基本上檢索文件的方法,只是收集所有文章快速瀏覽並從中挑出最符合我們標準的那一個
但我們可能也對其他問題感興趣比如對相關聯的文章進行 clustering ,你可能可以得到一群體育、一群時事...等文章
而若我們使用這個方法建構我們的詞料庫,那當有人讀到一篇體育相關的文章,我們就能快速查找所有體育相關的文章
然而挑戰在於不像蘋果日報,已經幫你分好時事、體育...等
現在的情況是,我們只有一些文章而我們打算找出其潛在分類的方法
所以我們要做的就是對文章進行分組或 clusters 就像先前說的我們將他分成體育、時事...等
假設已經有人提供給我們標籤,也就是那個人讀完所有的文章並且一一分門別類貼上標籤,總之我們會有一組標誌好的文章
在這情況下,當我們拿出待查詢的文章,並把它放入分類中,這不過就是分類問題,我們面對只是監督式學習問題
我們現在假設沒預設標籤,而我們打算推斷出相關文章的分組也就是 clusters
圖中的每一個點是我們輸入的字數向量,為了簡化問題,這邊只討論兩個詞,假設我們有一個向量,分別包含單字1與單字2
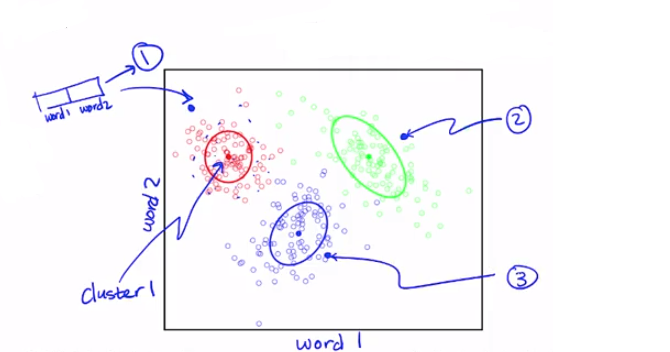
X軸為word1、Y軸為word2(通常我們會有一個很大的詞彙表,所以真實的情況應該會是一個高維度的圖形)
它會輸出 clusters 的標籤,以此圖為例總共分成三群,最後可以做的是事後的回朔,來看這個 clusters 所包含的文章,並且將之標籤化(體育類、時事類...)
這僅僅是一個非監督學習的例子,我們不需要給定任何的標籤,我們僅僅從觀測量本身去歸納出其結構
那接著我們要問的是,是怎樣去定義一個 clusters ?
每個 clusters 都有一個中心,我們以X表示,也會形成某種形狀,當我們考慮某一個觀測點時(以下圖為例)
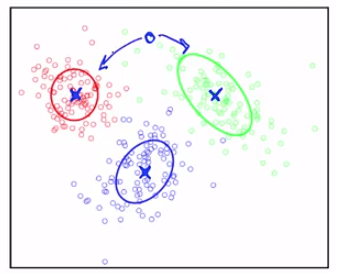
它該是紅色或綠色,這其實根據的是我們 clusters 的形狀,來考慮這篇文章跟那篇有多相近?
所以我們為觀測點評分,評分標準是 clusters 的中心及形狀
但是如果以 clusters 中心來判斷在這個例子裡面將變得很難判斷
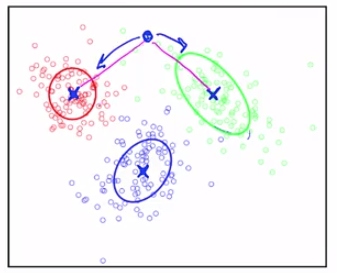
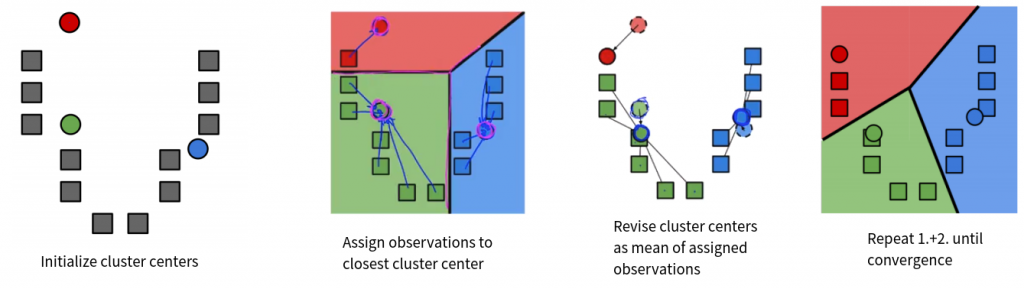
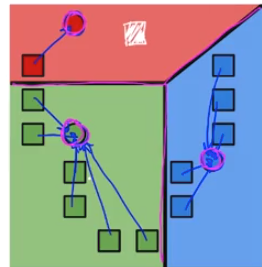
我們來看一個 clusters 的演算法,它的標準是只看與 clusters 中心的距離,它的名字叫做 k-means
它是以最終將得到k個 clusters 的假設出發,也就是說你要提前給定最終 clusters 的數量