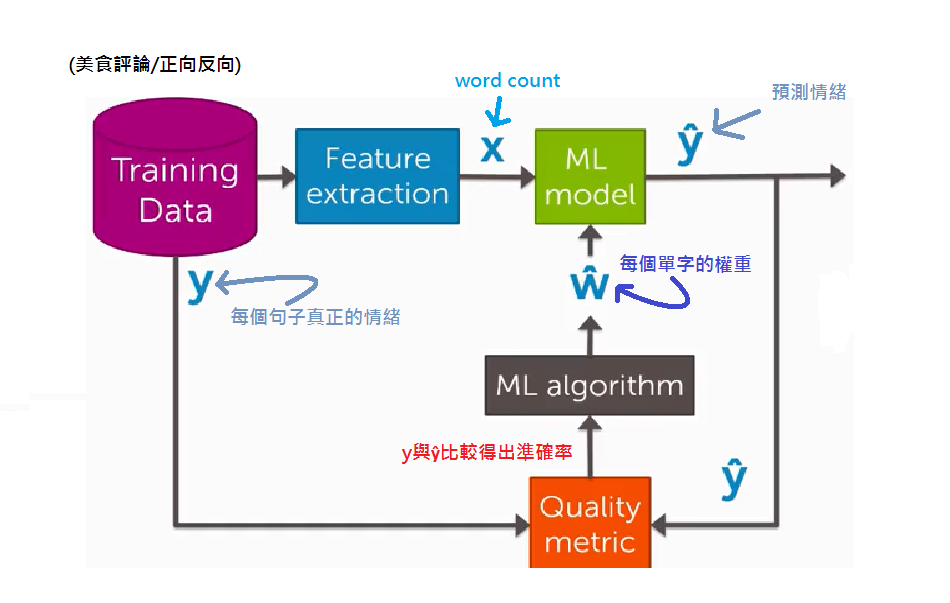
在分類這章裡面,我們討論了如何透過分類來搭建情緒分析器
接下將透過一個簡單的例子,帶大家做個簡單的情緒分析器
一樣要導入GraphLab
接著引入產品的資料(amazon_baby.gl),透過graphlab來讓資料視覺化
import graphlab
products = graphlab.SFrame('/home/user/nylon7/machine_learning/week3/amazon_baby.gl')
products.head()
最後我們可以透過head這個method來得到資料的前幾行
| name | review | rating |
|---|---|---|
| Planetwise Flannel Wipes | These flannel wipes areOK, but in my opinion ... | 3.0 |
| Planetwise Wipe Pouch | it came early and was notdisappointed. i love ... | 5.0 |
| Annas Dream Full Quiltwith 2 Shams ... | Very soft and comfortableand warmer than it ... | 5.0 |
| Stop Pacifier Suckingwithout tears with ... | This is a product wellworth the purchase. I ... | 5.0 |
| Stop Pacifier Suckingwithout tears with ... | All of my kids have criednon-stop when I tried to ... | 5.0 |
| Stop Pacifier Suckingwithout tears with ... | When the Binky Fairy cameto our house, we didn't ... | 5.0 |
| A Tale of Baby's Dayswith Peter Rabbit ... | Lovely book, it's boundtightly so you may no ... | 4.0 |
| Baby Tracker® - DailyChildcare Journal, ... | Perfect for new parents.We were able to keep ... | 5.0 |
| Baby Tracker® - DailyChildcare Journal, ... | A friend of mine pinnedthis product on Pinte ... | 5.0 |
| Baby Tracker® - DailyChildcare Journal, ... | This has been an easy wayfor my nanny to record ... | 4.0 |
這份資料大致上有三個項目,分別是品名、評論、等級
接著我們想要建立自己的word count,把整條評論變成分詞,這樣才有助於我們做情緒分析
products['word_count'] = graphlab.text_analytics.count_words(products['review'])
products.head()
統計完之後,同樣可以透過head將其印出,我們可以看到word_count的欄位,他幫我們統計了每一個單字的數量
