Other examples of clustering
我們已經討論完分群與相似度的概念,這邊將再舉出一些例子
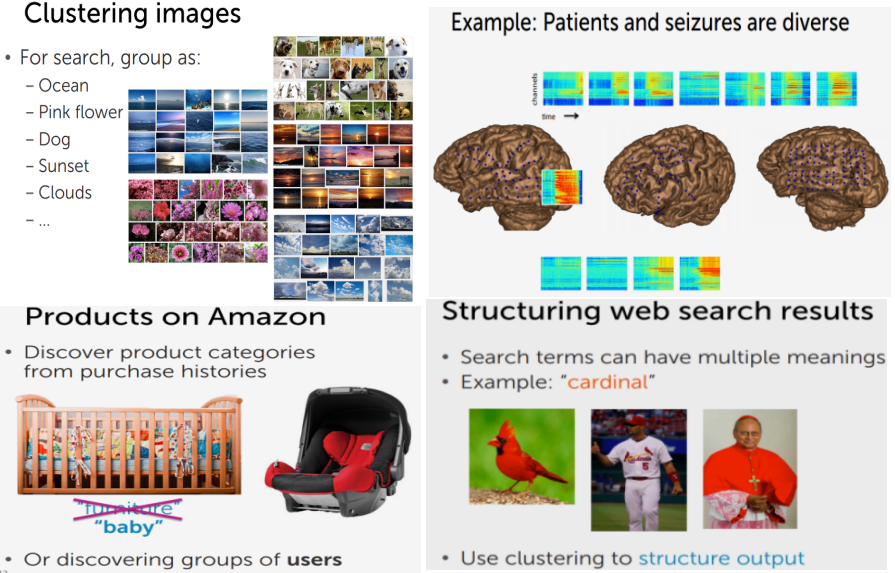
- 圖片搜尋:當你上了Google圖片搜尋,你搜尋了某些關鍵字,它運用這點把照片分類並標籤
- 病況分類:以癲癇為例,我們將其發作病情紀錄進行 clusters ,若可以因此而得出不同的發作病因,就可以更好的對症下藥
- 購物推薦:假設亞馬遜上有些第三方賣家,他們會發布產品並標籤屬性(把嬰兒床標籤為家具),但若從買家角度來看,從他的購物紀錄出發與其他購買紀錄相似的消費者,這個消費者也買了嬰兒車,因此我們可以透過 clusters 將其作為推薦並重新修改標籤為"嬰兒用品"
- 網頁搜尋:當我搜尋"cardinal",可能聖路易紅雀隊或關於紅衣樞機的新聞
另一個有意思的例子是,想一想社區的集合,若我們要估計一個房子的價格,這是一個相當小的地區
在這種情況下,我們只有很少的房子出售訊息,甚至很多時候是沒有的
所以這時候難的是,因為我們幾乎沒有參考點了
此時我們就可以查找,是否有其他地區有相似的房產,這樣我們還是可以較精準的估計其價格,即便在原社區資料很少或幾乎沒有
這樣的解決方法是,我們將有相似趨勢的區域做 clustering ,然後在 cluster 內分享訊息
這個識別相關區域的點子,甚至可以拿來預測犯罪率以最佳化警力的配置
Clustering and similarity ML block diagram
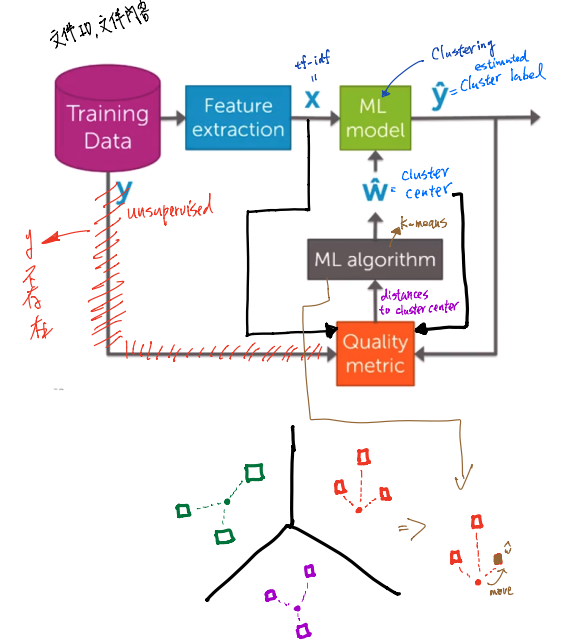
- training data:文件編號、文件內容表
- 使用 tf-idf 來提取特徵量
- 透過 Clustering model 產生預測的 Clustering 標籤(ŷ)
- 我們並沒有一個可以拿來比較的標籤,因為是非監督式學習,所以y並不存在
- 我們該如何評估 Clustering 的精確度呢?答案是 Voronoi tessellation
- 我們要評估的判準為 Clustering 的一致性,每個觀測點到 Clustering center 的距離,越小越好
- 所以我們需要 tf-idf 的資料及 Clustering center 用這兩個來取代真實資料
- 經由 Quality metric 來得到 Clustering center 與每個觀測點的距離
- 最後透過 k-means 來更新 Clustering center
Reference:


