在前面討論完了classifiers的誤差率與正確率
其中誤差其實有若干種不同的型態
我們使用confusion matrix來研究classifiers的錯誤
classifiers做出的預測為Predicted label而真實的結果為True label,在這樣的情境下會有四種的結果
我們只探討錯誤的部份,一共可以分成兩種狀況
| Predicted label + | Predicted label - | |
|---|---|---|
| True label + | True Positive | False Negative |
| True label - | False Negativ | True Negativ |
想像一下有兩種情境,分別是垃圾郵件的過濾與醫療的診斷,我們分別要付出什麼代價?
我們在來看個超過兩種分類的confusion matrix
假設有100個測試樣本,分成三類:健康、感冒、流感(70、20、10)
| 健康 | 感冒 | 流感 | |
|---|---|---|---|
| 健康 | 60 | 8 | 2 |
| 感冒 | 4 | 12 | 4 |
| 流感 | 0 | 2 | 8 |
-正確率=(60+12+8)/100 = 80%
透過這個矩陣我們可以得知,我們可以了解我們犯的錯誤,以及它代表的意義
在回歸模型中我們討論正確/誤差率與模型複雜度之間的關係
到底一個模型要多少資料才能夠成為一個夠好的模型?理論上資料當然越多越好
實際上呢?實際上我們有技巧可以讓我們知道現在的模型誤差有多大?常犯那些錯誤
在資料與模型的關係中有個極為重要的指標,我們稱之為earning curves
我們將我們的資料量與測試誤差率關聯在一起
直覺上我們可以知道,當你的資料量越小的時候,你的測試錯誤率理當越高
從earning curves來看會發現,當資料量大到一定程度時,會形成一個偏差
那這個偏差有辦法變成0嗎?事實上偏差代表著,即便你的資料無限大,它也沒辦法變成0,為什麼呢?
在真實世界中,越複雜的模型將存在著越小的偏差,比如前面提到的食記
如果只是簡單的詞,好、棒、讚、屎、普通....
那簡單的classifiers也能做到,但即便你有全世界的資料,你也會遇到諸如:"not good"這樣的字句(筆者在這邊本來想用不好吃,但是我後來想想用not good來呈現還是比較直覺)
原因是因為只考慮了"not"以及"good",所以會有更複雜的狀況需要更複雜的模型
但是當你的模型變得複雜(不管是感冒、健康多增加了一個流感,或是"good"與"not good")
當參數變多了,資料就需要更多
回過頭來看earning curves,當資料量少的時候,相對複雜的模型其錯誤率就會比較高
但是隨著資料量的提昇,它將會贏過資料量相對少的模型,因為它能夠辨別"good"與"not good"
值得注意的是,即便模型變得更棒棒了,但是偏差依舊存在
截至目前為止,我們討論許多的例子,但一般來說我們會想做更多一點,舉例來說
-味增湯很好喝,服務品質優良 <- ""+""
-味增湯好喝,涼麵普通 <-不確定
所以一個classifiers不光光只是給出正/負兩種結果而已,還要給出它對這個結果信心有多大
解答這個問題的方式之一,就是機率
所以當你輸入一個句子X時,它必須輸出一個句子為正/負的機率
-味增湯很好喝,服務品質優良 <- P(y=+|x) = 0.99 //正面機率為0.99
-味增湯好喝,涼麵普通 <- P(y=+|x) = 0.55 //負面機率為0.55,因為我們不是很確定
在後面的課程會再深入討論,在知道機率之後,我們該使用那些策略來因應
同樣的我們若將之前回歸的流程圖,再用在Classifictaion會是這個樣子的
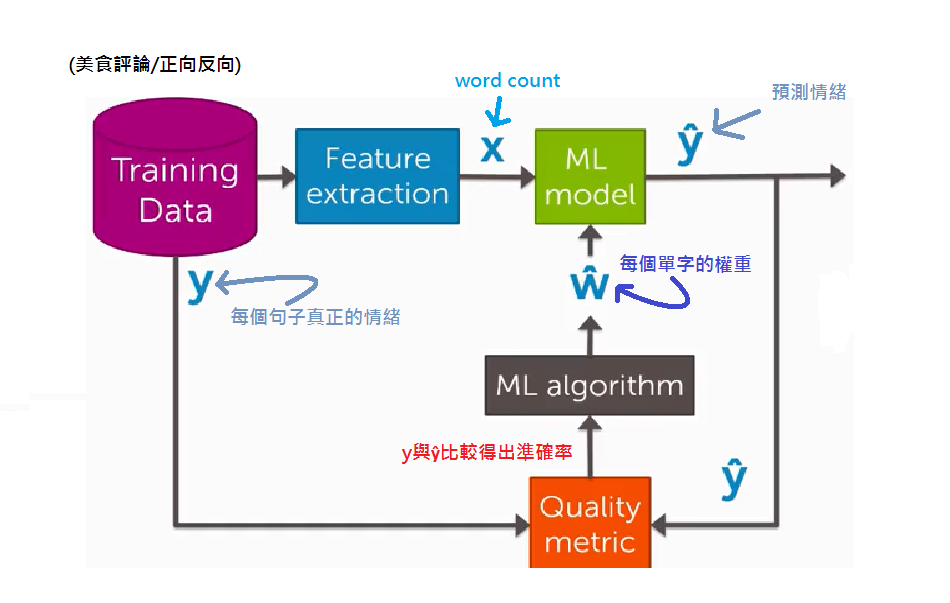
接下來會有一連串的長假(其實也只有三天),會開始前兩個主題的實作拉XDDD