| name | review | rating | word_count | sentiment |
|---|---|---|---|---|
| Planetwise Wipe Pouch | it came early and was notdisappointed. i love ... | 5.0 | {'and': 3, 'love': 1,'it': 2, 'highly': 1, ... | 1 |
| Annas Dream Full Quiltwith 2 Shams ... | Very soft and comfortableand warmer than it ... | 5.0 | {'and': 2, 'quilt': 1,'it': 1, 'comfortable': ... | 1 |
| Stop Pacifier Suckingwithout tears with ... | This is a product wellworth the purchase. I ... | 5.0 | {'ingenious': 1, 'and':3, 'love': 2, ... | 1 |
| Stop Pacifier Suckingwithout tears with ... | All of my kids have criednon-stop when I tried to ... | 5.0 | {'and': 2, 'parents!!':1, 'all': 2, 'puppet.': ... | 1 |
| Stop Pacifier Suckingwithout tears with ... | When the Binky Fairy cameto our house, we didn't ... | 5.0 | {'and': 2, 'this': 2,'her': 1, 'help': 2, ... | 1 |
| A Tale of Baby's Dayswith Peter Rabbit ... | Lovely book, it's boundtightly so you may no ... | 4.0 | {'shop': 1, 'noble': 1,'is': 1, 'it': 1, 'as': ... | 1 |
| Baby Tracker® - DailyChildcare Journal, ... | Perfect for new parents.We were able to keep ... | 5.0 | {'and': 2, 'all': 1,'right': 1, 'when': 1, ... | 1 |
| Baby Tracker® - DailyChildcare Journal, ... | A friend of mine pinnedthis product on Pinte ... | 5.0 | {'and': 1, 'help': 1,'give': 1, 'is': 1, ' ... | 1 |
| Baby Tracker® - DailyChildcare Journal, ... | This has been an easy wayfor my nanny to record ... | 4.0 | {'journal.': 1, 'nanny':1, 'standarad': 1, ... | 1 |
