sqft_model.get('coefficients')
| name | index | value | stderr |
|---|---|---|---|
| (intercept) | None | -43814.8902666 | 5047.42632188 |
| sqft_living | None | 280.360245938 | 2.21700145099 |
我們可以從之前的模型去得到這些係數(權重)
我們已經做了一些簡單的回歸,如果你還記得,其實先前的資料還有許多的特徵
#將要新增的特徵,新增到list當中
my_features = ['bedrooms','bathrooms','sqft_living','sqft_lot','floors','zipcode']
sales[my_features].show
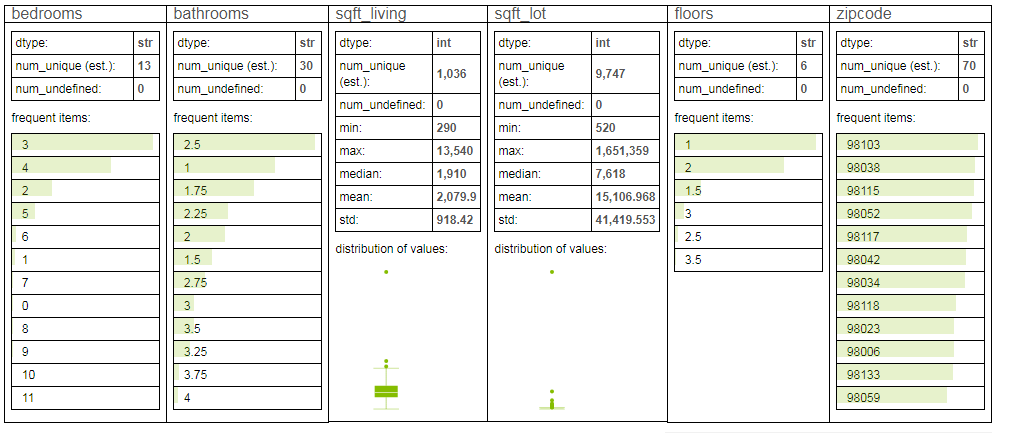
我們可以輕易地從中得知一些訊息
接下來我想對某些特徵做出對應的視覺化
#BoxWhisker Plot將會顯示兩個特徵之間的關係
#我想看看門牌與價格的關聯(我曾聽說掛上中正區的門牌50萬起跳、明明萬華就在隔壁)
sales.show(view='BoxWhisker Plot',x='zipcode',y='price')
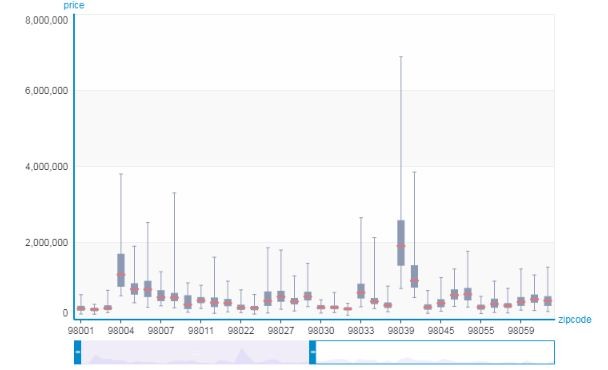
我們可以看到zipcode中98039的價格非常的誇張,記住這個數字,接下來將會揭曉
上面舉了一個郵政區號對價格的影響,但是這正確嗎?照理說臥室數量、衛浴數量也會對價格產生影響吧?
