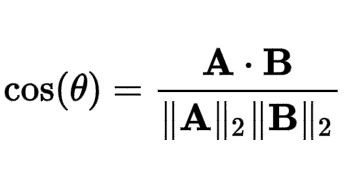
如果大家有經歷過一點高中數學,應該對於cosine夾角的計算還有一點印象,大家應該多少看得懂上面的公式。A與B分別代表兩篇文章的向量,
說一下題外話,其實衡量兩條向量相不相近,除了用相似度的概念去衡量之外,也會用距離的概念去理解,具體來說,有兩種比較簡單的衡量距離的方式可以介紹給大家,L2指的是歐幾里得距離(euclidean distance)。舉例來說,(X1, Y1)與(X2, Y2)的距離等於((X2-X1)^2 + (Y2-Y1)^2)^(1/2)。L1又稱為City Block,距離就是|X2-X1| + |Y2-Y1|,而之所以會稱為City Block的原因是因為,在城市中從A點走道B點必然必須繞過一個個的Block,而不能從大樓中間穿過去。
到此為止,大家已經把資訊檢索的理論學習完畢,明天將透過實作的方式,帶大家操作一次,大家就可以熟悉這個技術摟!!