| Baby Tracker® - DailyChildcare Journal, ... | I love this journal andour nanny uses it ... | 4.0 | {'all': 1, 'forget': 1,'just': 1, 'food': 1, ... | 1 |
將著我們可以先來看看產品的某一例,比如
products['name'].show()
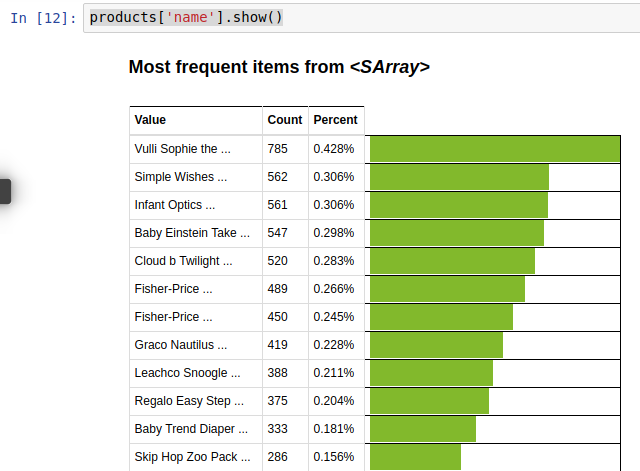
從中你可以發現,得到最多評論的產品是Vulli Sophie
同樣我們可以透過show()將評等視覺化
# explore Vulli Sophie
giraffe_reviews = products[ products['name'] == 'Vulli Sophie the Giraffe Teether']
#785
len(giraffe_reviews)
giraffe_reviews['rating'].show(view='Categorical')
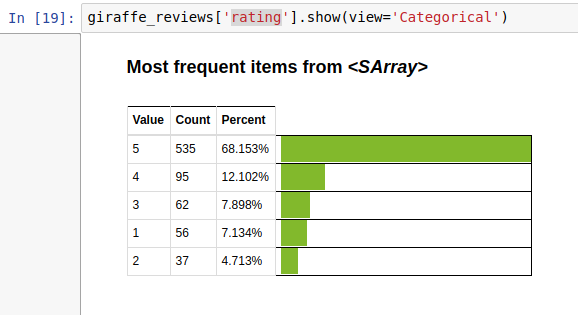
直觀來看我們可以發現,這像產品的評價是不錯的,原因是其5顆星的評等遠高於其他
回顧一下上面的圖表,這像產品沒有"讚"與"爛"的標籤,它是一種光譜,而不是一種二元的對立
因此這時候我們就要做出一點取捨,我們假設5跟4都代表著正向的情緒而1跟2代表負面
至於3我們先將他撇除因為我認為3顆星代表著不好不壞(當然你可以嚴格一點,這邊我只是想展示當你想把某個區間的評價消除可以怎麼做)
# build a sentiment classifiers
# ignore all 3* reviews
products = products[products['rating'] != 3]
# positive sentiment = 4* or 5* reviews
products['sentiment'] = products['rating'] >= 4
products.head()
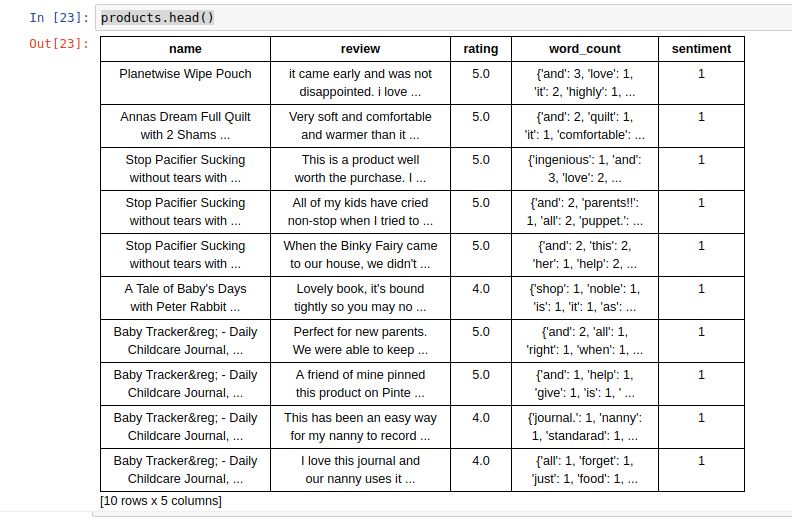
此時在檢視一次會發現多了一個sentiment的欄位了(1為正向、0為負面)
我們必須分兩步驟來實現這個classifier
這個範例中我們呼叫的是logistic_classifier(邏輯回歸),但事實上還有Decision Trees(決策樹)、Support Vector Machine(支持向量機) 這兩種方法,這將會在之後討論
在 logistic classifier 中除了要給 train_data 外還要輸入 train 的目標還有 features,再將測試集輸入到validation_set,最後就可以得到訓練的結果
# 80% train set 20% test set
train_data,test_data = products.random_split(.8,seed=0)
sentiment_model = graphlab.logistic_classifier.create(train_data,
target = 'sentiment',
features = ['word_count'],
validation_set=test_data)
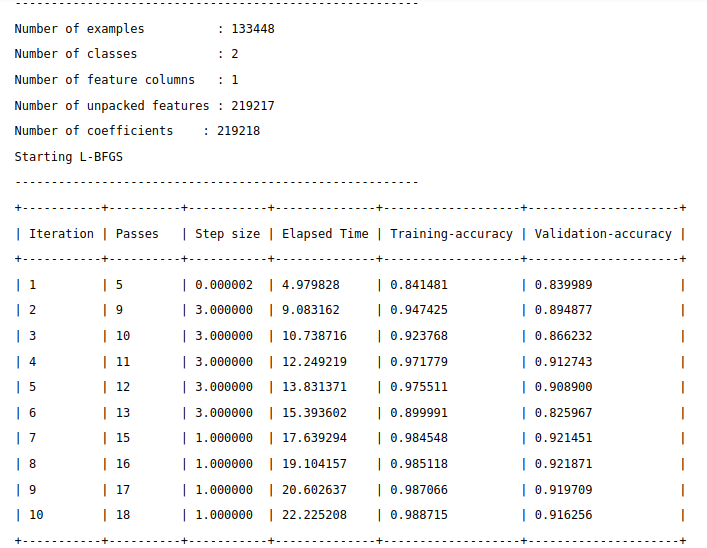
從圖表中可以很清楚看到,就結果來說Training-accuracy越來越趨近1(越來越好)
接著我們要來評估我們的情感分析模組
還記得之前提到的False negative 與 False positive 嗎?