所以我們必須新增更多的特徵嗎?為了要驗證這件事情,我們只要在新增一個回歸把我們的特徵通通加進去在做比較即可
my_features_model = graphlab.linear_regression.create(train_data,target='price',features=my_features)
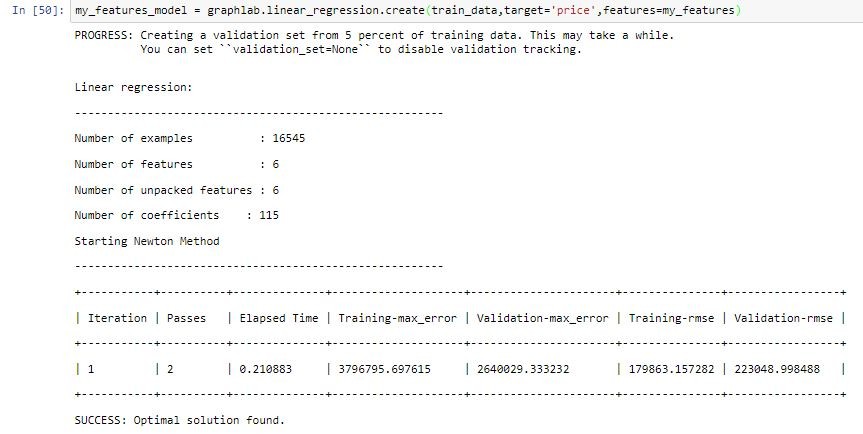
接著同樣衡量模型的結果
print sqft_model.evaluate(test_data)
# {'max_error': 4142275.367360657, 'rmse': 255188.09204898693}
print my_features_model.evaluate(test_data)
# {'max_error': 3500449.806693536, 'rmse': 179356.3725536438}
只取坪數大小為特徵的最大誤差約為400萬,而加入我選定的特徵最大的愈差約為350萬
方均根差從255000下降到179000,顯而易見的是加入更多資料可以降低更多的誤差率
接下來讓我們使用我們的模型來實際的預測我們的房價,我們從訓練集中隨意擷取一間房子
house1 = sales[sales['id'] == '5309101200']
# price:620000
| id | date | price | bedrooms | bathrooms | sqft_living | sqft_lot | floors | view | condition | grade | sqft_above | sqft_basement | yr_built | yr_renovated | zipcode | lat | long | sqft_living15 | sqft_lot15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5309101200 | 2014-06-05 00:00:00+00:00 | 620000 | 4 | 2.25 | 2400 | 5350 | 1.5 | 0 | 4 | 7 | 1460 | 940 | 1929 | 0 | 98117 | 47.67632376 | -122.37010126 | 1250.0 | 4880.0 |
接著間兩個模型都代入
print sqft_model.predict(house1)
# [630004.8234759354]
print my_features_model.predict(house1)
# [720058.291038626]
從結果來看未必增加越多特徵可以得到接近正確數字的解,有時候針對某些特定的房子,簡單的模型反而會表現得比複雜的模型好
不過一般情況下,越多特徵其表現應該是越精確的
house2 = sales[sales['id'] == '1925069082']
# price:2200000
| id | date | price | bedrooms | bathrooms | sqft_living | sqft_lot | floors | view | condition | grade | sqft_above | sqft_basement | yr_built | yr_renovated | zipcode | lat | long | sqft_living15 | sqft_lot15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1925069082 | 2015-05-11 00:00:00+00:00 | 2200000 | 5 | 4.25 | 4640 | 22703 | 2 | 4 | 5 | 8 | 2860 | 1780 | 1952 | 0 | 98052 | 47.63925783 | -122.09722322 | 3140.0 | 14200.0 |
這間房在2015-05-11被售出,4640平方公尺,遠比之前那間大很多
print sqft_model.predict(house2)
[1261846.2617304123]
print my_features_model.predict(house2)
# [720058.291038626]
[1451243.0229620067]
這次的結果顯示了,就比較合乎預期,模型2的預測比模型1來的優秀,但是即便如此還是離現實中有一段差距
在課程中教授揭露了這間房子是位於海邊的度假房
所以可以想見
即便你增加了更多的特徵,還是可能因為缺少關鍵特徵而使得預測結果離真實數據有極大誤差
感謝我的同伴提供了此等神物給我,讓我不用在用語法畫到手斷掉XD
markdown table editor 顧名思義,幫你自動產生語法表格的好物
接下來同樣會順著課程繼續往下做,我猜這門課應該到20天左右我就能跟完
最近上班都忙到比較晚(太遜),導致寫出來稿的品質都很差QQ
不過接下來會有比較長的假期,還好是單身狗,所以我會努力利用假期,讓文章品質越來越好的(握拳)