ROC curve 就是專門用來針對confusion matrix中的 False negative 與 False positive
# evaluate the sentiment model use roc curve
sentiment_model.evaluate(test_data,metric='roc_curve')
# Data Visualization
sentiment_model.show(view='Evaluation')
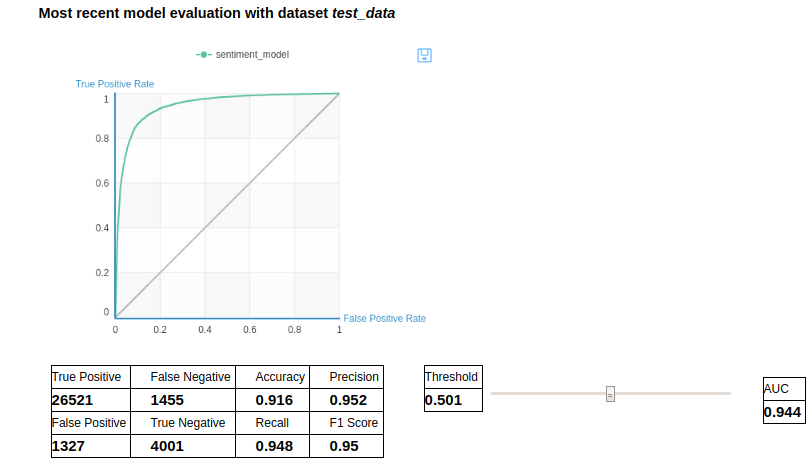
ROC curve 的圖表隱含著的是對 True Positive 與 False Positive 的取捨
| Predicted label + | Predicted label - | |
|---|---|---|
| True label + | True Positive | False Negative |
| True label - | False Negativ | True Negativ |
我們可以看到當中的 True Positive 與 True Negativ 資料非常的不平衡,總體精確率為91.1%
接下來我想用我的訓練好的模組來分析我 giraffe ,這邊有一點要注意,還記得前面提到的嗎?若要夠精確就必須將結果加上機率才行,所以 output_type 要設為 probability
# Applying the learned model to understand sentiment for giraffe
giraffe_reviews['predicted_sentiment'] = sentiment_model.predict(giraffe_reviews,output_type='probability')
giraffe_reviews.head()
| name | review | rating | word_count | predicted_sentiment |
|---|---|---|---|---|
| Vulli Sophie the GiraffeTeether ... | He likes chewing on allthe parts especially the ... | 5.0 | {'and': 1, 'all': 1,'because': 1, 'it': 1, ... | 0.999513023521 |
| Vulli Sophie the GiraffeTeether ... | My son loves this toy andfits great in the diaper ... | 5.0 | {'and': 1, 'right': 1,'help': 1, 'just': 1, ... | 0.999320678306 |
| Vulli Sophie the GiraffeTeether ... | There really should be alarge warning on the ... | 1.0 | {'and': 2, 'all': 1,'would': 1, 'latex.': 1, ... | 0.013558811687 |
| Vulli Sophie the GiraffeTeether ... | All the moms in my moms'group got Sophie for ... | 5.0 | {'and': 2, 'one!': 1,'all': 1, 'love': 1, ... | 0.995769474148 |
| Vulli Sophie the GiraffeTeether ... | I was a little skepticalon whether Sophie was ... | 5.0 | {'and': 3, 'all': 1,'months': 1, 'old': 1, ... | 0.662374415673 |
| Vulli Sophie the GiraffeTeether ... | I have been reading aboutSophie and was going ... | 5.0 | {'and': 6, 'seven': 1,'already': 1, 'love': 1, ... | 0.999997148186 |
| Vulli Sophie the GiraffeTeether ... | My neice loves her sophieand has spent hours ... | 5.0 | {'and': 4, 'drooling,':1, 'love': 1, ... | 0.989190989536 |
| Vulli Sophie the GiraffeTeether ... | What a friendly face!And those mesmerizing ... | 5.0 | {'and': 3, 'chew': 1,'be': 1, 'is': 1, ... | 0.999563518413 |
| Vulli Sophie the GiraffeTeether ... | We got this just for myson to chew on instea ... | 5.0 | {'chew': 2, 'seemed': 1,'because': 1, 'about.': ... | 0.970160542725 |
| Vulli Sophie the GiraffeTeether ... | My baby seems to likethis toy, but I could ... | 3.0 | {'and': 2, 'already': 1,'some': 1, 'it': 3, ... | 0.195367644588 |
我們可以看到模組將每個預測中都增加了機率
接著如果我們想要知道給予負面評價的人都怎麼說?如果要視覺化呈現我們透過排序的方式,然後將 ascending 設為即可看到從負評開始的排列
# sort the reviews based on the predicted sentiment
giraffe_reviews = giraffe_reviews.sort('predicted_sentiment',ascending=False)
giraffe_reviews.head()
最後我們也可以透過存取 review 欄位來更細緻看看評論到底寫些什麼?
giraffe_reviews[0]['review']


